sklearn初探
机器学习的本质就是借助数学模型理解数据。当我们给模型装上可以适应观测数据的可调参数时,学习就开始了,此时的程序被认为具有从数据中“学习”的能力。一旦模型可以拟合旧的观测数据,那么它们就可以预测并解释新的观测数据。
目前,python有不少可以实现各种机器学习算法的程序库。Scikit-Learn是最流行的程序包之一,它为各种常见机器学习算法提供了高效版本。Scikit-Learn不仅因其干净、统一、管道命令式的API而独具特色,而且它的在线文档又实用、有完整。这种统一的好处是,只要你掌握了Scikit-Learn一种模型的基本用法和语法,就可以非常平滑的过渡到新的模型或算法上。
Scikit-Learn 的评估器(Estimator)API的特点
统一性
所有对象使用共同的接口连接一组方法和统一的文档
内省
所有参数值都有公共属性
限制对象层级
只有算法可以用Python类表示。数据集都用标准数据类型(Numpy数组、Pandas DataFrame、Scipy稀疏矩阵)表示,参数名称用标准的python字符串。
函数组合
许多机器学习任务都可以用一串基本算法实现,Scikit-Learn尽力支持这种可能。
明智的默认值
当模型需要用户设置参数时,Scikit-Learn预先定义适当的默认值
使用Scikit-Learn评估器API的常规步骤
- 通过从Scikit-Learn中导入适当的评估器,选择模型类
- 用合适的数值对模型类进行实例化,配置模型超参数(hyperparameter)
- 整理数据,获取特征矩阵(Xtrain)和目标数组(target)
- 调用模型实例的fit() 方法对数据进行拟合
- 对新数据应用模型:
- 在有监督学习模型中,通常使用predict() 方法预测新数据的标签
- 再无监督的学习模型中,通常使用transform() 或predict() 方法转换或者推断数据的性质
有监督学习——回归(regression)
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#创建数据
rng = np.random.RandomState(42)
x = 10 * rng.rand(50)
y = 2 * x + 1 + rng.randn(50)
#绘制散点图
plt.plot(x, y, 'oc')
# 1.导入线性回归模型类
from sklearn.linear_model import LinearRegression
# 2.实例化评估器(Estimator),设置超参数——要求拟合截距
model = LinearRegression(fit_intercept=True)
# 3.整理数据,获得特征矩阵(Xtrain)和目标数组(target)
X = x[:, np.newaxis] #将x变为nx1的二维数组
# 4.调用模型实例的fit()对数据进行拟合,即训练模型
model.fit(X, y)
# 5.对测试数据进行预测
x_test = np.linspace(-1,10,50).reshape(-1,1)
y_predict = model.predict(x_test)
#画图,查看拟合效果
plt.plot(x_test, y_predict)
plt.plot(x, y, 'oc')
有监督学习——分类
这里使用非常简单的高斯朴素贝叶斯(Gaussian naive Bayes)方法完成任务,这个方法假设每个特征中属于每一类的观测值都符合高斯分布。高斯朴素贝叶斯方法速度很快而且不需要参数。
#从seaborn库中导入数据
import seaborn as sns
from sklearn.cross_validation import train_test_split
data = sns.load_dataset('iris')
# 1.导入高斯朴素贝叶斯模型类
from sklearn.naive_bayes import GaussianNB
# 2.实例化评估器
model = GaussianNB()
# 3.整理数据,获得特征矩阵(Xtrain)和目标数组(target)
x_data = data.drop('species', axis=1)
y_data = data.species
#从原始数据中分离出训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, random_state=1)
# 4.调用模型实例的fit()对数据进行拟合,即训练模型
model.fit(x_train, y_train)
# 5.对测试数据进行预测
y_predict = model.predict(x_test)
#计算分类成功率
from sklearn.metrics import accuracy_score
accuracy_score(y_predict, y_test)
#输出结果:
Out[14]: 0.9736842105263158无监督学习——降维
同样以鸢尾花为例,对鸢尾花降维能够更方便的对数据进行可视化。鸢尾花数据集由四个维度构成,即每个样本有四个维度。降维的任务是找到一个可以保留数据本质特征的低维矩阵来表示高维数组。降维通常用于辅助数据可视化的工作,毕竟用二维数据画图比用四维甚至更高的数据画图方便。
下面将使用主要成分分析(PCA)方法,这是一种快速线性降维技术。我们将用模型返回两个主成份,也就是用二维数据表示鸢尾花的四维数据。
# 1.导入PCA模型类
from sklearn.decomposition import PCA
# 2.实例化评估器,设置超参数——降维后的维度
model = PCA(n_components=2)
# 3.这里的数据整理,使用x_data,不使用y变量
# 4.调用模型实例的fit()对数据进行拟合,即训练模型
model.fit(x_data)
# 5.使用模型的transform接口对数据降维
x_2d = model.transform(x_data)
#可视化
data['pca1'] = x_2d[:, 0]
data['pca2'] = x_2d[:, 1]
sns.lmplot('pca1', 'pca2', hue='species', data=data, fit_reg=False)
从二维数据表示图中可以看出,虽然PCA算法根本不知道花的种类标签,但不同种类的花还是很清晰地区分出来!这表明用一种比较简明的分类方法能够有效的学习这份数据。
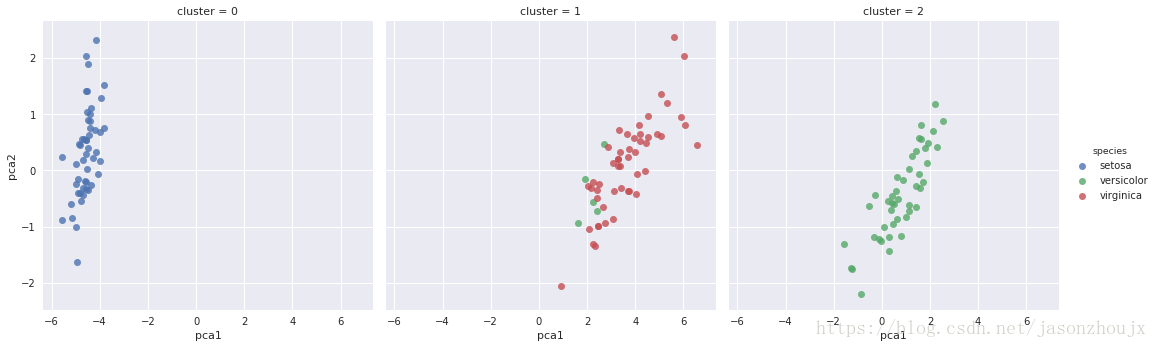
无监督学习——聚类
聚类算法是要对没有任何标签的数据集进行分组。我们将用一种强大的聚类方法——高斯混合模型(GMM)进行聚类。GMM模型试图将数据构造成若干服从高斯分布的概率密度函数簇。
# 1.导入GMM模型类
from sklearn.mixture import GMM
# 2.实例化评估器,设置超参数初始化模型
model = GMM(n_components=3, covariance_type='full')
# 3.数据使用x_data,不使用y变量
# 4.调用模型实例的fit()对数据进行拟合,即训练模型
model.fit(x_data)
# 5.确定簇标签
y_gmm = model.predict(x_data)
#可视化
data['cluster'] = y_gmm
plt.lmplot('pca1', 'pca2', data=data, hue='species', col='cluster', fit_reg=False)