通过前几篇博客的分享,对CIFAR10数据集进行了基本的介绍,同时用代码实践阐述了机器学习中批次训练的重要性 CIFAR-10数据集详解与可视化-CSDN博客 机器学习为什么要分批次训练?-CSDN博客
那么这篇博客就跟大家分享一下如何搭建自己的神经网络模型进行训练
神经网络结构

神经网络是一种模拟人脑神经元行为的数学模型,它能够通过学习和模拟复杂输入输出关系。神经网络是机器学习领域中一种重要的模型,被广泛应用于诸如图像识别、自然语言处理和预测分析等任务。 一个神经网络由以下几部分构成:
- 输入层(Input Layer):输入层接收输入特征,并将这些特征传递给下一层。输入特征的数目取决于问题的具体情况,例如在图像处理中,输入特征可能是图像的像素值。
- 隐藏层(Hidden Layer):隐藏层位于输入层和输出层之间,可以有一层或者多层。每一层都由许多神经元(节点)组成,每个神经元可以视作一个进行某种数学运算的函数,如sigmoid、ReLU等。这个神经元会接收来自前一层的输入(每个输入与一个权重相乘,再加上一个偏置项),应用这个函数,然后将结果传递给下一层。隐藏层的深度和宽度可以根据任务的需要变化,但一般而言,层数和神经元数量越多,模型的复杂度就越高。
- 输出层(Output Layer):输出层是神经网络的最后一层,它将隐藏层的结果转化为我们想要的最终输出结果。这个转化过程通常涉及一个适用于任务的特定激活函数,比如softmax函数用于分类问题,sigmoid函数用于二分类问题,线性函数用于回归问题等。
- 激活函数(Activation Function):在神经网络中,激活函数非常重要,它给神经网络添加了非线性特性,使得神经网络能逼近任意复杂的函数,扩展了模型的表达能力。常见的激活函数有Sigmoid、Tanh、ReLU(Rectified Linear Unit)等。
- 权重和偏置(Weights and Biases):这些是神经网络训练过程中需要学习的参数。每个神经元的输入都会与一个权重相乘,然后加上一个偏置项,然后输入到激活函数里面。
- 损失函数(Loss Function):损失函数用来衡量模型的预测结果与真实值之间的偏差,是优化的目标。例如,回归任务中常用的均方误差(Mean Squared Error),分类任务中常用的交叉熵损失(Cross-Entropy Loss)等。
- 优化器(Optimizer):优化器是用来调整网络中权重和偏置,以最小化损失函数的一种方法。常见的优化器有梯度下降(Gradient Descent), 随机梯度下降(SGD), Adam等。
神经网络的结构可以有很多种,例如全连接神经网络(Fully Connected Neural Networks, FCN)、卷积神经网络(Convolutional Neural Networks, CNN)、循环神经网络(Recurrent Neural Networks, RNN)等,它们在结构上各有特点但原理基本一致。本篇博客就从最简单的全连接神经网络开始介绍在pytorch上搭建神经网络
代码实现
需要导入的库
import torch
import torch.nn as nn
import torch.nn.functional as F搭建神经网络模型的方法非常地灵活,这里介绍最常使用的继承nn中类的方式进行搭建
class Net(nn.Module):
def __init__(self,input_dim,layer1_dim,layer2_dim,output_dim):
super(Net,self).__init__()
self.flatten = nn.Flatten()
self.layer1 = nn.Sequential(nn.Linear(input_dim,layer1_dim),nn.ReLU())
self.layer2 = nn.Sequential(nn.Linear(layer1_dim,layer2_dim),nn.ReLU())
self.out = nn.Sequential(nn.Linear(layer2_dim,output_dim),nn.ReLU())
def forward(self,x):
x = self.flatten(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.out(x)
return x这里搭建了比较简单的含有两个隐含层的全连接神经网络,nn.Flatten()是将输入的数据所有维度进行拉伸到同一纬度下,也就是拉伸到input_dim的维度,nn.Linear()是定义全连接层,两个参数分别是输入维度与输出维度,nn.ReLU()是对应relu激活函数,nn.Sequential()是将多个nn定义的操作复合统一起来,具体到我们的代码中,就是将全连接层的操作与激活函数的操作连接起来,统一到定义的layer中进行操作,我们在调用layer()函数的时候,输入的数据就会依次进行全连接变换和激活函数变换
在神经网络的搭建中灵活使用nn.Sequential()可以使得代码简洁易懂
forward()函数就是类里面的正向传播函数,x是函数传进来需要进行神经网络变换的数据,函数中调用在魔术方式里定义好的变换操作从而得到输出值,最后返回x
我们来初始化网络打印输出看一下
# 初始化网络中的值
input_dim,layer1_dim,layer2_dim,output_dim=32*32,512,128,10
model = Net(input_dim,layer1_dim,layer2_dim,output_dim)
print(model)输出结果
Net(
(flatten): Flatten(start_dim=1, end_dim=-1)
(layer1): Sequential(
(0): Linear(in_features=1024, out_features=512, bias=True)
(1): ReLU()
)
(layer2): Sequential(
(0): Linear(in_features=512, out_features=128, bias=True)
(1): ReLU()
)
(out): Sequential(
(0): Linear(in_features=128, out_features=10, bias=True)
(1): ReLU()
)
)可见网络模型的结构符合我们的设想,输入层为32*32,隐藏层1为512,隐藏层2为128,输出层为10,各层通过激活函数Relu进行输出
我们来实际送入数据试试看
# 定义输出模型的数据
input_data = torch.rand(1,32,32)
# 模型输出的数据
output_data = model(input_data)
print(output_data)随机产生一个(1,32,32)维度的数据送入模型,因为网络模型中的nn.Flatten()展平函数为适应机器学习的任务,期望的输入形状是 (N, input_dim),其中 N 是批次大小,input_dim 是输入的特征数量,所以不能直接送入32*32的数据,这里的input_data可以解释成一个批次大小为1的32*32的数据
输出结果
tensor([[0.0000, 0.0726, 0.0313, 0.0254, 0.0000, 0.0000, 0.0443, 0.0524, 0.0000,
0.0000]], grad_fn=<ReluBackward0>)可见output_data是一个10*1的tensor数据,符合我们对于模型的设计思路,grad_fn表示梯度,在进行模型训练的时候通过梯度可以得到损失函数值下降的方向,从而更新模型的参数
本篇博客主要介绍搭建神经网络的步骤以及涉及的代码,关于模型的迭代优化和参数更新在后续的博客会继续分享~
模型可视化
使用pytorch的tensorboard工具将上面搭建的全连接网络可视化
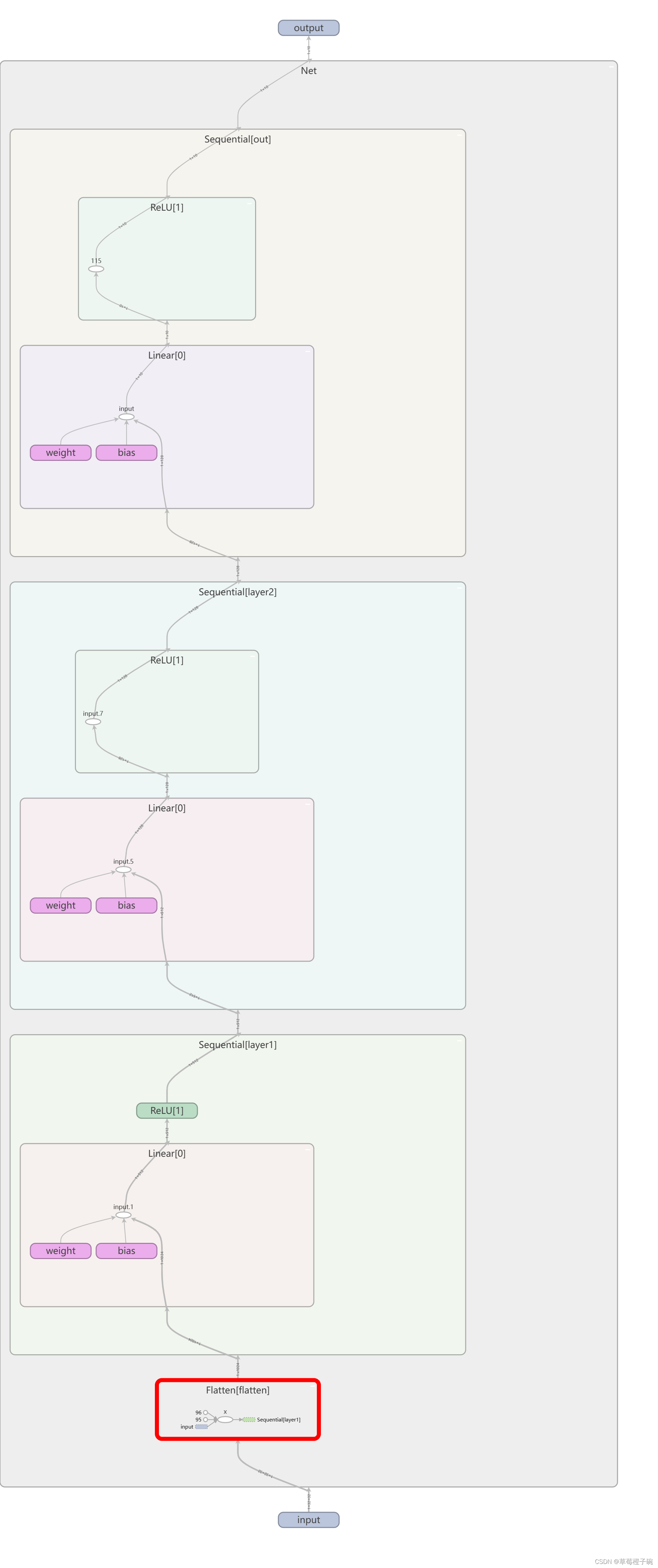
欢迎大家讨论交流~