sklearn转换器和估计器
转挨器- - - - 特征工程父类
1、类例化(实例化的是一个转换器类(Transformer))
2、调用fit_transform(对于文稍建立分类词频矩阵,不能同时调用)
案例说明 标准化:(x-mean)/std
fit_transform()
fit()计算每一列的平均值、标准差
transform()(x-mean)/std进行最终的转换
# 案例:标准化处理(转化为均值为0,标准差为1 附近的值)
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler #归一化库
# 1.获取数据
df = pd.read_csv(r"E:\Normalization.txt",sep=" ",encoding="utf-8")
display(df.sample(3))
x = df.iloc[:,:3]
#display(x.head(3))
#2.实例化一个转换器类
transfer = StandardScaler() #实例化一个转换器类
#3.#调用fit_transform()
xi = transfer.fit_transform(x) #调用fit_transform()
#print(xi)
#4、转化为二维表
data = pd.DataFrame(xi,columns=x.columns)
data["y"] = df['y']
display(data.tail(3))
| x1 | x2 | x3 | y | |
|---|---|---|---|---|
| 5 | 220 | 32 | 3200 | 1 |
| 4 | 201 | 30 | 3000 | 1 |
| 7 | 224 | 31 | 3680 | 1 |
| x1 | x2 | x3 | y | |
|---|---|---|---|---|
| 5 | 0.900299 | 1.294915 | 0.521933 | 1 |
| 6 | 1.046294 | 0.554964 | 0.633577 | 1 |
| 7 | 1.094959 | 1.048265 | 1.593710 | 1 |
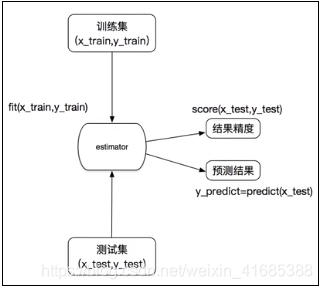
估计器(estinator)- - - -sklearn机器学习算法父类
估计器(sklearn机器学习算法的实现》
1、实例化一个estimator
2、estinator.fit(xtrain,y_train)计算一词用完毕,模型生成
3、模账评估:
1)直接比对真实值和预测值
y_predict= estimator.predict(x_test)
y_test == y_predict:比对True和False的数量
2)计算案确率
accuracy=estimator.score(x_test,y_test)