文章目录
部分参考: https://zhuanlan.zhihu.com/p/51385110
定义求导属性
所有的tensor都有.requires_grad属性,都可以设置成自动求导。具体方法就是在定义tensor的时候,让这个属性为True
import torch
# create a tensor with setting its .requires_grad as Ture
x = torch.ones(2, 2, requires_grad=True)
print(x)
x1 = torch.ones(2,2,requires_grad=False)
# x1.requires_grad_(True)
print(x1)
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
tensor([[1., 1.],
[1., 1.]])
y = x + 2
print(y)
y1 = x1 + 2
print(y1)
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
tensor([[3., 3.],
[3., 3.]])
print(y.grad_fn)
print(y1.grad_fn)
<AddBackward0 object at 0x7f38e4f9f6a0>
None
注意区分tensor.requires_grad和tensor.requires_grad_()两个东西,前面是查看变量的属性值,后者是调用内置的函数,来改变属性。
a = torch.randn(2, 2) # a is created by user, its .grad_fn is None
a = ((a * 3) / (a - 1))
print(a.requires_grad)
a.requires_grad_(True) # change the attribute .grad_fn of a
print(a.requires_grad)
b = (a * a).sum() # add all elements of a to b
print(b.grad_fn)
False
True
<SumBackward0 object at 0x7f383fe81828>
计算xx关于标量的梯度
这里需要注意的是,要想使x支持求导,必须让x为浮点类型,也就是我们给初始值的时候要加个点:“.”。不然的话,就会报错。
即,不能定义[1,2,3],而应该定义成[1.,2.,3.],前者是整数,后者才是浮点数。
x = torch.tensor([[1.,2.,3.],[4.,5.,6.]],requires_grad=True)
y = x+1
z = 2*y*y
J = torch.mean(z)
print(x)
print(y)
tensor([[1., 2., 3.],
[4., 5., 6.]], requires_grad=True)
tensor([[2., 3., 4.],
[5., 6., 7.]], grad_fn=<AddBackward0>)
求导,只能是【标量】对标量,或者【标量】对向量/矩阵求导。也就是对于上面的所谓计算图来说,求偏导这件事只能从J出发,不能从Z出发。
J.backward()
print(x.grad)
print(y.grad)
tensor([[1.3333, 2.0000, 2.6667],
[3.3333, 4.0000, 4.6667]])
None
推导:
在上面那种情况里,y是由x产生的,因此无法计算最终结果对y的梯度。而在下面这种情况下,y不是由任何其他的变量生成的,所以可以求梯度,类似的,t由x和y生成,因此不能求梯度。
from torch.autograd import Variable
x = Variable(torch.randn(3), requires_grad=True)
y = Variable(torch.randn(3), requires_grad=True)
z = Variable(torch.randn(3), requires_grad=True)
print(x)
print(y)
print(z)
t = x + y
l = t.dot(z)
l.backward()
print(x.grad)
print(y.grad)
print(z.grad)
print(t.grad)
tensor([-1.0363, 0.5200, -0.6590], requires_grad=True)
tensor([-0.0601, 0.3705, 1.0292], requires_grad=True)
tensor([ 0.6089, -1.0316, -1.1477], requires_grad=True)
tensor([ 0.6089, -1.0316, -1.1477])
tensor([ 0.6089, -1.0316, -1.1477])
tensor([-1.0964, 0.8905, 0.3702])
None
计算xx关于张量的梯度
张量(tensor)可以理解成向量和矩阵的扩展。通俗一点理解的话,我们可以将标量视为零阶张量,向量视为一阶张量,那么矩阵就是二阶张量。
define a function:
x = [1, 1, 1]
y = x + [1, 2, 3]
z = y ^ 3
x = torch.ones(3, requires_grad=True)
y = x + torch.tensor([1., 2., 3.])
z = y * y * y
print(z)
v = torch.tensor([1, 0.1, 0.01])
# z is a vector, so you need to specify a gradient whose size is the same as z
z.backward(v, retain_graph=True)
print(x.grad)
tensor([ 8., 27., 64.], grad_fn=<MulBackward0>)
tensor([12.0000, 2.7000, 0.4800])
接下来展示一下如何对中间项求导
grad_list = []
def print_grad(grad):
grad_list.append(grad)
print("grad: ", grad_list)
x = torch.ones(3, requires_grad=True)
y = x + torch.tensor([1., 2., 3.])
z = y * y * y
y.register_hook(print_grad)
print("z: ", z)
v = torch.tensor([1., 1., 1.])
# z is a vector, so you need to specify a gradient whose size is the same as z
z.backward(v, retain_graph=True)
print("x:", x.grad)
print("y:", y.grad)
z: tensor([ 8., 27., 64.], grad_fn=<MulBackward0>)
grad: [tensor([12., 27., 48.])]
x: tensor([12., 27., 48.])
y: None
由于
,
, 因此
,当v的值全为1时,可以发现x.grad的结果恰好是
,也就是标准的对张量求导,常常应用于有多个输出值的情况,比如loss=[loss1,loss2,loss3],那么我们可以让loss的各个分量分别对x求导。当v取其他值时,
,因此v可以理解成是让不同的分量有不同的权重,最终结果为偏导数与权重的乘积。
需要注意的一点是,一个计算图只能backward一次,一个计算图在进行反向求导之后,为了节省内存,这个计算图就销毁了。如果需要保留计算图,不让子图释放,就需要添加参数retain_graph=True。
weight = torch.tensor([[1.,2.], [3., 4.]], requires_grad=True)
input = torch.tensor([[5.], [6.]])
output = torch.mm(weight, input)
print(weight)
print(input)
print(output)
output.backward(torch.ones_like(output))
print(weight.grad)
tensor([[1., 2.],
[3., 4.]], requires_grad=True)
tensor([[5.],
[6.]])
tensor([[17.],
[39.]], grad_fn=<MmBackward>)
tensor([[5., 6.],
[5., 6.]])
搭建神经网络
定义绘图函数
def show_original_points():
label_csv = open('./labels/label.csv', 'r')
label_writer = csv.reader(label_csv)
class1_point = []
class2_point = []
class3_point = []
for item in label_writer:
if item[2] == '0':
class1_point.append([item[0], item[1]])
elif item[2] == '1':
class2_point.append([item[0], item[1]])
else:
class3_point.append([item[0], item[1]])
data1 = np.array(class1_point, dtype=float)
data2 = np.array(class2_point, dtype=float)
data3 = np.array(class3_point, dtype=float)
x1, y1 = data1.T
x2, y2 = data2.T
x3, y3 = data3.T
plt.figure()
plt.scatter(x1, y1, c='b', marker='.')
plt.scatter(x2, y2, c='r', marker='.')
plt.scatter(x3, y3, c='g', marker='.')
plt.axis()
plt.title('scatter')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
定义一个神经网络
定义神经网络, 需要继承 nn.Moudle, 并重载 __init__ 和 forward 方式
import numpy as np
import matplotlib.pyplot as plt
import torchvision
import torch
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import torch.optim as optim
import time
import csv
import numpy as np
class Network(nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
'''
Args:
n_feature(int): size of input tensor
n_hidden(int): size of hidden layer
n_output(int): size of output tensor
'''
super(Network, self).__init__()
# 将隐层设置为线性映射层
self.hidden = nn.Linear(n_feature, n_hidden)
# 定义激活函数
self.sigmoid = nn.Sigmoid()
# 定义输出层为线性映射层
self.predict = nn.Linear(n_hidden, n_output)
def forward(self, x):
'''
x(tensor): inputs of the network
'''
# hidden layer
h1 = self.hidden(x)
# activate function
h2 = self.sigmoid(h1)
# output layer
out = self.predict(h2)
'''
由于损失函数采用CrossEntropy,里面的softmax已经将输出转换成了概率,因此最后一步不需要调用sigmod函数了。
'''
return out
CrossEntropy written in pytorch:
https://pytorch.org/docs/stable/nn.html?highlight=crossentropy#torch.nn.CrossEntropyLoss
加载数据集
class PointDataset(Dataset):
def __init__(self, csv_file, transform=None):
'''
Args:
csv_file(string): path of label file
transform (callable, optional): Optional transform to be applied
on a sample.
'''
self.frame = pd.read_csv(csv_file, encoding='utf-8', header=None)
print('csv_file source ---->', csv_file)
self.transform = transform
def __len__(self):
return len(self.frame)
def __getitem__(self, idx):
x = self.frame.iloc[idx, 0]
y = self.frame.iloc[idx, 1]
point = np.array([x, y])
label = int(self.frame.iloc[idx, 2])
if self.transform is not None:
point = self.transform(point)
sample = {'point': point, 'label': label}
return sample
训练模型
def train(classifier_net, trainloader, testloader, device, lr, optimizer):
'''
Args:
classifier_net(nn.model): train model
trainloader(torch.utils.data.DateLoader): train loader
testloader(torch.utils.data.DateLoader): test loader
device(torch.device): the evironment your model training
LR(float): learning rate
'''
# loss function
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optimizer
# save the mean value of loss in an epoch
running_loss = []
running_accuracy = []
# count loss in an epoch
temp_loss = 0.0
# count the iteration number in an epoch
iteration = 0
for epoch in range(epoches):
'''
adjust learning rate when you are training the model
'''
# adjust learning rate
# if epoch % 100 == 0 and epoch != 0:
# LR = LR * 0.1
# for param_group in optimizer.param_groups:
# param_group['lr'] = LR
for i, data in enumerate(trainloader):
point, label = data['point'], data['label']
# 转换成float32类型以进一步节约空间
point, label = point.to(device).to(torch.float32), label.to(device)
outputs = classifier_net(point)
# empty parameters in optimizer
optimizer.zero_grad()
# calcutate loss value
loss = criterion(outputs, label)
# back propagation
loss.backward()
# update paraeters in optimizer(update weigtht)
optimizer.step()
# save loss in a list
temp_loss += loss.item()
iteration +=1
# print loss value
# print('[{0:d},{1:5.0f}] loss {2:.5f}'.format(epoch + 1, i, loss.item()))
#slow down speed of print function
# time.sleep(0.5)
running_loss.append(temp_loss / iteration)
temp_loss = 0
iteration = 0
# print('test {}:----------------------------------------------------------------'.format(epoch))
# call test function and return accuracy
running_accuracy.append(predict(classifier_net, testloader, device))
# show loss curve
show_running_loss(running_loss)
# show accuracy curve
show_accuracy(running_accuracy)
return classifier_net
# 绘制损失函数图
def show_running_loss(running_loss):
# generate x value
x = np.array([i for i in range(len(running_loss))])
# generate y value
y = np.array(running_loss)
# define a graph
plt.figure()
# generate curve
plt.plot(x, y, c='b')
# show axis
plt.axis()
# define title
plt.title('loss curve:')
#define the name of x axis
plt.xlabel('step')
plt.ylabel('loss value')
# show graph
plt.show()
测试函数
def predict(classifier_net, testloader, device):
# correct = [0 for i in range(3)]
# total = [0 for i in range(3)]
correct = 0
total = 0
with torch.no_grad():
'''
you can also stop autograd from tracking history on Tensors with .requires_grad=True
by wrapping the code block in with torch.no_grad():
'''
for data in testloader:
point, label = data['point'], data['label']
point, label = point.to(device).to(torch.float32), label.to(device)
outputs = classifier_net(point)
'''
if you want to get probability of the model prediction,
you can use softmax function here to transform outputs to probability.
'''
# transform the prediction to one-hot form
_, predicted = torch.max(outputs, 1)
# print('model prediction: ', predicted)
# print('ground truth:', label, '\n')
correct += (predicted == label).sum()
total += label.size(0)
# print('current correct is:', correct.item())
# print('current total is:', total)
# print('the accuracy of the model is {0:5f}'.format(correct.item()/total))
return correct.item() / total
def show_accuracy(running_accuracy):
x = np.array([i for i in range(len(running_accuracy))])
y = np.array(running_accuracy)
plt.figure()
plt.plot(x, y, c='b')
plt.axis()
plt.title('accuracy curve:')
plt.xlabel('step')
plt.ylabel('accuracy value')
plt.show()
主函数
if name == 'main’下面的代码在py文件被作为一个模块引入时不会执行,在单独执行该py文件时作为主函数执行。
if __name__ == '__main__':
'''
change train epoches here
'''
# number of training
epoches = 100
'''
change learning rate here
'''
# learning rate
# 1e-4 = e^-4
lr = 1e-3
'''
change batch size here
'''
# batch size
batch_size = 16
# define a transform to pretreat data
transform = torch.tensor
# define a gpu device
device = torch.device('cpu')
# define a trainset
trainset = PointDataset('./labels/train.csv', transform=transform)
# Dataloader可以自动帮助生成多组训练数据,num_worker的含义是多线程数。
trainloader = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=4)
# define a testset
testset = PointDataset('./labels/test.csv', transform=transform)
# define a testloader
testloader = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False, num_workers=4)
show_original_points()
# define a network
classifier_net = Network(2, 5, 3).to(device)
'''
change optimizer here
'''
# define a optimizer
optimizer = optim.SGD(classifier_net.parameters(), lr=lr, momentum=0.9)
# get trained model
classifier_net = train(classifier_net, trainloader, testloader, device, lr, optimizer,)
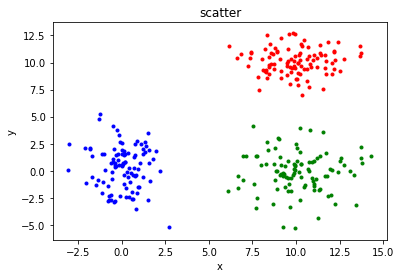

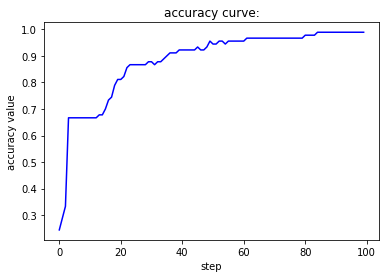
尝试调整不同大小的学习率,观察loss曲线和accuracy曲线,并阐述学习率对loss值以及accuracy值的影响和原因。**
为方便查看曲线,将print输出语句注释掉。
if __name__ == '__main__':
'''
change train epoches here
'''
# number of training
epoches = 100
'''
change learning rate here
'''
# learning rate
# 1e-4 = e^-4
lr = 1e-4
'''
change batch size here
'''
# batch size
batch_size = 16
# define a transform to pretreat data
transform = torch.tensor
# define a gpu device
device = torch.device('cpu')
# define a trainset
trainset = PointDataset('./labels/train.csv', transform=transform)
# define a trainloader
trainloader = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=4)
# define a testset
testset = PointDataset('./labels/test.csv', transform=transform)
# define a testloader
testloader = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False, num_workers=4)
show_original_points()
# define a network
classifier_net = Network(2, 5, 3).to(device)
'''
change optimizer here
'''
# define a optimizer
optimizer = optim.SGD(classifier_net.parameters(), lr=lr, momentum=0.9)
# get trained model
classifier_net = train(classifier_net, trainloader, testloader, device, lr, optimizer,)
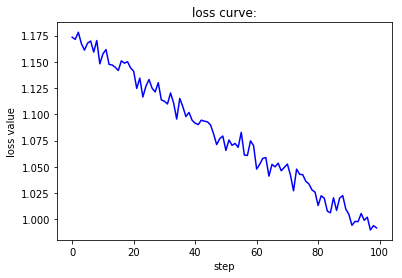
if __name__ == '__main__':
'''
change train epoches here
'''
# number of training
epoches = 100
'''
change learning rate here
'''
# learning rate
# 1e-4 = e^-4
lr = 1e-2
'''
change batch size here
'''
# batch size
batch_size = 16
# define a transform to pretreat data
transform = torch.tensor
# define a gpu device
device = torch.device('cpu')
# define a trainset
trainset = PointDataset('./labels/train.csv', transform=transform)
# define a trainloader
trainloader = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=4)
# define a testset
testset = PointDataset('./labels/test.csv', transform=transform)
# define a testloader
testloader = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False, num_workers=4)
show_original_points()
# define a network
classifier_net = Network(2, 5, 3).to(device)
'''
change optimizer here
'''
# define a optimizer
optimizer = optim.SGD(classifier_net.parameters(), lr=lr, momentum=0.9)
# get trained model
classifier_net = train(classifier_net, trainloader, testloader, device, lr, optimizer,)
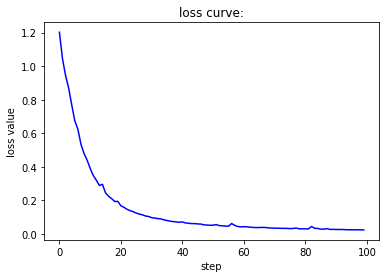
if __name__ == '__main__':
'''
change train epoches here
'''
# number of training
epoches = 100
'''
change learning rate here
'''
# learning rate
# 1e-4 = e^-4
lr = 1e-1
'''
change batch size here
'''
# batch size
batch_size = 16
# define a transform to pretreat data
transform = torch.tensor
# define a gpu device
device = torch.device('cpu')
# define a trainset
trainset = PointDataset('./labels/train.csv', transform=transform)
# define a trainloader
trainloader = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=4)
# define a testset
testset = PointDataset('./labels/test.csv', transform=transform)
# define a testloader
testloader = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False, num_workers=4)
show_original_points()
# define a network
classifier_net = Network(2, 5, 3).to(device)
'''
change optimizer here
'''
# define a optimizer
optimizer = optim.SGD(classifier_net.parameters(), lr=lr, momentum=0.9)
# get trained model
classifier_net = train(classifier_net, trainloader, testloader, device, lr, optimizer,)
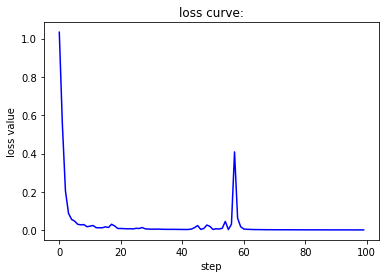
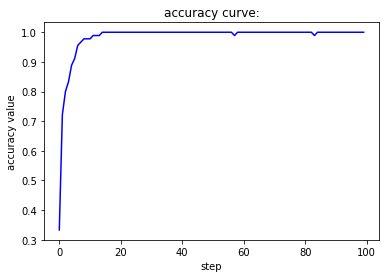
在上面的三份测试代码中,学习率首先变为原来的十分之一,接下来变为原来的十倍、一百倍。在第一种情况下,损失函数曲线呈现出线性下降的趋势,下降速度相对较慢,准确率在较长一段时间内没有明显变化,且上升极不稳定。在第二种情况下,无论是损失函数的下降还是准确率的上升过程都堪称完美,非常快速且稳定地到达了一个良好的水平。在第三种情况下,由于学习率过大,围绕着梯度下降的最低点产生了来回跳动的情况,因此我们可以看到虽然下降过程很快但是并不稳定,损失函数和准确率均出现了来回波动的现象。
尝试调整不同的batch_size, batch_size=1, batch_size=210,batch_size=(1~210), 并阐述batch_size对loss值以及accuracy值的影响和原因。
if __name__ == '__main__':
'''
change train epoches here
'''
# number of training
epoches = 100
'''
change learning rate here
'''
# learning rate
# 1e-4 = e^-4
lr = 1e-2
'''
change batch size here
'''
# batch size
batch_size = 1
# define a transform to pretreat data
transform = torch.tensor
# define a gpu device
device = torch.device('cpu')
# define a trainset
trainset = PointDataset('./labels/train.csv', transform=transform)
# define a trainloader
trainloader = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=4)
# define a testset
testset = PointDataset('./labels/test.csv', transform=transform)
# define a testloader
testloader = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False, num_workers=4)
show_original_points()
# define a network
classifier_net = Network(2, 5, 3).to(device)
'''
change optimizer here
'''
# define a optimizer
optimizer = optim.SGD(classifier_net.parameters(), lr=lr, momentum=0.9)
# get trained model
classifier_net = train(classifier_net, trainloader, testloader, device, lr, optimizer,)
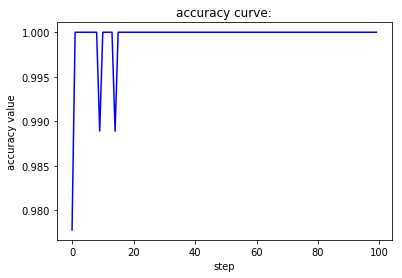
if __name__ == '__main__':
'''
change train epoches here
'''
# number of training
epoches = 100
'''
change learning rate here
'''
# learning rate
# 1e-4 = e^-4
lr = 1e-2
'''
change batch size here
'''
# batch size
batch_size = 210
# define a transform to pretreat data
transform = torch.tensor
# define a gpu device
device = torch.device('cpu')
# define a trainset
trainset = PointDataset('./labels/train.csv', transform=transform)
# define a trainloader
trainloader = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=4)
# define a testset
testset = PointDataset('./labels/test.csv', transform=transform)
# define a testloader
testloader = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False, num_workers=4)
show_original_points()
# define a network
classifier_net = Network(2, 5, 3).to(device)
'''
change optimizer here
'''
# define a optimizer
optimizer = optim.SGD(classifier_net.parameters(), lr=lr, momentum=0.9)
# get trained model
classifier_net = train(classifier_net, trainloader, testloader, device, lr, optimizer,)
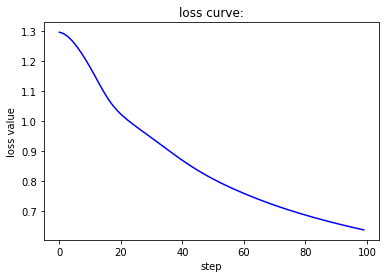
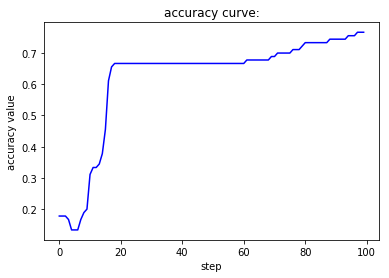
if __name__ == '__main__':
'''
change train epoches here
'''
# number of training
epoches = 100
'''
change learning rate here
'''
# learning rate
# 1e-4 = e^-4
lr = 1e-2
'''
change batch size here
'''
# batch size
batch_size = 70
# define a transform to pretreat data
transform = torch.tensor
# define a gpu device
device = torch.device('cpu')
# define a trainset
trainset = PointDataset('./labels/train.csv', transform=transform)
# define a trainloader
trainloader = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=4)
# define a testset
testset = PointDataset('./labels/test.csv', transform=transform)
# define a testloader
testloader = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False, num_workers=4)
show_original_points()
# define a network
classifier_net = Network(2, 5, 3).to(device)
'''
change optimizer here
'''
# define a optimizer
optimizer = optim.SGD(classifier_net.parameters(), lr=lr, momentum=0.9)
# get trained model
classifier_net = train(classifier_net, trainloader, testloader, device, lr, optimizer,)
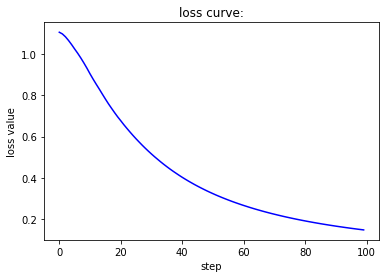
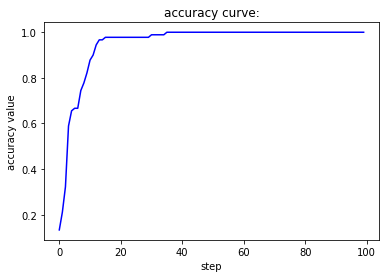
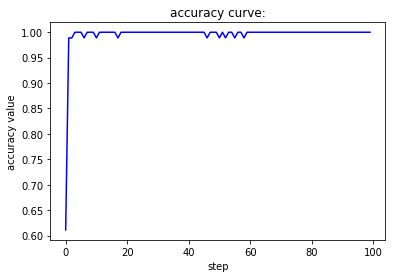
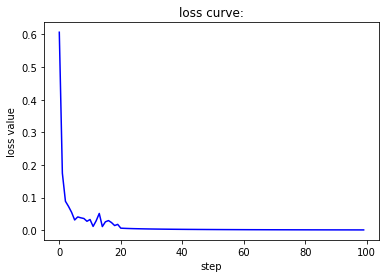
当batch size为1,此时相当于是随机梯度下降,虽然收敛速度较快,但会带来不稳定的问题,也就是两条曲线在收敛过程中并不单调而是上下波动。当batch size为1,此时相当于是批梯度下降,虽然收敛较为稳定,但也会带来经过较多的epoch之后才能收敛到一个较好值的缺陷。而第三种处理方式对这两者进行了调和,既尽量保证收敛的稳定性,又能很快地达到一个较好的结果。
使用SGD优化器,并尝试momentum=0, momentum=0.9两种情况, 阐述momentum对loss值以及accuracy值的影响。
if __name__ == '__main__':
'''
change train epoches here
'''
# number of training
epoches = 100
'''
change learning rate here
'''
# learning rate
# 1e-4 = e^-4
lr = 1e-2
'''
change batch size here
'''
# batch size
batch_size = 70
# define a transform to pretreat data
transform = torch.tensor
# define a gpu device
device = torch.device('cpu')
# define a trainset
trainset = PointDataset('./labels/train.csv', transform=transform)
# define a trainloader
trainloader = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=4)
# define a testset
testset = PointDataset('./labels/test.csv', transform=transform)
# define a testloader
testloader = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False, num_workers=4)
show_original_points()
# define a network
classifier_net = Network(2, 5, 3).to(device)
'''
change optimizer here
'''
# define a optimizer
optimizer = optim.SGD(classifier_net.parameters(), lr=lr, momentum=0)
# get trained model
classifier_net = train(classifier_net, trainloader, testloader, device, lr, optimizer,)

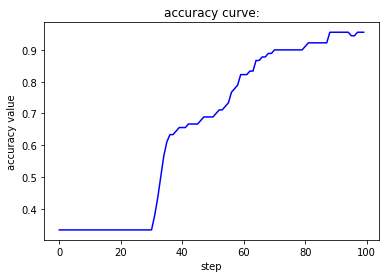
if __name__ == '__main__':
'''
change train epoches here
'''
# number of training
epoches = 100
'''
change learning rate here
'''
# learning rate
# 1e-4 = e^-4
lr = 1e-2
'''
change batch size here
'''
# batch size
batch_size = 70
# define a transform to pretreat data
transform = torch.tensor
# define a gpu device
device = torch.device('cpu')
# define a trainset
trainset = PointDataset('./labels/train.csv', transform=transform)
# define a trainloader
trainloader = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=4)
# define a testset
testset = PointDataset('./labels/test.csv', transform=transform)
# define a testloader
testloader = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False, num_workers=4)
show_original_points()
# define a network
classifier_net = Network(2, 5, 3).to(device)
'''
change optimizer here
'''
# define a optimizer
optimizer = optim.SGD(classifier_net.parameters(), lr=lr, momentum=0.9)
# get trained model
classifier_net = train(classifier_net, trainloader, testloader, device, lr, optimizer,)
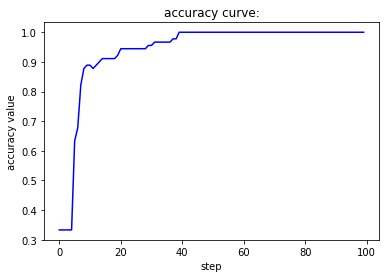
momentum的含义在于,每一步的梯度下降都会有一个来自于曾经梯度下降方向的初速度,从而加速梯度收敛。当momentum为0时,对应的数学含义就是,梯度下降里面的每一步都只能依赖这一步计算出来的梯度值来更新参数。当momentum 为0.9,就可以较好地利用以前计算出来的梯度来加速收敛。
使用Adam,Rprop优化器,观察两种曲线,阐述SGD,Adam,Rprop三种优化器对loss值以及accuracy值的影响.
if __name__ == '__main__':
'''
change train epoches here
'''
# number of training
epoches = 100
'''
change learning rate here
'''
# learning rate
# 1e-4 = e^-4
lr = 1e-2
'''
change batch size here
'''
# batch size
batch_size = 70
# define a transform to pretreat data
transform = torch.tensor
# define a gpu device
device = torch.device('cpu')
# define a trainset
trainset = PointDataset('./labels/train.csv', transform=transform)
# define a trainloader
trainloader = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=4)
# define a testset
testset = PointDataset('./labels/test.csv', transform=transform)
# define a testloader
testloader = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False, num_workers=4)
show_original_points()
# define a network
classifier_net = Network(2, 5, 3).to(device)
'''
change optimizer here
'''
# define a optimizer
optimizer = optim.Adam(classifier_net.parameters(), lr=lr)
# get trained model
classifier_net = train(classifier_net, trainloader, testloader, device, lr, optimizer,)
if __name__ == '__main__':
'''
change train epoches here
'''
# number of training
epoches = 100
'''
change learning rate here
'''
# learning rate
# 1e-4 = e^-4
lr = 1e-2
'''
change batch size here
'''
# batch size
batch_size = 70
# define a transform to pretreat data
transform = torch.tensor
# define a gpu device
device = torch.device('cpu')
# define a trainset
trainset = PointDataset('./labels/train.csv', transform=transform)
# define a trainloader
trainloader = DataLoader(dataset=trainset, batch_size=batch_size, shuffle=True, num_workers=4)
# define a testset
testset = PointDataset('./labels/test.csv', transform=transform)
# define a testloader
testloader = DataLoader(dataset=testset, batch_size=batch_size, shuffle=False, num_workers=4)
show_original_points()
# define a network
classifier_net = Network(2, 5, 3).to(device)
'''
change optimizer here
'''
# define a optimizer
optimizer = optim.Rprop(classifier_net.parameters(), lr=lr)
# get trained model
classifier_net = train(classifier_net, trainloader, testloader, device, lr, optimizer,)
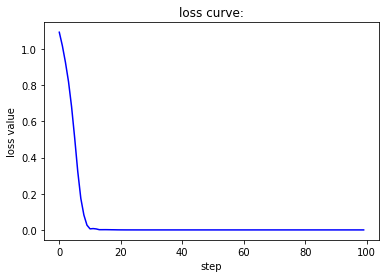
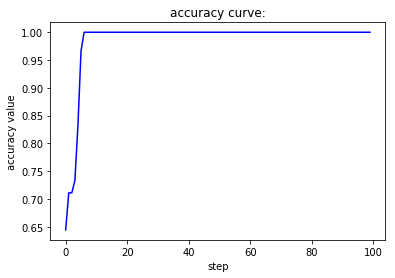
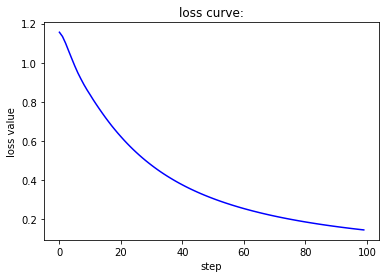
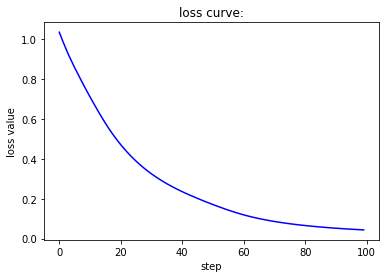
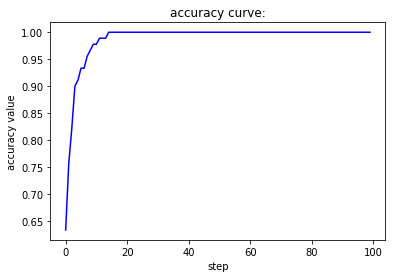
Adam优化器能让loss值平滑下降,accu值快速上升。Rprop优化器能使loss值极快收敛,accu值也极快收敛。
关于加载人脸识别的数据
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
plt.ion() # interactive mode
打印标注点
# read a csv file by pandas
landmarks_frame = pd.read_csv('data/faces/face_landmarks.csv')
n = 0
# read image name, image name was saved in column 1.
img_name = landmarks_frame.iloc[n, 0]
# points were saved in columns from 2 to the end
landmarks = landmarks_frame.iloc[n, 1:].as_matrix()
# reshape the formate of points
landmarks = landmarks.astype('float').reshape(-1, 2)
print('Image name: {}'.format(img_name))
print('Landmarks shape: {}'.format(landmarks.shape))
print('First 4 Landmarks: {}'.format(landmarks[:4]))
Image name: 0805personali01.jpg
Landmarks shape: (68, 2)
First 4 Landmarks: [[ 27. 83.]
[ 27. 98.]
[ 29. 113.]
[ 33. 127.]]
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:8: FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
plt.pause(0.001) # pause a bit so that plots are updated
plt.figure()
show_landmarks(io.imread(os.path.join('data/faces/', img_name)),
landmarks)
plt.show()

## 定义文件读取和显示类
class FaceLandmarksDataset(Dataset):
def __init__(self, csv_file, root_dir, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
# combine the relative path of images
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)
# save all data we may need during training a network in a dict
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
Note(very important):
to define a dataset, first we must to inherit the class torch.utils.data.Dataset. when we write ourselves dataset, it’s neccesarry for us to overload the __init__ method, __len__ method, and __getitem__ method. Of course you can define other method as you like.
使用类
face_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',
root_dir='data/faces/')
fig = plt.figure()
for i in range(len(face_dataset)):
sample = face_dataset[i]
print(i, sample['image'].shape, sample['landmarks'].shape)
# create subgraph
ax = plt.subplot(1, 4, i + 1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample)
if i == 3:
plt.show()
break
0 (324, 215, 3) (68, 2)
/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:22: FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.

1 (500, 333, 3) (68, 2)

2 (250, 258, 3) (68, 2)

3 (434, 290, 3) (68, 2)
