搭建Spark集群
一、搭建三节点集群
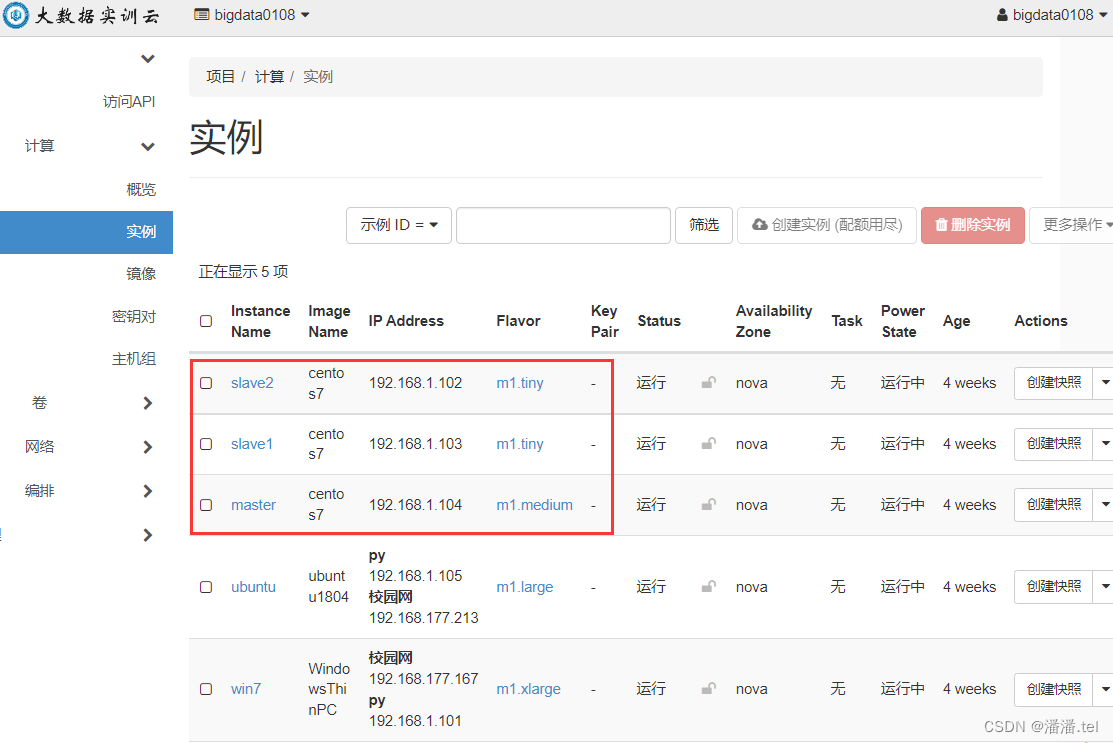
1、在私有云上创建三台虚拟机
 2、利用FinalShell登录三台虚拟机并创建SSH连接
2、利用FinalShell登录三台虚拟机并创建SSH连接
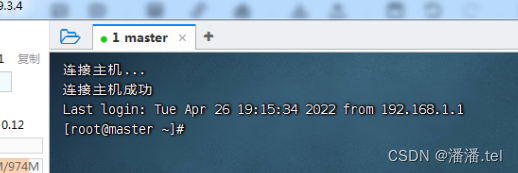
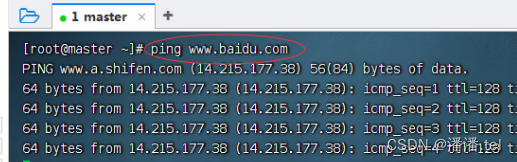
1.1登录master虚拟机
测试能否ping通百度
2.1登录slave1虚拟机
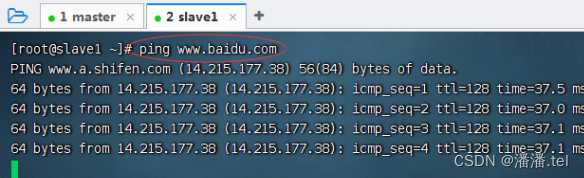
测试slave1虚拟机能否ping通百度
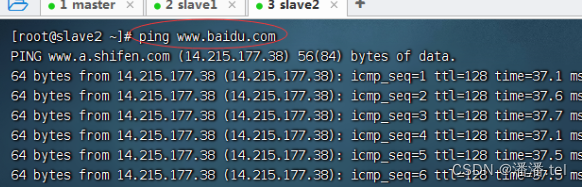
 3、登录slave2虚拟机
3、登录slave2虚拟机
测试能否ping通百度
(二)、查看三台虚拟机主机名
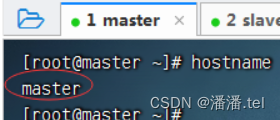
(1)查看master虚拟机主机名
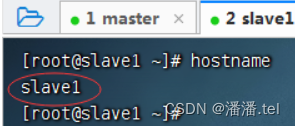
(2)查看slave1虚拟机主机名
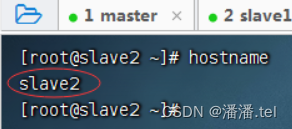
(3)查看slave2虚拟机主机名
(三)、配置三台虚拟机IP-主机名映射
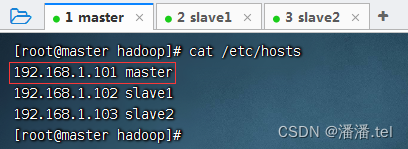
1、配置master虚拟机IP-主机名映射
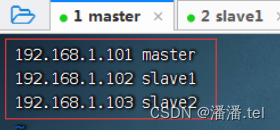
查看主机名映射
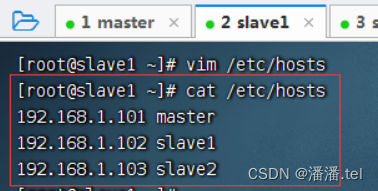
2、配置slave1虚拟机IP-主机名映射
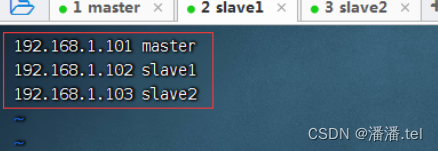
查看主机名映射
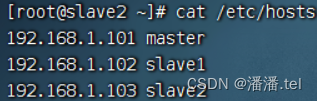
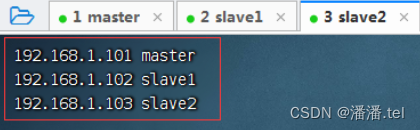
3、配置slave2虚拟机IP-主机名映射
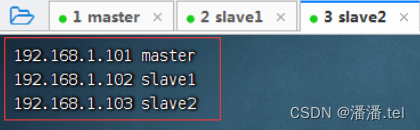
查看主机映射配置文件
(四)、关闭与禁用防火墙
1、关闭与禁用master
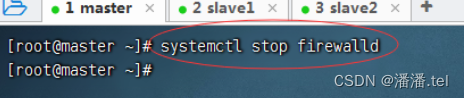
1.1关闭master防火墙
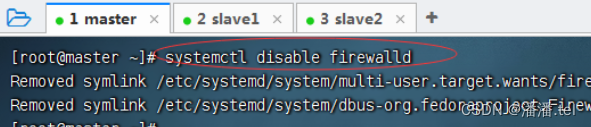
 1.2禁用master防火墙
1.2禁用master防火墙
1.3查看master防火墙状态
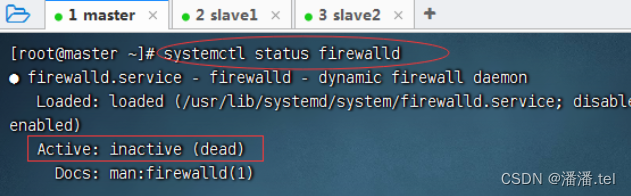
2、关闭与禁用slave1虚拟机防火墙
1、关闭slave1防火墙

1.2禁用slave1防火墙

1.3查看slave1防火墙状态
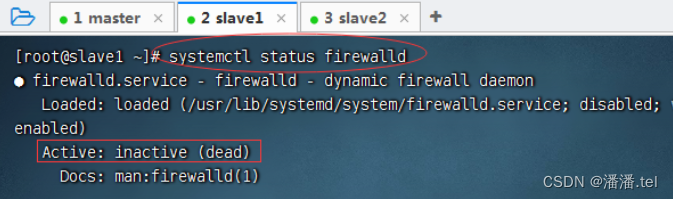
3、关闭与禁用slave2防火墙
1、关闭slave2防火墙
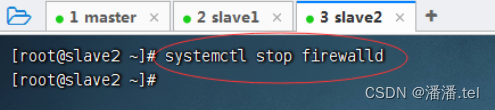
1.2禁用slave2防火墙
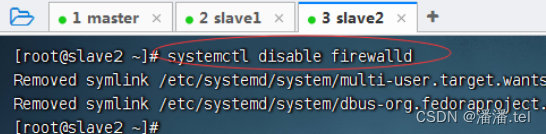
1.3查看slave2防火墙状态
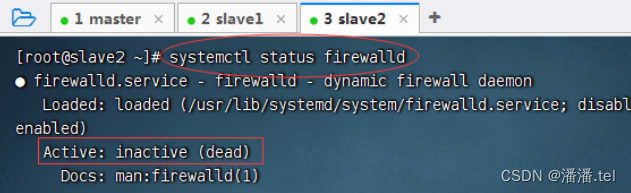
(五)、关闭SeLinux安全机制
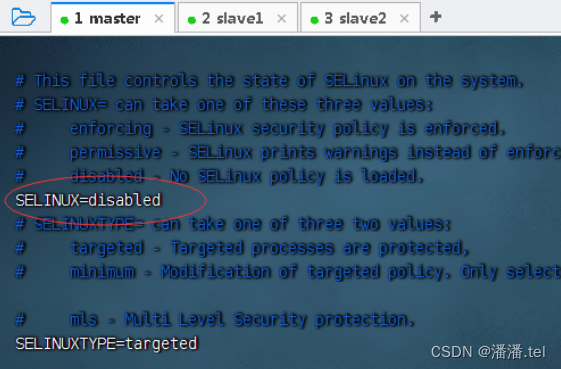
1、在master虚拟机上关闭SeLinux安全机制
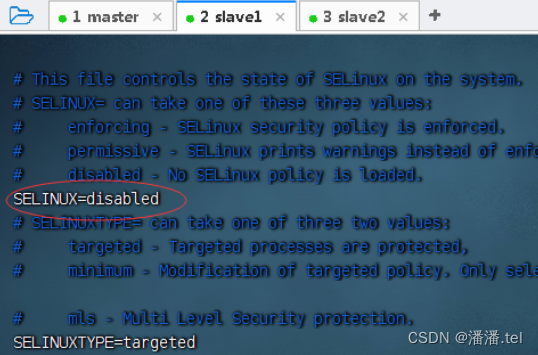
2、在slave1虚拟机上关闭SeLinux安全机制
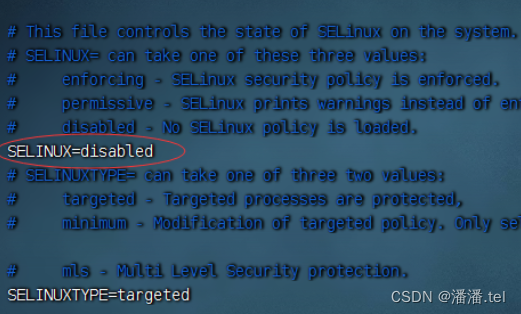
3、在slave2虚拟机上关闭SeLinux安全机制
(六)、设置三台虚拟机免密登录
1、master虚拟机免密登录master
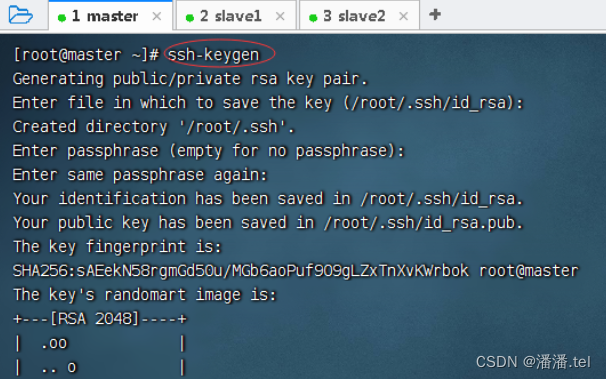 执行命令:将公钥拷贝到master
执行命令:将公钥拷贝到master
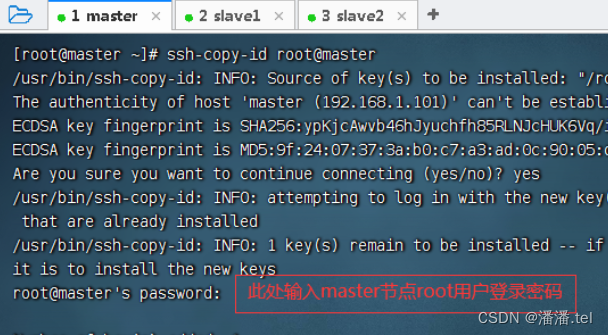 测试master节点是否免密登录自己
测试master节点是否免密登录自己
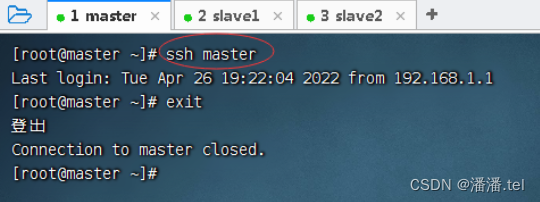
2、master虚拟机免密登录slave1
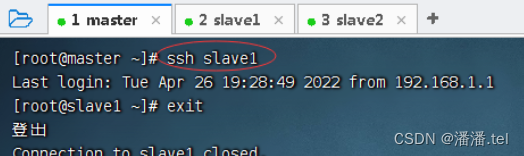
3、master虚拟机免密登录slave2
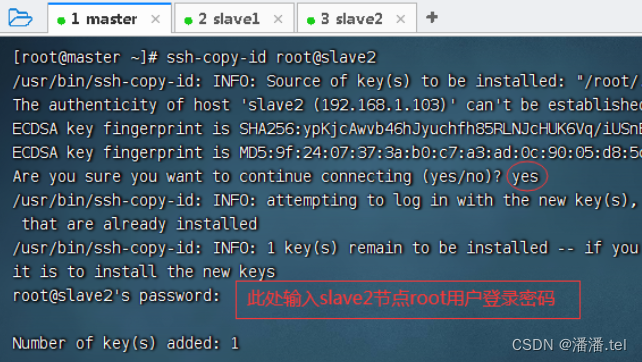
测试master节点是否免密登录slave2
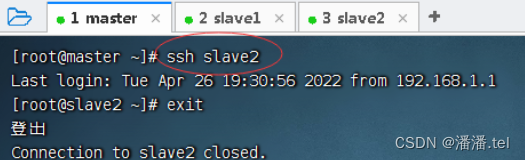
(七)、上传大数据相关软件到虚拟机
在win7虚拟机上查看相关软件
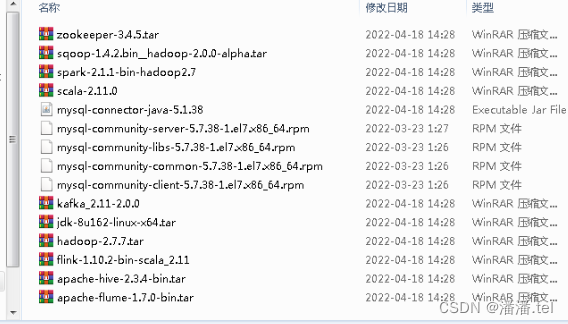
上传到master虚拟机/opt目录
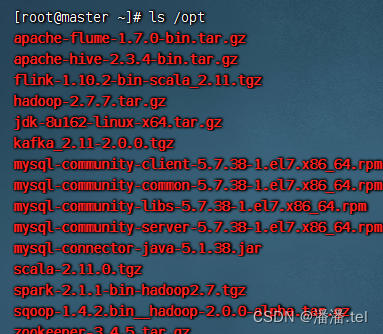
(八)、在三台虚拟机上安装配置JDK
1、在master虚拟机上安装配置JDK
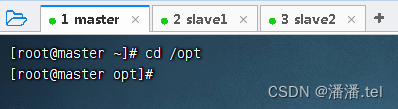
执行命令:

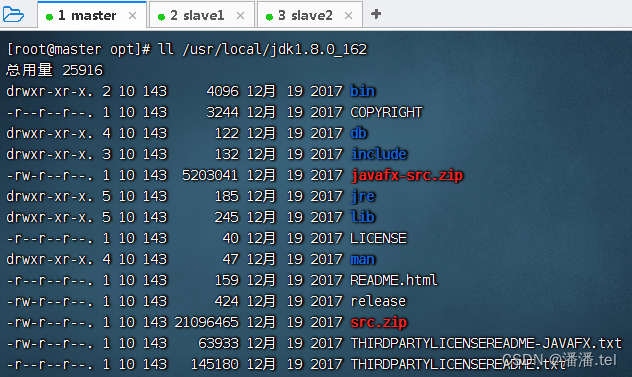
查看解压之后的jdk1.8.0_162目录
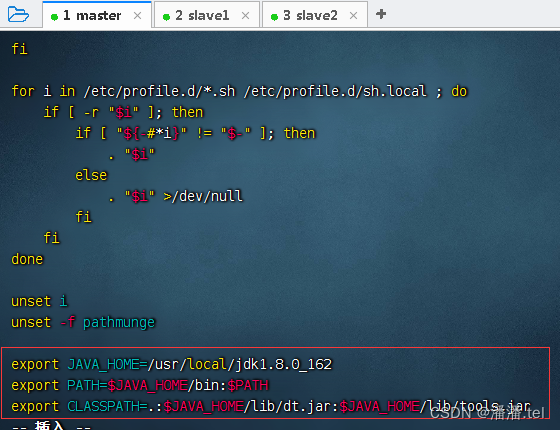
执行命令:配置环境变量
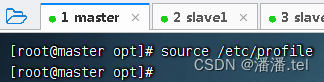
存盘退出,让配置生效
查看JDK版本
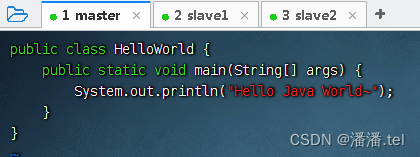
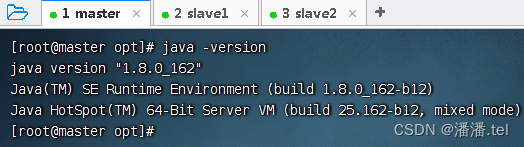 编写一个Java程序,hello world.Java
编写一个Java程序,hello world.Java
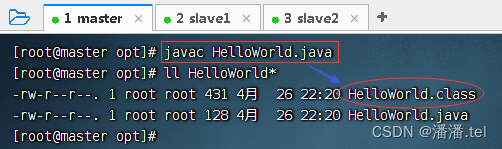
 存盘退出后,编译成字节码文件
存盘退出后,编译成字节码文件
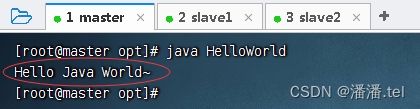
执行命令:Java hello world
2、将master虚拟机上安装的JDK分发到slave1和slave2虚拟机

在slave1虚拟机上查看JDK是否拷贝成功
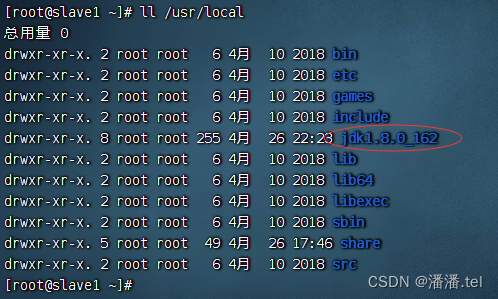

在slave2虚拟机上查看JDK是否拷贝成功
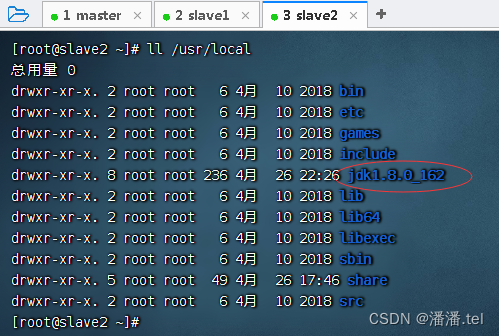 3、将master虚拟机上环境配置文件分发到slave1和slave2虚拟机
3、将master虚拟机上环境配置文件分发到slave1和slave2虚拟机
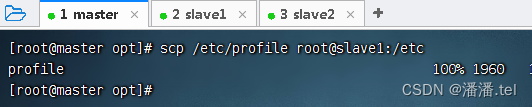
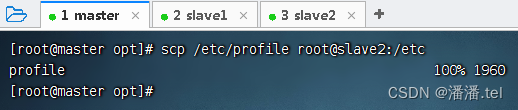

二、配置安全分布式Hadoop
(一)在master虚拟机上安装配置Hadoop
1、将Hadoop安装包解压到指定位置

查看解压之后的Hadoop目录
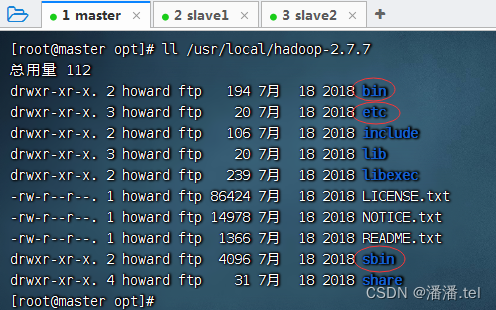
2、配置Hadoop环境变量
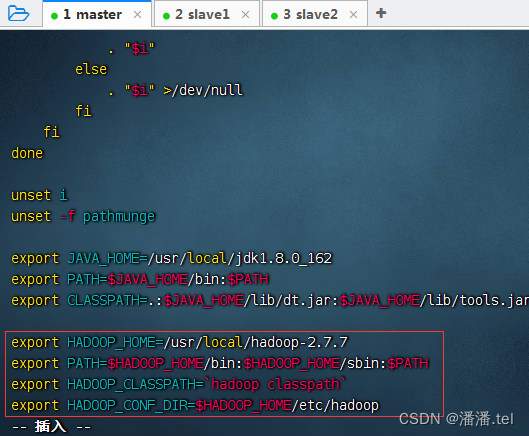
3、编辑Hadoop环境配置文件 - hadoop-env.sh
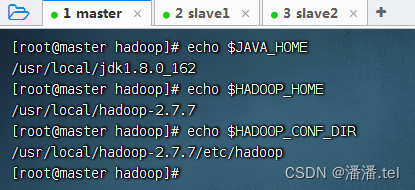
查看三个配置的三个环境变量
4、编辑Hadoop核心配置文件-core-site.xml
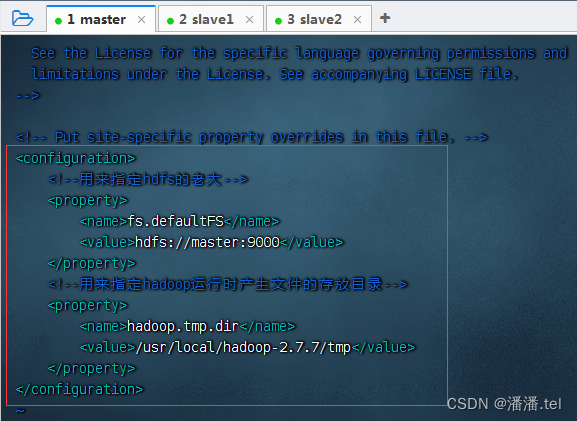
由于配置了IP地址主机名映射,因此配置HDFS老大节点可用hdfs://master:9000,否则必须用IP地址hdfs://192.168.1.101:9000
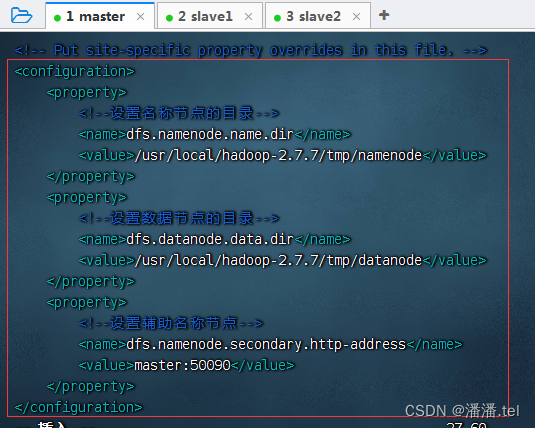
5、编辑HDFS配置文件-hdfs-site.xml
6、编辑MapReduce配置文件 - mapred-site.xml

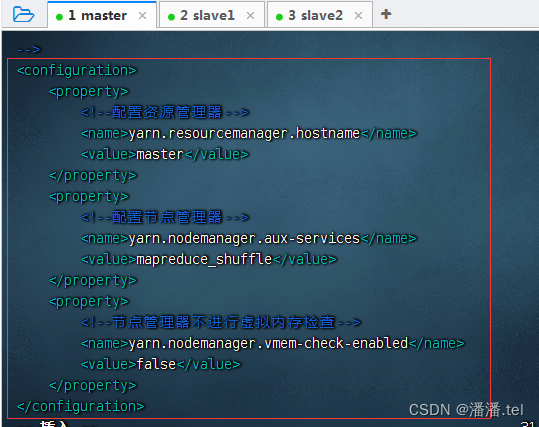
7、编辑yarn配置文件 - yarn-site.xml
8、编辑slaves文件(定名分)
(二)在salve1虚拟机上安装配置Hadoop
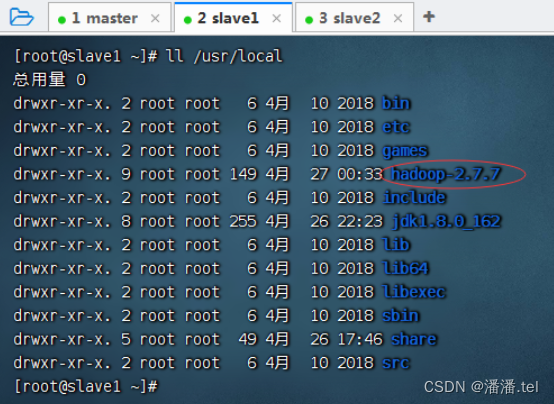
1、将master虚拟机上的Hadoop分发到slave1虚拟机

在slave2节点上查看分发的hadoop
](https://img-blog.csdnimg.cn/75cd359e516c4b79b2166a361d3780f6.png)
2、将master虚拟机上环境配置文件分发到slave2虚拟机

3、在slave2虚拟机上让环境配置生效
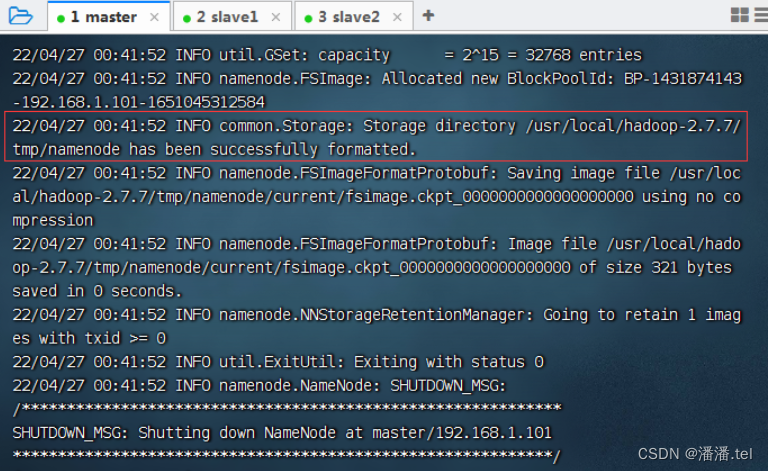
三、在master虚拟机上格式化名称节点
四、启动Hadoop集群
(一)在master虚拟机上启动Hadoop
1、在master虚拟机上启动Hadoop集群
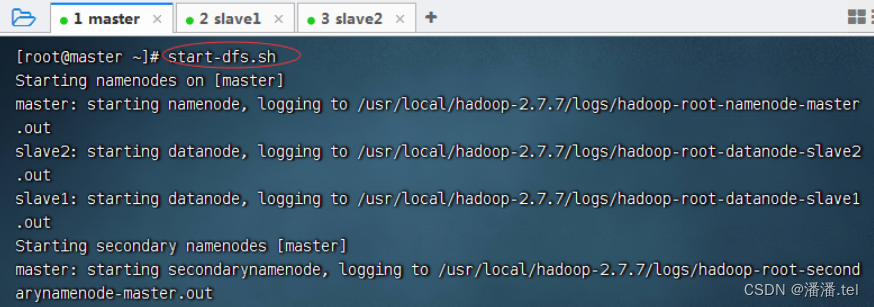
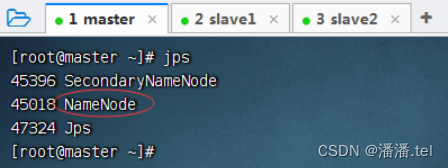
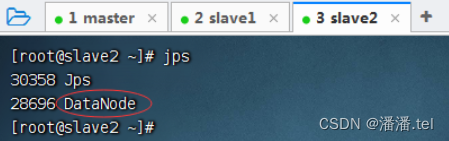
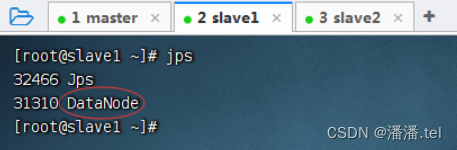
1.1查看三个虚拟机的进程
2、查看Hadoop集群HDFS的WebUI界面
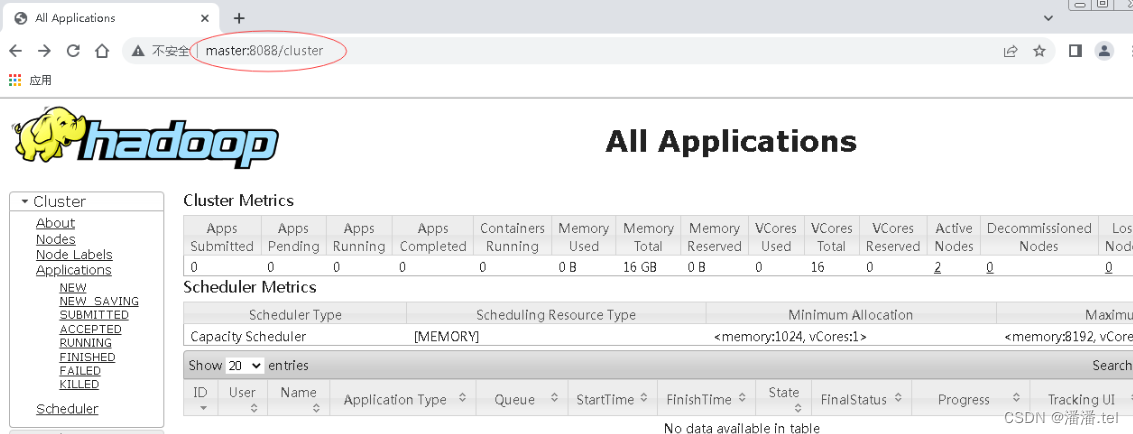
3、查看Hadoop集群的Yarn的WebUI界面
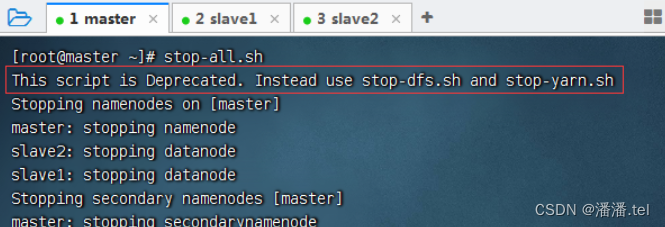
五、停止Hadoop集群
六、配置Spark Standalone集群
(一)在master虚拟机上安装配置spark
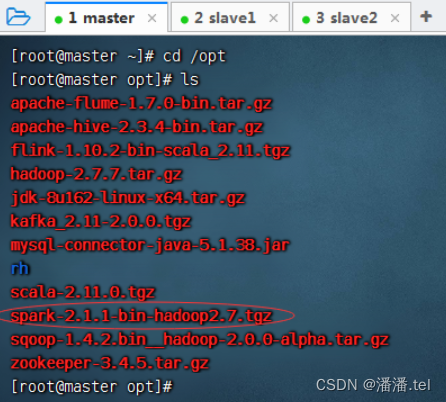
1、进入/opt目录,查看spark安装包
2、将spark安装包解压到指定目录

3、配置spark环境变量
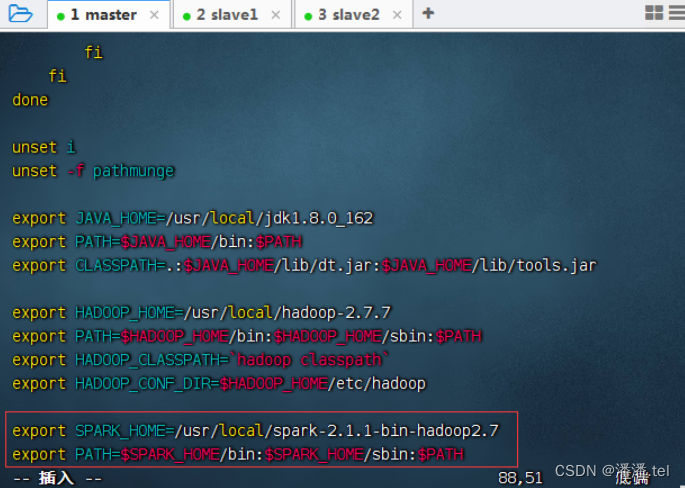
4、编辑spark环境配置文件 - spark-env.sh

5、创建slaves文件,添加从节点
(二)在slave1虚拟机上安装配置Spark
1、把master虚拟机上安装的spark分发给slave1虚拟机

2、将master虚拟机上环境变量配置文件分发到slave1虚拟机

3、在slave1虚拟机上让spark环境配置文件生效
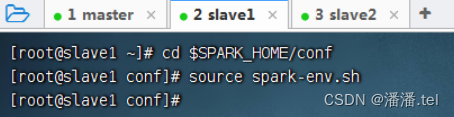
(三)在slave2虚拟机上安装配置Spark
1、把master虚拟机上安装的spark分发给slave2虚拟机

2、将master虚拟机上环境变量配置文件分发到slave2虚拟机

3、在slave2虚拟机上让spark环境配置文件生效
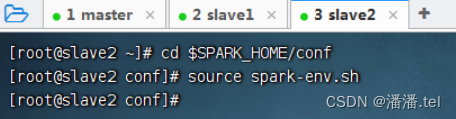
七、启动Spark Standalone集群
(一)启动hadoop的dfs服务
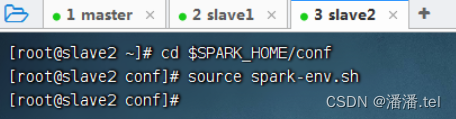
(二)启动Spark集群
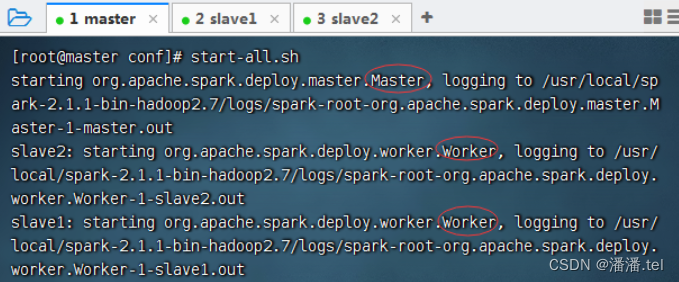
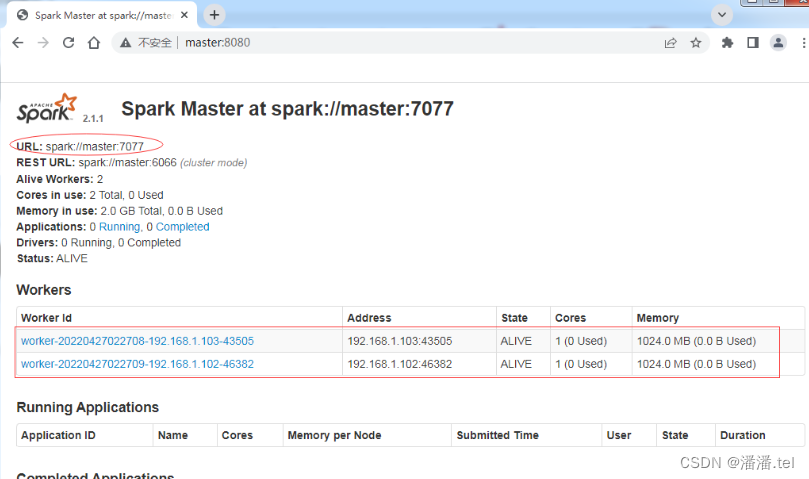
(三)访问Spark的WebUI
八、使用Spark Standalone集群
(一)启动Scala版Spark Shell
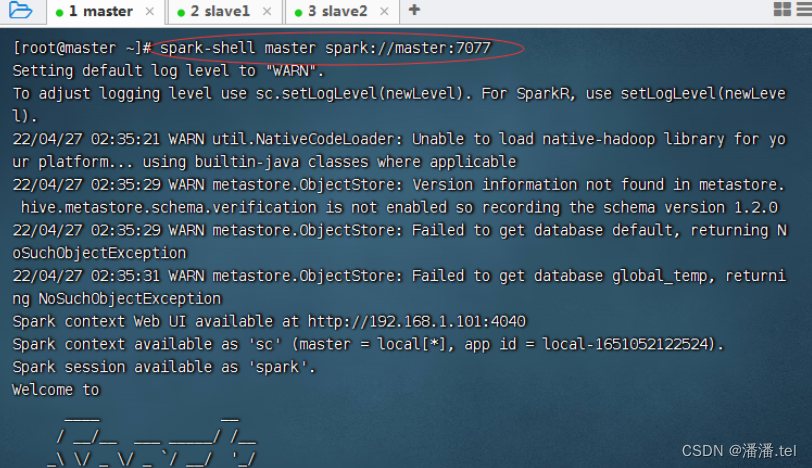
(二)提交Spark应用程序
1、spark-subm常用参数
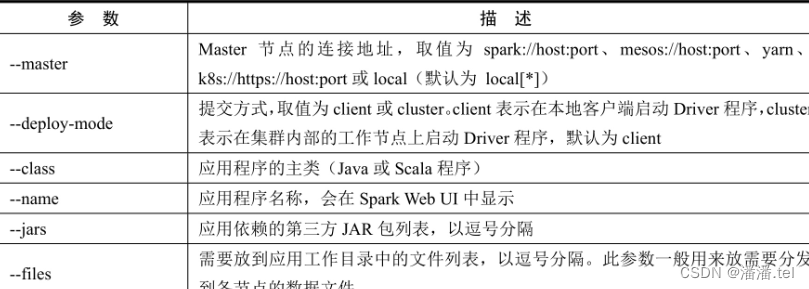
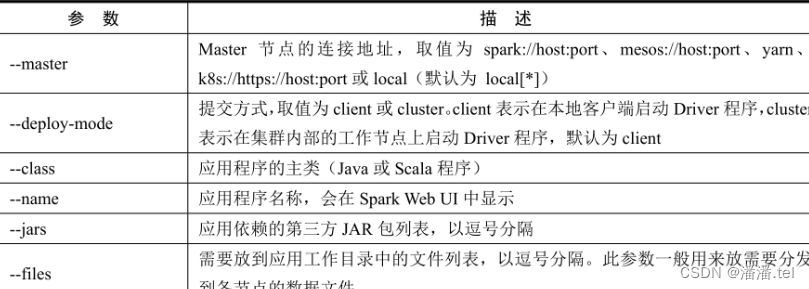
2、案例演示-提交Spark自带的圆周率计算程序
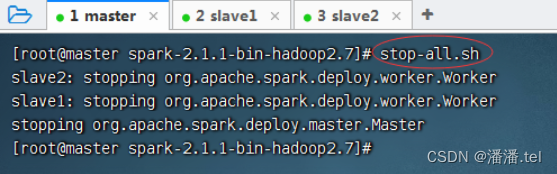
(三)停止Spark集群服务