sklearn转换器和评估器
说到评估器与转换器,大家可能没有一个直观的认识。事实上,基本上大部分的分类器都属于评估器.
这里面类汇总,第一个为基础评估器,第二个为基础分类器,最后一个为基础转换器。基本上所有的评估器与转换器都有三个基本方法,fit,transform,fit_transform。
fit、transform与fit_transform的区别
其实程序员最应去的一个地方就是Stackoverflow,那里有最权威、最清楚的Bug调试解决方案。虽然大部分都是英语,但是英语解释的比较确切。
fit原义指的是安装、使适合的意思,其实有点train的含义但是和train不同的是,它并不是一个训练的过程,而是一个适配的过程,过程都是定死的,最后只是得到了一个统一的转换的规则模型。
transform则指的是转换.。从可利用信息的角度来说,转换分为无信息转换和有信息转换。无信息转换是指不利用任何其他信息进行转换,比如指数、对数函数转换等。有信息转换从是否利用目标值向量又可分为无监督转换和有监督转换。无监督转换指只利用特征的统计信息的转换,统计信息包括均值、标准差、边界等等,比如标准化、PCA法降维等。有监督转换指既利用了特征信息又利用了目标值信息的转换,比如通过模型选择特征、LDA法降维等。
而fit_transform方法则是把上述2个过程统一起来,对模型先训练,然后根据输入的训练数据返回一个转换矩阵。这个过程通常只存在训练过程中。
转换器
想一下之前做的特征工程的步骤?
- 1 实例化 (实例化的是一个转换器类(Transformer))
- 2 调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
我们把特征工程的接口称之为转换器,其中转换器调用有这么几种形式
- fit_transform
- fit
- transform
这几个方法之间的区别是什么呢?我们看以下代码就清楚了
In [1]: from sklearn.preprocessing import StandardScaler
In [2]: std1 = StandardScaler()
In [3]: a = [[1,2,3], [4,5,6]]
In [4]: std1.fit_transform(a)
Out[4]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
In [5]: std2 = StandardScaler()
In [6]: std2.fit(a)
Out[6]: StandardScaler(copy=True, with_mean=True, with_std=True)
In [7]: std2.transform(a)
Out[7]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
从中可以看出,fit_transform的作用相当于transform加上fit。但是为什么还要提供单独的fit呢, 我们还是使用原来的std2来进行标准化看看
fit_transform = fit + transform
fit:计算平均值,计算标准差
transform:根据fit步骤计算出的转换参数,去转换特征
In [8]: b = [[7,8,9], [10, 11, 12]]
In [9]: std2.transform(b)
Out[9]:
array([[3., 3., 3.],
[5., 5., 5.]])
In [10]: std2.fit_transform(b)
Out[10]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
评估器(sklearn机器学习算法的实现)
在sklearn中,评估器(estimator)也叫估计器是一个重要的角色,是一类实现了算法的API,也就是机器学习算法的载体
- 1 用于分类的估计器:
- sklearn.neighbors k-近邻算法
- sklearn.naive_bayes 贝叶斯
- sklearn.linear_model.LogisticRegression 逻辑回归
- sklearn.tree 决策树与随机森林
- 2 用于回归的估计器:
- sklearn.linear_model.LinearRegression 线性回归
- sklearn.linear_model.Ridge 岭回归
- 3 用于无监督学习的估计器
- sklearn.cluster.KMeans 聚类
估计器工作流程
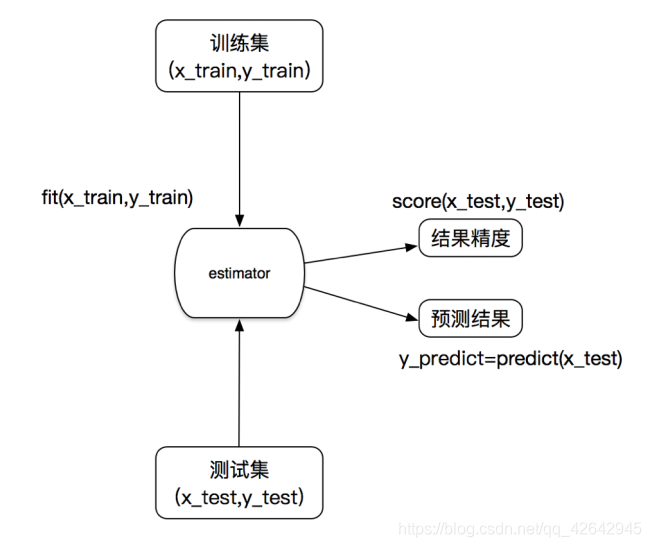
fit:训练,用的是(x_train,y_train)
score:评估准确率,用的是测试集
predict:预测
- sklearn.cluster.KMeans 聚类