前言
确保已经搭建了集群,如果没有搭建的可以参考博主以前的文章。
这里博主拥有一台主节点、3台工作节点。
Spark版本:2.0.2
1 工作节点安装Spark
这里已经在主节点安装好了Spark(可以参考该专栏的第一篇博客),下面进行其他配置。
-
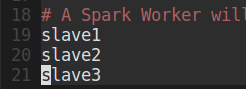
在主节点的Spark解压包下的 spark-2.0.2/conf/slaves 填上所有工作节点的主机名。
博主的主机名如下:
-
向工作节点传送Spark安装包
scp -r spark-2.0.2 slave1:/home/hadoop
scp -r spark-2.0.2 slave2:/home/hadoop
scp -r spark-2.0.2 slave3:/home/hadoop
- 在slave1、slave2、slave3分别设置环境变量
vim /home/hadoop/.bashrc
在文件末尾加入:
# Spark
export SPARK_HOME=/home/hadoop/spark-2.0.2
export PATH=$PATH:$SPARK_HOME/bin/
并更新文件:
source .bashr
-
工作节点需要安装Python3.5(Spark2.0.2不支持Python3.6+)
如果,工作节点已经安装Python,并且可以在Spark中执行Python程序,即可跳过该步骤。
安装Python3.5.2 可参考:https://blog.csdn.net/qq_38038143/article/details/88319161 (博客安装的是Python3.6.2,3.5.2步骤相同)
Python-3.5.2下载:(注:同样需要下载zlib包)
链接:https://pan.baidu.com/s/1jn6G5SzVBDwuNQAqHiPV2A
提取码:c9ml
zlib 包:
链接:https://pan.baidu.com/s/1fCVA_m7zIUSq7O_BczyVBg
提取码:7cip
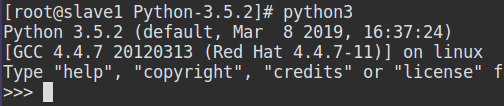
工作节点安装Python-3.5.2成功:
-
在主节点启动Spark集群
spark-2.0.2/sbin/start-all.sh
博主这里是先启动了Hadoop集群,然后启动Spark集群。
启动成功后各主机进程如下:

从上图中,可以看出,主节点启动的进程是:Master,工作节点启动:Worker进程。
在浏览器使用Web页面查看:master:8080

2 通过 pyspark 使用Spark自带的独立集群管理器连接集群
前面博文博主都是使用 pyspark 驱动器进行操作,下面列出如何在 pyspark 中使用集群资源:
启动命令:(spark://master:7077即代表独立集群管理器)
除了独立集群管理器,还支持 Hadoop yarn、Apache Mesos、Amazon EC2等。
pyspark --master spark://master:7077
同时,在Web页面,也可以看到驱动器的使用情况:

注意:如果要在pyspark中执行RDD计算,工作节点需要安装python3(博主的工作节点是RedHat,预先并没有安装Python3,所以博主是先安装了Python3,如果工作节点已安装可略过。)
如果能够顺利启动 pyspark,并且Web中能够看到应用运行,还不能最终确定集群是否搭建成功,还需要在集群中测试应用:
先将README.md文件上传至HDFS:
hdfs dfs -put README.md ./
如果没有上传,可能出现如下报错:

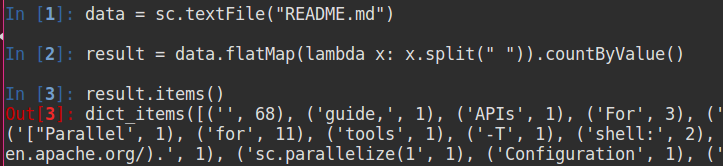
如上图,能够在 pysark 中执行RDD的行为操作并且能够计算出结果,即Spark集群安装成功。