文章目录
Premade Estimators
该文档将介绍 TensorFlow 的编程环境,并会向你展示如何使用 TensorFlow 解决 Iris 分类问题。
前置要求
你需要先做如下几件事,才能够使用本文档的样例代码:
- 安装 TensorFlow
- 如果你在 virtualenv 或者 Anaconda 上安装了 TensorFlow,启动你的 TensorFlow 环境。
- 通过以下命令安装或升级 pandas:
pip install pandas
获取样例代码
通过以下几步来获得我们将要使用的样例代码:
- 通过键入以下命令从 GitHub 下载 TensorFlow Models 仓库:
git clone https://github.com/tensorflow/models
- 进入含有样例的文件夹:
cd models/samples/core/get_started/
我们在本文档中将使用的程序是
premade_estimator.py.
这个程序使用
iris_data.py
来获取训练数据。
运行程序
运行 TensorFlow 的程序和运行其他的 Python 程序方法一样。例如
python premade_estimator.py
程序将会输出一些训练日志,还有一些对测试集的预测结果。例如,下列输出的第一行显示出,模型认为测试集中的第一个例子为 Setosa 的概率为 99.6%。由于测试集中确实为 Setosa,这表示此次预测表现不错。
...
Prediction is "Setosa" (99.6%), expected "Setosa"
Prediction is "Versicolor" (99.8%), expected "Versicolor"
Prediction is "Virginica" (97.9%), expected "Virginica"
D:\Yolov3_Tensorflow\python\python.exe D:/20200123_华为笔记本_pycharm测试项目/202002010_创建定制化estimator/models/samples/core/get_started/premade_estimator.py
INFO:tensorflow:Using default config.
WARNING:tensorflow:Using temporary folder as model directory: C:\Users\HuaWei\AppData\Local\Temp\tmp9e1xbuw_
INFO:tensorflow:Using config: {'_model_dir': 'C:\\Users\\HuaWei\\AppData\\Local\\Temp\\tmp9e1xbuw_', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: ONE
}
}
, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x000001F2C929B160>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Create CheckpointSaverHook.
INFO:tensorflow:Graph was finalized.
2020-02-10 22:48:31.934578: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
2020-02-10 22:48:32.649107: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1411] Found device 0 with properties:
name: GeForce MX250 major: 6 minor: 1 memoryClockRate(GHz): 1.582
pciBusID: 0000:01:00.0
totalMemory: 2.00GiB freeMemory: 1.62GiB
2020-02-10 22:48:32.649448: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1490] Adding visible gpu devices: 0
2020-02-10 22:48:33.621053: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-02-10 22:48:33.621228: I tensorflow/core/common_runtime/gpu/gpu_device.cc:977] 0
2020-02-10 22:48:33.621328: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0: N
2020-02-10 22:48:33.621546: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1103] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1374 MB memory) -> physical GPU (device: 0, name: GeForce MX250, pci bus id: 0000:01:00.0, compute capability: 6.1)
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Saving checkpoints for 0 into C:\Users\HuaWei\AppData\Local\Temp\tmp9e1xbuw_\model.ckpt.
INFO:tensorflow:loss = 104.19969, step = 0
INFO:tensorflow:global_step/sec: 276.161
INFO:tensorflow:loss = 37.975826, step = 100 (0.364 sec)
INFO:tensorflow:global_step/sec: 334.223
INFO:tensorflow:loss = 22.292067, step = 200 (0.298 sec)
INFO:tensorflow:global_step/sec: 341.768
INFO:tensorflow:loss = 17.565737, step = 300 (0.292 sec)
INFO:tensorflow:global_step/sec: 337.602
INFO:tensorflow:loss = 14.672792, step = 400 (0.297 sec)
INFO:tensorflow:global_step/sec: 359.38
INFO:tensorflow:loss = 10.606393, step = 500 (0.278 sec)
INFO:tensorflow:global_step/sec: 351.815
INFO:tensorflow:loss = 7.5208006, step = 600 (0.284 sec)
INFO:tensorflow:global_step/sec: 346.946
INFO:tensorflow:loss = 9.5241785, step = 700 (0.288 sec)
INFO:tensorflow:global_step/sec: 361.976
INFO:tensorflow:loss = 8.364717, step = 800 (0.276 sec)
INFO:tensorflow:global_step/sec: 345.748
INFO:tensorflow:loss = 8.853266, step = 900 (0.289 sec)
INFO:tensorflow:Saving checkpoints for 1000 into C:\Users\HuaWei\AppData\Local\Temp\tmp9e1xbuw_\model.ckpt.
INFO:tensorflow:Loss for final step: 10.949549.
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2020-02-10-14:48:37
INFO:tensorflow:Graph was finalized.
2020-02-10 22:48:37.650667: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1490] Adding visible gpu devices: 0
2020-02-10 22:48:37.650864: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-02-10 22:48:37.651021: I tensorflow/core/common_runtime/gpu/gpu_device.cc:977] 0
2020-02-10 22:48:37.651141: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0: N
2020-02-10 22:48:37.651427: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1103] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1374 MB memory) -> physical GPU (device: 0, name: GeForce MX250, pci bus id: 0000:01:00.0, compute capability: 6.1)
INFO:tensorflow:Restoring parameters from C:\Users\HuaWei\AppData\Local\Temp\tmp9e1xbuw_\model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Finished evaluation at 2020-02-10-14:48:37
INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.96666664, average_loss = 0.084238075, global_step = 1000, loss = 2.5271423
Test set accuracy: 0.967
INFO:tensorflow:Saving 'checkpoint_path' summary for global step 1000: C:\Users\HuaWei\AppData\Local\Temp\tmp9e1xbuw_\model.ckpt-1000
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
2020-02-10 22:48:38.023873: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1490] Adding visible gpu devices: 0
2020-02-10 22:48:38.024076: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-02-10 22:48:38.024234: I tensorflow/core/common_runtime/gpu/gpu_device.cc:977] 0
2020-02-10 22:48:38.024332: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0: N
2020-02-10 22:48:38.024488: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1103] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 1374 MB memory) -> physical GPU (device: 0, name: GeForce MX250, pci bus id: 0000:01:00.0, compute capability: 6.1)
INFO:tensorflow:Restoring parameters from C:\Users\HuaWei\AppData\Local\Temp\tmp9e1xbuw_\model.ckpt-1000
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
Prediction is "Setosa" (99.8%), expected "Setosa"
Prediction is "Versicolor" (99.5%), expected "Versicolor"
Prediction is "Virginica" (92.3%), expected "Virginica"
Process finished with exit code 0
如果程序出现报错,那么请自查如下问题:
- 你正确地安装 TensorFlow 了吗?
- 你使用的是正确版本的 TensorFlow 吗?
- 你启动安装了 TensorFlow 的环境了吗?(这条仅会出现在一些特定的安装方法中)
程序栈
在深入程序细节之前,让我们先了解一下程序的环境。如下所示,TensorFlow 提供了一个含有很多 API 层的程序栈:
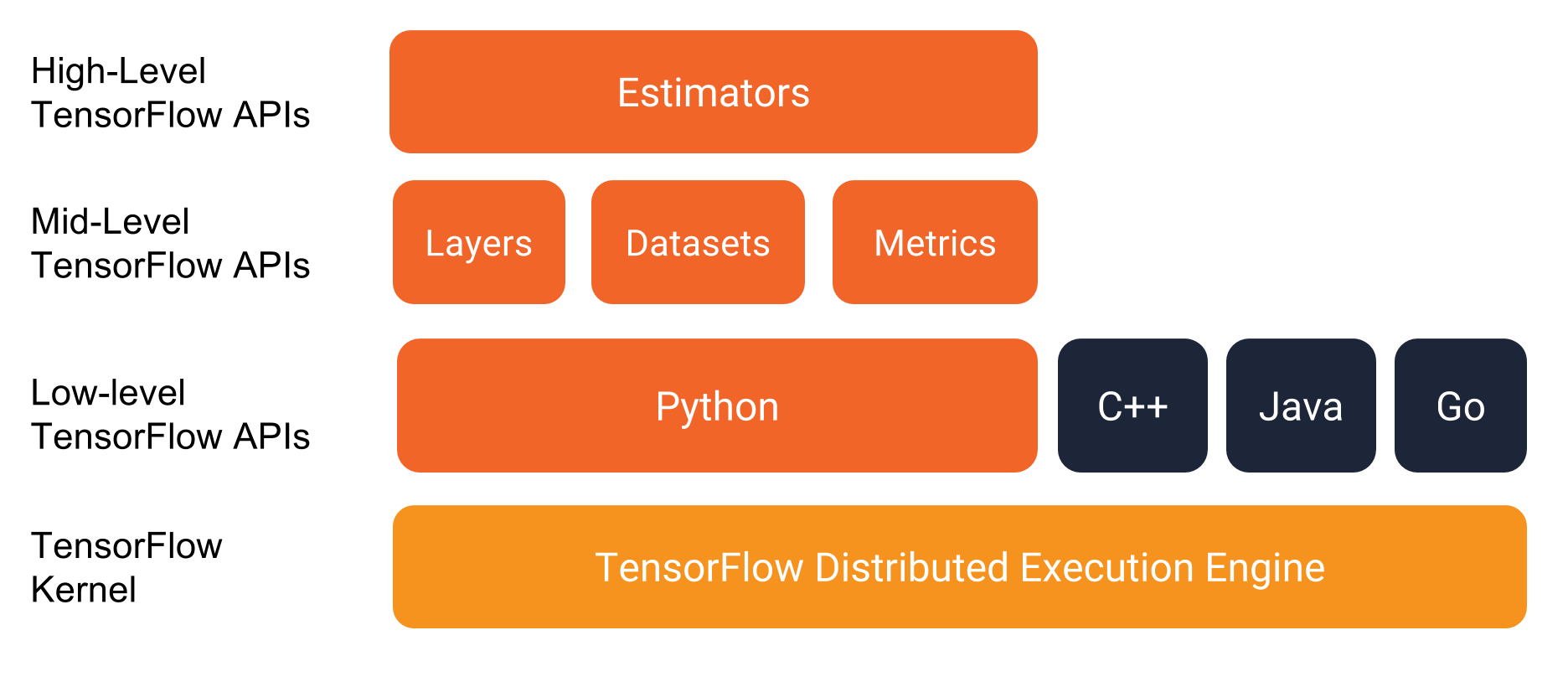
我们强烈建议使用如下 API 编写 TensorFlow 程序:
对 irises 分类:概览
本文档中的这个样例程序搭建并测试了一个模型,根据花的萼片和花瓣将 Iris 花分成不同种类。

从左至右为
Iris setosa (by Radomil, CC BY-SA 3.0),
Iris versicolor (by Dlanglois, CC BY-SA 3.0),
and Iris virginica (by Frank Mayfield, CC BY-SA 2.0).
数据集
Iris 数据集包含四个特征和一个标签。四个特征定义了 Iris 花的植物特征:
- 花萼长度
- 花萼宽度
- 花瓣长度
- 花瓣宽度
我们的模型会用 float32 类型的数据来表示这些特征。
标签表明了 Iris 的种类,必须为以下一种:
- Iris setosa (0)
- Iris versicolor (1)
- Iris virginica (2)
我们的模型会用 int32 类型的数据来表示这些标签。
下面的表格显示了数据集中的三个例子:
| 花萼长度 | 花萼宽度 | 花瓣长度 | 花瓣宽度 | 类别(标签) |
|---|---|---|---|---|
| 5.1 | 3.3 | 1.7 | 0.5 | 0 (Setosa) |
| 5.0 | 2.3 | 3.3 | 1.0 | 1 (versicolor) |
| 6.4 | 2.8 | 5.6 | 2.2 | 2 (virginica) |
算法
程序训练了一个深度神经网络分类模型,有着如下的拓扑结构:
- 2 个隐藏层。
- 每个隐藏层拥有 10 个节点。
下图展示了神经网络中的特征,隐藏层和预测结果(隐藏层中的节点没有全部显示出来):

接口
在未标记的样例上运行一个训练好的模型,会产生三个预测,分别是该花朵分别属于三种 Iris 类别的概率。这三个预测值的和为 1.0。例如,对一个未标记的样例的预测可能如下所示:
- Iris Setosa 的可能性为 0.03
- Iris Versicolor 的可能性为 0.95
- Iris Virginica 的可能性为 0.02
这个预测意味着所给的未标记样例有 95% 的概率为 Iris Versicolor 品种。
使用 Estimators 编程的概览
要写出一个基于预制的 Estimator 的 TensorFlow 程序,你可以进行如下任务:
- 创建一个或多个输入函数。
- 定义模型的特征列。
- 实例化一个 Estimator,定义特征列和各类超参数。
- 在 Estimator 对象上调用一个或多个方法,传入合适的输入函数来作为数据源。
让我们看看这些任务是如何实现 Iris 分类的。
创建输入函数
你必须创建一个可以为训练,评估和预测提供数据提供支持的输入函数。
- features - 一个 Python 字典:
每个键为特征的名字。 每个值为一个包含所有该特征的值的数组。 - label - 一个数组包含着所有例子的标签 。
这里有一个输入函数的实现,来展示它的格式:
def input_evaluation_set():
features = {'SepalLength': np.array([6.4, 5.0]),
'SepalWidth': np.array([2.8, 2.3]),
'PetalLength': np.array([5.6, 3.3]),
'PetalWidth': np.array([2.2, 1.0])}
labels = np.array([2, 1])
return features, labels
你的输入函数可以通过任意的方法来生成 features 字典和 label 列表。不过,我们推荐使用 TensorFlow 的 Dataset API,它可以处理所有种类的数据。从高层次看,Dataset API 包含了如下的类:
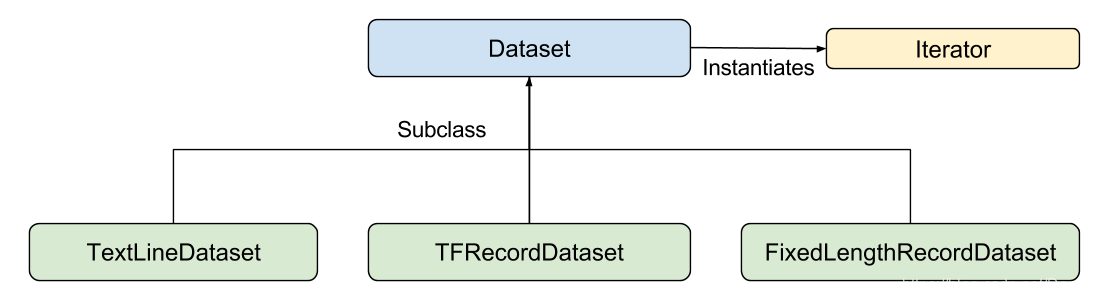
其中,单独的成员为:
- Dataset - 包含创建和传输数据集的基类。同时也允许你通过内存中的数据来初始化数据集,或从一个 Python 生成器。
- TextLineDataset - 从文本文件逐行读取
- TFRecordDataset - 从 TFRecord 文件读取记录
- FixedLengthRecordDataset - 从二进制文件读取固定大小的记录
- Iterator - 提供了一种每次获取数据集中的元素的方法
Dataset API 可以为你处理很多常见的情况。例如,使用它可以简单地从一系列巨大的文件中并行地读取记录并合成一个单个的流。
为了让这个例子简单易见,我们将会使用 pandas 来加载数据,并根据这个在内存中的数据来建立我们的输入管道。
这个是此程序训练中使用的输入函数,可以在iris_data.py找到。
def train_input_fn(features, labels, batch_size):
"""训练中使用的输入函数"""
# 将输入变为一个 Dataset
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# 打乱,重复并将样例分批次
return dataset.shuffle(1000).repeat().batch(batch_size)
定义特征列
对于 Iris 来说,4 个原始的特征为数值,所以我们将会建立一个特征列的列表来告诉 Estimator 模型,将四个特征分别表示为 32 位的浮点数值。因此,用于建立特征列的代码为:
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
如今我们有了如何让模型表示原始特征的定义,我们可以开始搭建 Estimator 了。
实例化一个 Estimator
Iris 问题是一个经典的分类问题。幸运的是,TensorFlow 提供了一些预制的 Estimator 分类器,包含:
对于 Iris 问题,tf.estimator.DNNClassifier 看起来是最佳选择。以下是我们如何实例化这个 Estimator:
# 创建一个有两个隐藏层和每层10个节点的 DNN
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# 两个隐藏层,每层 10 个节点。
hidden_units=[10, 10],
# 模型必须在 3 个类别中作出选择
n_classes=3)
训练,评估和预测
现在我们有了一个 Estimator 对象,我们可以调用方法来做如下事情:
- 训练模型
- 评估训练好的模型
- 使用训练好的模型进行预测
训练模型
像如下一样调用 Estimator 的 train 方法来训练模型:
# 训练模型
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size),
steps=args.train_steps)
这里我们将 input_fn 的调用包含在一个 lambda 中来在提供一个无参数的输入函数时获取 Estimator 所需的参数。steps 参数告诉方法要在一定数量的训练次数后停止训练。
评估训练好的模型
如今模型已被训练好,我们可以获得一些它的表现数据了。下面的代码片段评估了该模型在测试集上的准确率:
# 评估该模型
eval_result = classifier.evaluate(
input_fn=lambda:iris_data.eval_input_fn(test_x, test_y, args.batch_size))
print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))
与我们调用 train 方法不同,我们并不能将 steps 参数传给评估方法。我们的 eval_input_fn 仅产生了一次epoch(轮数) 的数据。
运行这段代码会产生如下的输出(或者类似的东西):
Test set accuracy: 0.967
通过训练好的模型进行预测
我们如今有了一个训练好的模型,而且能拥有不错的评估结果。我们现在可以使用训练好的模型,基于一些未标记的样例来预测 Iris 花朵的类型了。与训练和评估相同,我们进行预测时只需进行一次函数调用:
# 通过模型进行预测
expected = ['Setosa', 'Versicolor', 'Virginica']
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
predictions = classifier.predict(
input_fn=lambda:iris_data.eval_input_fn(predict_x,
batch_size=args.batch_size))
predict 方法返回了一个 Python 的可迭代类型,是一个含有每个例子的预测结果的字典。如下的代码打印出了一些预测和它们的可能性:
template = ('\nPrediction is "{}" ({:.1f}%), expected "{}"')
for pred_dict, expec in zip(predictions, expected):
class_id = pred_dict['class_ids'][0]
probability = pred_dict['probabilities'][class_id]
print(template.format(iris_data.SPECIES[class_id],
100 * probability, expec))
运行以上的代码会出现下面的结果:
...
Prediction is "Setosa" (99.6%), expected "Setosa"
Prediction is "Versicolor" (99.8%), expected "Versicolor"
Prediction is "Virginica" (97.9%), expected "Virginica"
总结
预制的 Estimator 是一个很有效的快速创建标准模型的方法。
现在如果你已经开始编写 TensorFlow 程序了,那么注意关注如下的资料:
