一、转换器
回想一下之前做的特征工程的步骤
1、实例化(实例化的是一个转换器类(Transformer)
2、调用fit-transform(对于文档建立分类词频矩阵,不能同时调用)
fit_transform()就是先fit(输入数据),再transform(转换数据)
举个例子:
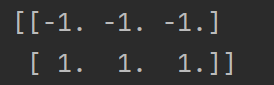
from sklearn.preprocessing import StandardScaler
s = StandardScaler()
data = s.fit_transform([[1, 2, 3], [4, 5, 6]])
print(data)
StandardScaler()是一个归一化的类,运行结果为:
如果程序改写成这样:
ss = StandardScaler()
print(ss.fit([[1, 2, 3], [4, 5, 6]]))
print(ss.transform([[1, 2, 3], [4, 5, 6]]))
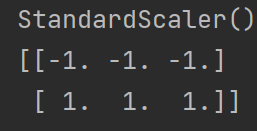
程序运行结果是一样的
但是如果程序是这样的:
sss = StandardScaler()
print(sss.fit([[27, 23, 35], [44, 54, 6]]))
print(sss.transform([[1, 2, 3], [4, 5, 6]]))
结果就会变成:

出现这种情况的原因是因为,在数据fit的过程中,系统会记录并计算这组数据的信息,在该案例中数据进行标准化,会记录数据的平均值以及方差,然而使用另一组数据进行transform时,系统会利用刚刚fit的平均值和方差计算。
因此在我们自己敲代码的时候,直接调用fit_transform即可
二、估计器
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API
1、用于分类的估计器:
sklearn.neighbors k-近邻算法
sklearn.naive_bayes 贝叶斯
sklearn.linear_model.LogisticRegression 逻辑回归
2、用于回归的估计器:
sklearn.linear_model.LinearRegression 线性回归
.sklearn.linear_model.Ridge 岭回归
具体的使用后续介绍