前言
Spark的部署模式有Local、Local-Cluster、Standalone、Yarn、Mesos,我们选择最具代表性的Standalone集群部署模式。
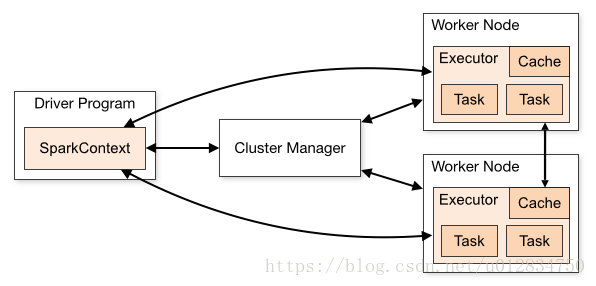
一、集群角色
从物理部署层面上来看,Spark主要分为两种类型的节点,Master节点和Worker节点,Master节点主要运行集群管理器的中心化部分,所承载的作用是分配Application到Worker节点,维护Worker节点,Driver,Application的状态。Worker节点负责具体的业务运行。
从Spark程序运行的层面来看,Spark主要分为驱动器节点和执行器节点。
二、集群安装【Standalone】
2.1、准备
Spark集群最简单的只需要JDK就行了,但是这里想配置配置Job History Server,所以需要Hadoop集群,因此我直接在前面的Hbase镜像基础上直接搭建Spark集群了。
另外去Spark官网下载Spark集群Jar包,我下载的是spark-2.1.1-bin-hadoop2.7.tgz
2.2、安装
1)上传spark-2.1.1-bin-hadoop2.7.tgz 包到/opt/module目录,并解压
$ tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz2)进入到Spark安装目录的配置目录
$ cd /opt/module/spark-2.1.1-bin-hadoop2.7/conf3)将slaves.template复制为slaves,将spark-env.sh.template复制为spark-env.sh
$ cp slaves.template slaves
$ spark-env.sh.template spark-env.sh4)修改slave文件,将work的hostname输入:
hadoop1
hadoop25)修改spark-env.sh文件,添加如下配置:
SPARK_MASTER_HOST=hadoop0
SPARK_MASTER_PORT=70776)将配置好的Spark文件拷贝到其他节点上
7)hadoop0上启动集群
/opt/module/spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh
8)查看
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://hadoop0:8080/
到此为止,Spark集群安装完毕。
注意:如果遇到 “JAVA_HOME not set” 异常,可以在sbin目录下的spark-config.sh 文件中加入如下配置:
export JAVA_HOME=XXXX三、集群配置Job History Server【Standalone】
1)进入到Spark安装目录
$ cd /opt/module/spark-2.1.1-bin-hadoop2.7/conf2)将spark-default.conf.template复制为spark-default.conf,修改spark-default.conf文件,开启Log,添加如下配置:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop0:9000/directory
spark.eventLog.compress true【注意:HDFS上的目录需要提前存在】
3)修改spark-env.sh文件,添加如下配置:
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000
-Dspark.history.retainedApplications=3
-Dspark.history.fs.logDirectory=hdfs://hadoop0:9000/directory"参数描述:
spark.eventLog.dir:Application
在运行过程中所有的信息均记录在该属性指定的路径下;
spark.history.ui.port=4000
调整WEBUI访问的端口号为4000
spark.history.fs.logDirectory=hdfs://hadoop0:9000/directory
配置了该属性后,在start-history-server.sh时就无需再显式的指定路径,Spark History Server页面只展示该指定路径下的信息
spark.history.retainedApplications=3
指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4)将配置好的Spark文件拷贝到其他节点上
5)启动Spark集群
$ /opt/module/spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh6)启动后执行:【别忘了启动HDFS,并必须先创建directory目录】
$ /opt/module/spark-2.1.1-bin-hadoop2.7/sbin/start-history-server.sh7)查看,访问hadoop0:4000
到此为止,Spark History Server安装完毕.
如果遇到Hadoop HDFS的写入权限问题:
org.apache.hadoop.security.AccessControlException
解决方案: 在hdfs-site.xml中添加如下配置,关闭权限验证
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
查看日志有两种方式:
1、对于正在运行的应用, 直接访问 http://master:4040 查看
2、对于已经结束的应用, 直接访问 http://master:4000 查看