版权为吴恩达老师所有,参考Koala_Tree的博客,部分根据自己实践添加
使用google翻译,部分手工翻译
你可能需要的参考资料https://pan.baidu.com/s/1vcktD7DuDyEBKYSZkvHUew
第1部分:卷积神经网络:循序渐进
欢迎来到课程4的第一个作业!在此分配中,您将实现numpy中的卷积(CONV)和池化(POOL)层,包括前向传播和(可选)向后传播。
符号:
- 上标表示
层的对象。
- 示例:一个
图层激活。
和
是
图层参数。
-
上标
表示来自
例子的一个对象。
- 示例:
是
- 示例:
-
下标
表示
- 示例:
]表示第
层的
- 示例:
-
,
和
分别表示给定层的高度,宽度和通道数。如果要指定特定图层
,
,
.
,
和
分别表示前一层的高度,宽度和通道数。如果指定特定层
,
,
.
我们假设您已经熟悉numpy和/或已完成以前的专业课程。让我们开始吧!
1 - 包裹
让我们首先导入在此分配期间您需要的所有包。
- numpy是使用Python进行科学计算的基础包。
- matplotlib是一个用Python绘制图形的库。
- np.random.seed(1)用于保持所有随机函数调用一致。它将帮助我们评估您的工作。
import numpy as np
import h5py
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (5.0, 4.0)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
np.random.seed(1)2 - 作业概要
您将实现卷积神经网络的构建块!您将实现的每个功能都将提供详细说明,指导您完成所需的步骤:
- 卷积功能,包括:
- 零填充
- 卷积窗口
- 卷积前进
- 向后卷积(可选)
- 汇集功能,包括:
- 汇集前进
- 创建面具
- 分配价值
- 向后汇集(可选)
这将要求您从头开始实现这些功能通过numpy扩展。在下一个任务中,您将使用这些函数的TensorFlow等效项来构建以下模型:
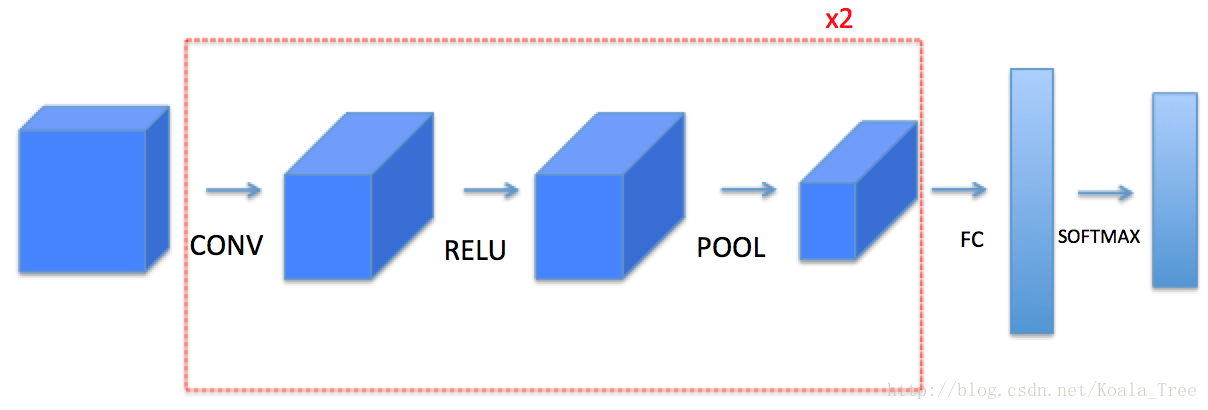
请注意,对于每个正向函数,都有相应的向后函数等价。因此,在正向传播的每个步骤中,您都会将一些参数存储在缓存中。这些参数用于计算反向传播期间的梯度。
3 - 卷积神经网络
虽然编程框架使得卷积易于使用,但它们仍然是深度学习中最难理解的概念之一。卷积层将输入转换为不同大小的输出,如下所示。
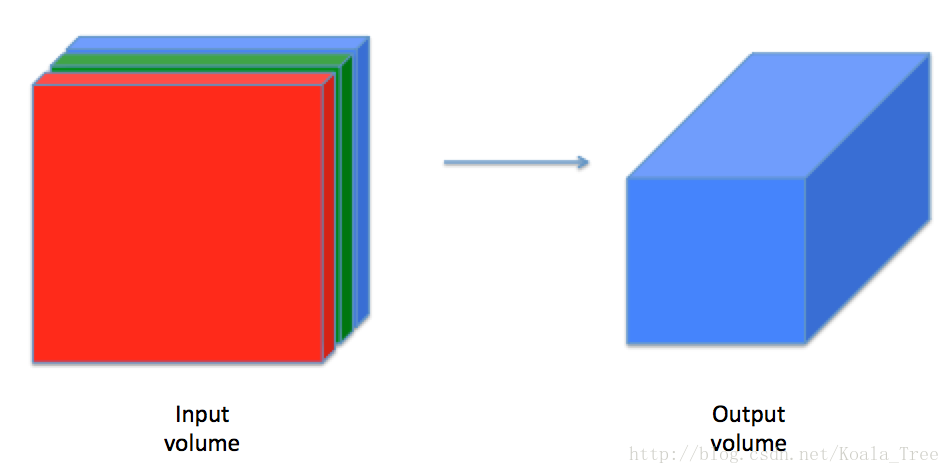
在这一部分中,您将构建卷积层的每个步骤。您将首先实现两个辅助函数:一个用于零填充,另一个用于计算卷积函数本身。
3.1 - 零填充
零填充在图像边框周围添加零:
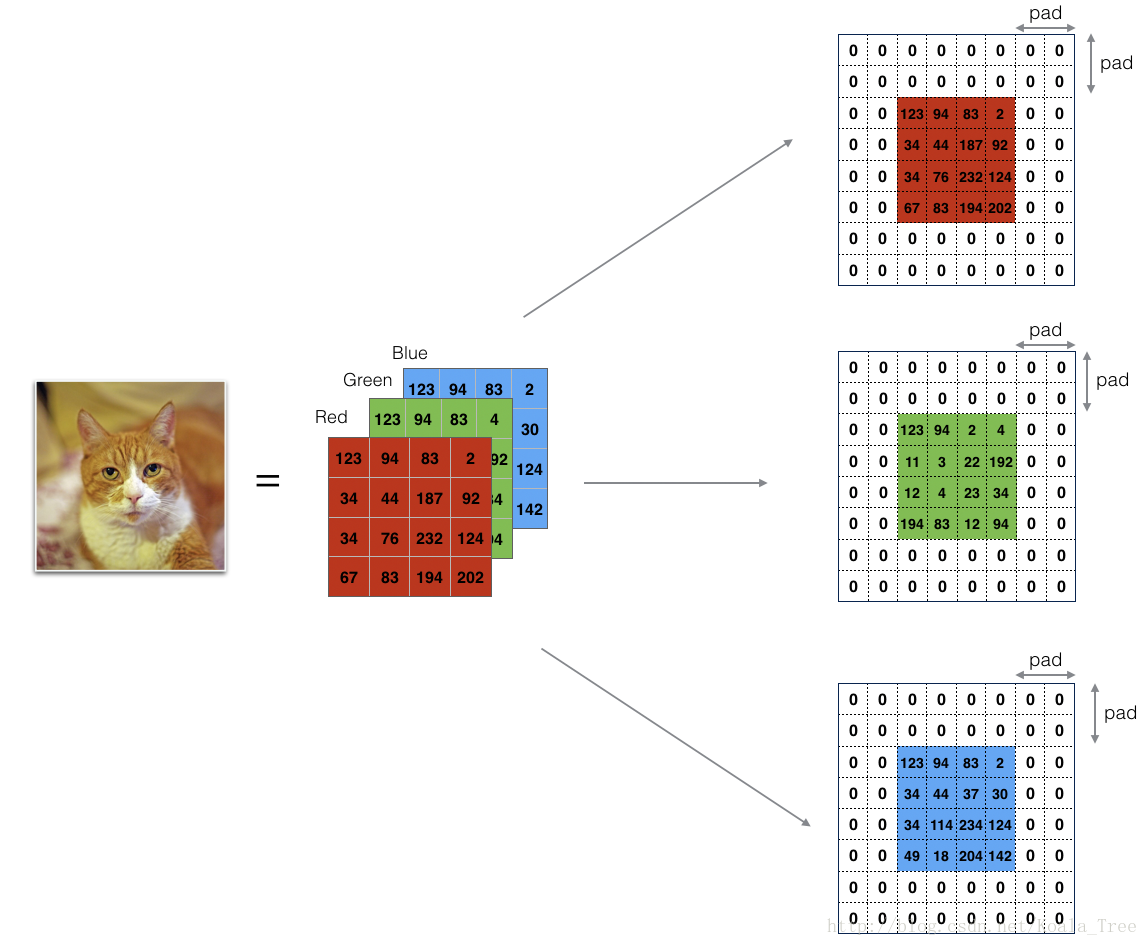
图1 :零填充
图像(3通道,RGB),填充为2。
填充的主要好处如下:
-
它允许您使用CONV层而不必缩小卷的高度和宽度。这对于构建更深的网络非常重要,否则高度/宽度会随着您进入更深层而缩小。一个重要的特殊情况是“相同”卷积,其中高度/宽度在一层之后精确保留。
-
它可以帮助我们将更多信息保存在图像的边界。如果没有填充,则下一层中的极少数值会受到像素作为图像边缘的影响。
练习:实现以下功能,该功能用零填充一批示例X的所有图像。使用np.pad。请注意,如果你想填充数组“a”,形状为(5,5,5,5,5)同时pad = 1为第二维,pad = 3为第四维,剩下的为pad = 0,你应该这么做:
a = np.pad(a, ((0,0), (1,1), (0,0), (3,3), (0,0)), 'constant', constant_values = (..,..))def zero_pad(X,pad):
X_pad=np.pad(X,((0,0),(pad,pad),(pad,pad),(0,0)),"constant")
return X_padnp.random.seed(1)
x = np.random.randn(4, 3, 3, 2)
x_pad = zero_pad(x, 2)
print ("x.shape =", x.shape)
print ("x_pad.shape =", x_pad.shape)
print ("x[1,1] =", x[1,1])
print ("x_pad[1,1] =", x_pad[1,1])
fig, axarr = plt.subplots(1, 2)
axarr[0].set_title('x')
axarr[0].imshow(x[0,:,:,0])
axarr[1].set_title('x_pad')
axarr[1].imshow(x_pad[0,:,:,0])
plt.show()
3.2 - 单步的卷积
在此部分中,实现卷积的单个步骤,其中将过滤器应用于输入的单个位置。这将用于构建卷积单元,其中:
- 获取输入大小
- 在输入的每个位置应用过滤器
- 输出另一个数组(通常是不同大小)
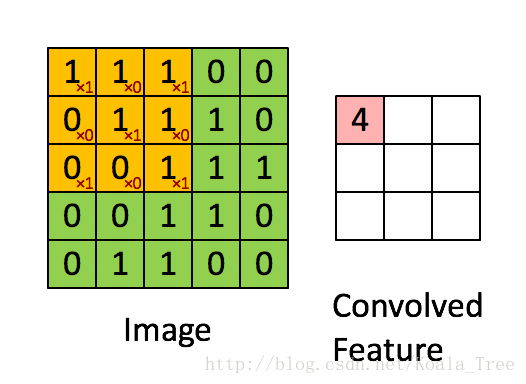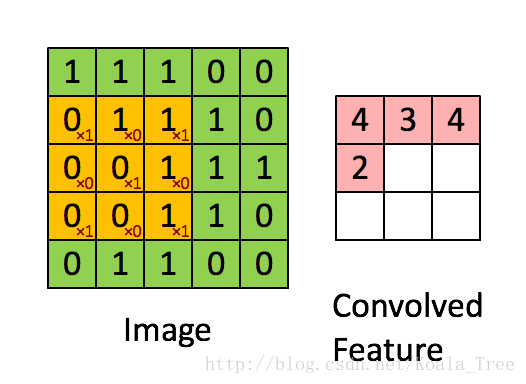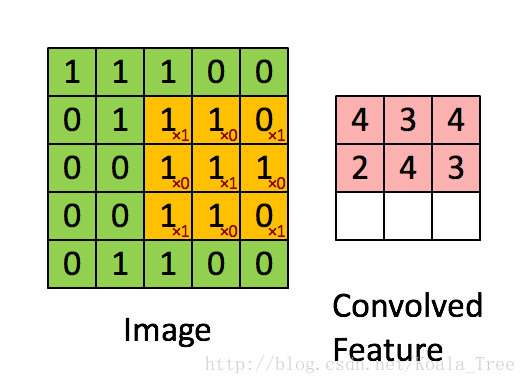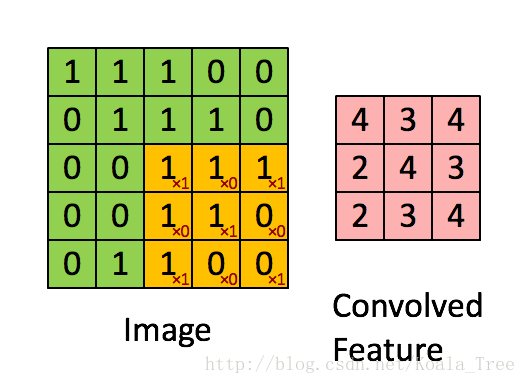
图2 :使用2x2的滤波器和1的步幅进行卷积运算
(每次滑动时,步幅=移动窗口的量)
在计算机视觉应用中,左侧矩阵中的每个值对应于单个像素值,我们通过将其值与元素的原始矩阵相乘,然后将它们相加并添加偏差,将3x3滤波器与图像卷积在一起。 。在练习的第一步中,您将实现一个卷积步骤,对应于将滤波器应用于其中一个位置以获得单个实值输出。
稍后在本笔记本中,您将此功能应用于输入的多个位置以实现完整的卷积操作。
练习:实现conv_single_step()。提示。
def conv_single_step(a_slice_prev,W,b):
s=a_slice_prev*W
Z=np.sum(s)
Z=Z+b
return Znp.random.seed(1)
a_slice_prev = np.random.randn(4, 4, 3)
W = np.random.randn(4, 4, 3)
b = np.random.randn(1, 1, 1)
Z = conv_single_step(a_slice_prev, W, b)
print("Z =", Z)3.3 - 卷积神经网络 - 前向传递
在前向传递中,您将采用许多过滤器并在输入上进行卷积。每个'卷积'为您提供2D矩阵输出。然后,您将堆叠这些输出以获得3D体积:
练习:实现下面的函数以在输入激活A_prev上卷积滤波器W. 该函数将输入A_prev,前一层输出的激活(对于一批m个输入),由W表示的F滤波器/权重,以及由b表示的偏差矢量,其中每个滤波器具有其自己的(单个)偏差。最后,您还可以访问包含步幅和填充的超参数字典。
提示:
1。要在矩阵“a_prev”(形状(5,5,3))的左上角选择2x2切片,您可以:
a_slice_prev = a_prev[0:2,0:2,:]当您使用要定义a_slice_prev的start/end索引定义下面的内容时,这将非常有用。
2.要定义a_slice你需要先定义它的边角vert_start,vert_end,horiz_start和horiz_end。这个数字可能有助于您在下面的代码中找到如何定义使用h,w,f和s的地方。
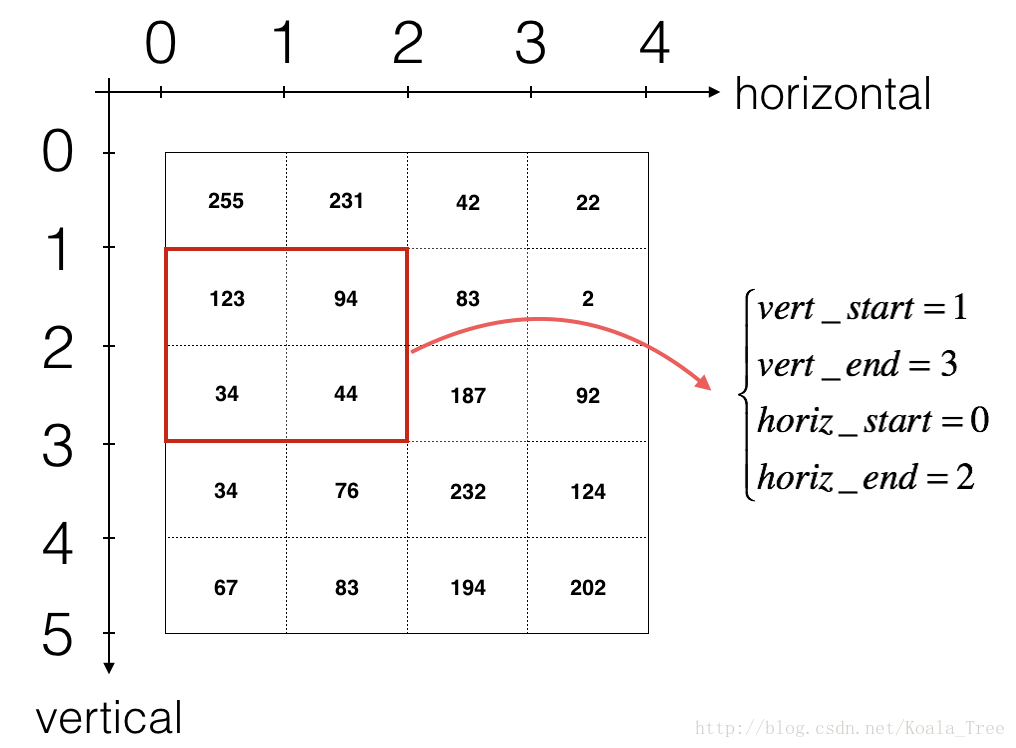
图3 :使用垂直和水平开始/结束(使用2x2滤波器)定义切片
此图仅显示单个通道。
提醒:
将卷积的输出形状与输入形状相关的公式为:

对于本练习,我们不会担心向量化,而只会使用for循环实现所有内容。
def conv_forward(A_prev,W,b,hparameter):
(m,n_H_prev,n_W_prev,n_C_prev)=A_prev.shape
(f,f,n_C_prev,n_C)=W.shape
stride=hparameter["stride"]
pad=hparameter["pad"]
n_H=int((n_H_prev-f+2*pad)/stride+1)
n_W=int((n_W_prev-f+2*pad)/stride+1)
Z=np.zeros((m,n_H,n_W,n_C))
A_prev_pad=zero_pad(A_prev,pad)
for i in range(m):
a_prev_pad=A_prev_pad[i,:,:,:]
for h in range(n_H):
for w in range(n_W):
for c in range(n_C):
vert_start=stride*h
vert_end=vert_start+f
horiz_start=stride*w
horiz_end=horiz_start+f
a_slice_prev=a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]
Z[i,h,w,c]=conv_single_step(a_slice_prev,W[:,:,:,c],b[:,:,:,c])
assert(Z.shape==(m,n_H,n_W,n_C))
cache=(A_prev,W,b,hparameter)
return Z,cachenp.random.seed(1)
A_prev = np.random.randn(10,4,4,3)
W = np.random.randn(2,2,3,8)
b = np.random.randn(1,1,1,8)
hparameters = {"pad" : 2,
"stride": 2}
Z, cache_conv = conv_forward(A_prev, W, b, hparameters)
print("Z's mean =", np.mean(Z))
print("Z[3,2,1] =", Z[3,2,1])
print("cache_conv[0][1][2][3] =", cache_conv[0][1][2][3])最后,CONV层还应包含激活,在这种情况下,我们将添加以下代码行:
#位于"Z[i,h,w,c]=conv_single_step(a_slice_prev,W[:,:,:,c],b[:,:,:,c])"之后
A[i, h, w, c] = activation(Z[i, h, w, c])
你不需要在这里做。
4 - 池层
池(POOL)层减小了输入的高度和宽度。它有助于减少计算,并有助于使特征检测器在输入中的位置更加不变。两种类型的汇集层是:
-
最大汇集层:滑动(f,f)输入窗口并在输出中存储窗口的最大值。
-
平均合并层:滑动(f,f)窗口在输入上并存储窗口在输出中的平均值。
| |
|
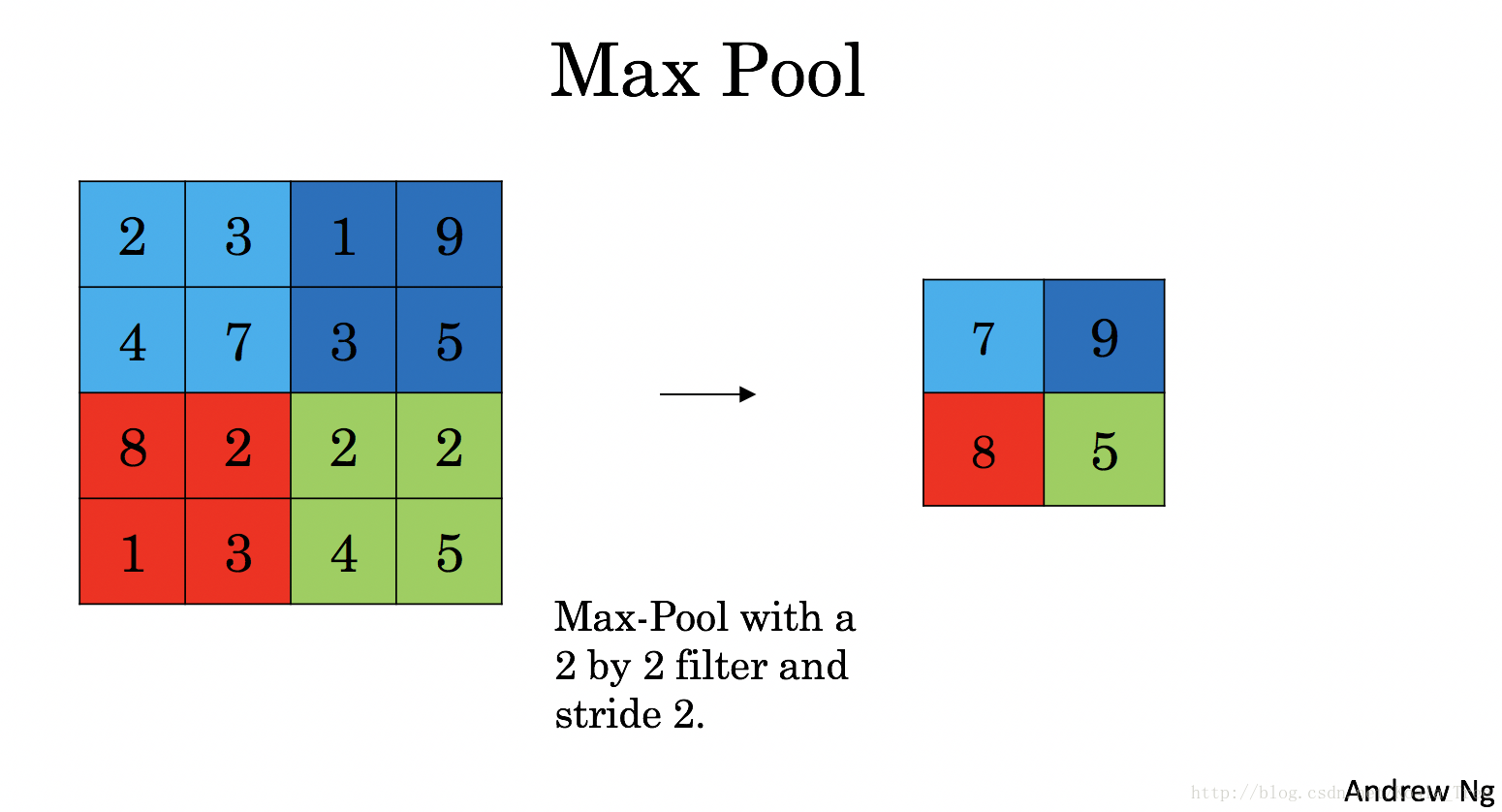
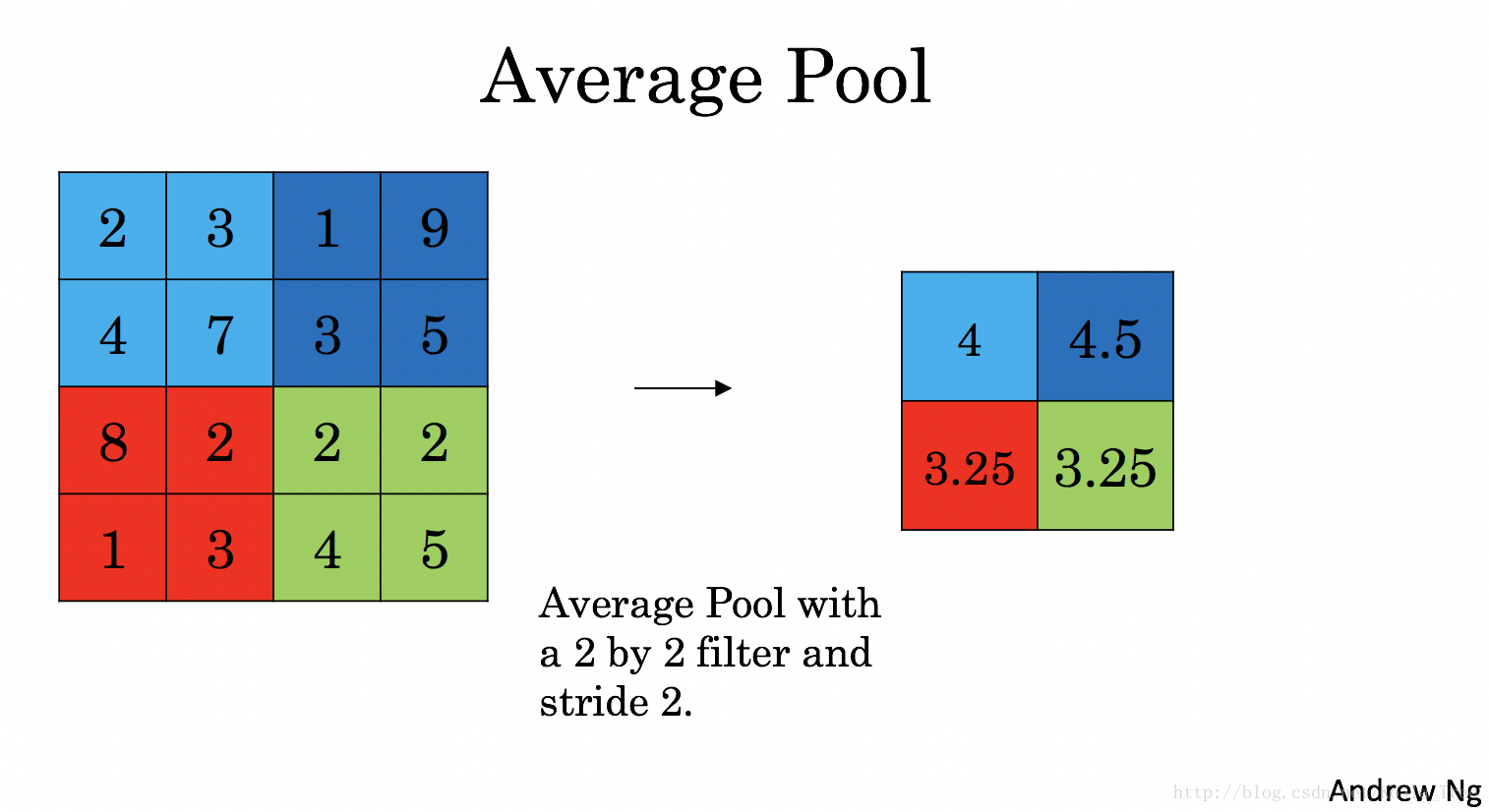
这些汇集层没有用于训练的反向传播的参数。但是,它们具有超参数,例如窗口大小f。这指定了您计算最大值或平均值的fxf窗口的高度和宽度。
4.1 - 前向池
现在,您将在同一功能中实现MAX-POOL和AVG-POOL。
练习:实现池化层的前向传递。请遵循以下评论中的提示。
提醒:
由于没有填充,将池的输出形状绑定到输入形状的公式为:

def pool_forward(A_prev,hparameters,mode="max"):
(m,n_H_prev,n_W_prev,n_C_prev)=A_prev.shape
f=hparameters["f"]
stride=hparameters["stride"]
n_H=int(1+(n_H_prev-f)/stride)
n_W=int(1+(n_W_prev-f)/stride)
n_C=n_C_prev
A=np.zeros((m,n_H,n_W,n_C))
for i in range(m):
for h in range(n_H):
for w in range(n_W):
for c in range(n_C):
vert_start=h*stride
vert_end=vert_start+f
horiz_start=w*stride
horiz_end=horiz_start+f
a_prev_slice=A_prev[i,vert_start:vert_end,horiz_start:horiz_end,c]
if mode=="max":
A[i,h,w,c]=np.max(a_prev_slice)
elif mode=="average":
A[i,h,w,c]=np.mean(a_prev_slice)
cache=(A_prev,hparameters)
assert(A.shape==(m,n_H,n_W,n_C))
return A,cachenp.random.seed(1)
A_prev = np.random.randn(2, 4, 4, 3)
hparameters = {"stride" : 2, "f": 3}
A, cache = pool_forward(A_prev, hparameters)
print("mode = max")
print("A =", A)
print()
A, cache = pool_forward(A_prev, hparameters, mode = "average")
print("mode = average")
print("A =", A)
恭喜!您现在已经实现了卷积网络的所有层的前向传递。
5 - 卷积神经网络中的反向传播(可选/未分级)
在现代深度学习框架中,您只需要实现前向传递,并且框架负责向后传递,因此大多数深度学习工程师不需要为后向传递的细节而烦恼。卷积网络的反向传递很复杂。但是,如果您愿意,可以通过这个可选部分来了解卷积网络中的backprop。
在早期课程中,您实现了一个简单(完全连接)的神经网络,您使用反向传播来计算与更新参数的成本相关的导数。类似地,在卷积神经网络中,您可以计算与成本相关的导数,以便更新参数。backprop方程并不简单,我们没有在课程中得出它们,但我们在下面简要介绍它们。
5.1 - 卷积层向后传递
让我们从实现CONV层的反向传递开始。
5.1.1 - Computing dA:
这是计算的公式对于特定的过滤器
的成本和一个给定的训练样例:
当是一个过滤器同时
对应于相对于第h行和第w列的conv层Z的输出的成本的梯度的标量(对应于在第i个步幅左和第j个步幅下采取的点积)。请注意,每次我们将相同的滤波器
乘以不同的
来更新dA。我们这样做主要是因为在计算前向传播时,每个滤波器都是由不同的a_slice点乘和求和的。因此,在为dA计算backprop时,我们只是添加所有a_slices的梯度。
在代码中,在适当的for循环中,此公式转换为:
da_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :] += W[:,:,:,c] * dZ[i, h, w, c]5.1.2 - 计算dW:
这是计算的公式对于特定的过滤器
:
正如您之前在基本神经网络中看到的那样,是通过
求和来计算的。在这种情况下,您只是对成本对转换输出(Z)的所有梯度求和。
在代码中,在适当的for循环中,此公式转换为:
db[:,:,:,c] += dZ[i, h, w, c]练习:实现以下conv_backward功能。您应该总结所有训练示例,过滤器,高度和宽度。然后,您应该使用上面的公式来计算导数。
def conv_backward(dZ,cache):
(A_prev,W,b,hparameters)=cache
(m,n_H_prev,n_W_prev,n_C_prev)=A_prev.shape
(f,f,n_C_prev,n_C)=W.shape
stride=hparameters["stride"]
pad=hparameters["pad"]
(m,n_H,n_W,n_C)=dZ.shape
dA_prev=np.zeros((m,n_H_prev,n_W_prev,n_C_prev))
dW=np.zeros((f,f,n_C_prev,n_C))
db=np.zeros((1,1,1,n_C))
A_prev_pad=zero_pad(A_prev,pad)
dA_prev_pad=zero_pad(dA_prev,pad)
for i in range(m):
a_prev_pad=A_prev_pad[i,:,:,:]
da_prev_pad=dA_prev_pad[i,:,:,:]
for h in range(n_H):
for w in range(n_W):
for c in range(n_C):
vert_start=h*stride
vert_end=vert_start+f
horiz_start=w*stride
horiz_end=horiz_start+f
a_slice=a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]
da_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]+=W[:,:,:,c]*dZ[i,h,w,c]
dW[:,:,:,c]+=a_slice*dZ[i,h,w,c]
db[:,:,:,c]+=dZ[i,h,w,c]
dA_prev[i,:,:,:]=da_prev_pad[pad:-pad,pad:-pad,:]
assert(dA_prev.shape==(m,n_H_prev,n_W_prev,n_C_prev))
return dA_prev,dW,dbnp.random.seed(1)
A_prev = np.random.randn(10,4,4,3)
W = np.random.randn(2,2,3,8)
b = np.random.randn(1,1,1,8)
hparameters = {"pad" : 2,
"stride": 2}
Z, cache_conv = conv_forward(A_prev, W, b, hparameters)
dA, dW, db = conv_backward(Z, cache_conv)
print("dA_mean =", np.mean(dA))
print("dW_mean =", np.mean(dW))
print("db_mean =", np.mean(db))5.2池层 - 向后传播
接下来,让我们从MAX-POOL层开始实现池化层的反向传递。尽管池化层没有用于更新backprop的参数,但您仍需要通过池化层反向传播渐变,以便计算在池化层之前的层的渐变。
5.2.1最大池 - 向后传播
在跳转到池化层的反向传播之前,您将构建一个名为helper的函数create_mask_from_window(),该函数执行以下操作:
如您所见,此函数创建一个“掩码”矩阵,用于跟踪矩阵的最大值。True(1)表示X中最大值的位置,其他条目为False(0)。稍后您会看到平均合并的向后传递将与此类似,但使用不同的掩码。
练习:实施create_mask_from_window()。此功能有助于向后传播。
提示:
- np.max()可能会有所帮助。它计算数组的最大值。
- 如果你有一个矩阵X和一个标量x:A = (X == x)将返回一个与X大小相同的矩阵A,这样:
A[i,j] = True if X[i,j] = x
A[i,j] = False if X[i,j] != x- 在这里,您不需要考虑矩阵中有多个最大值的情况。
def create_mask_from_window(x):
mask=(x==np.max(x))
return masknp.random.seed(1)
x = np.random.randn(2,3)
mask = create_mask_from_window(x)
print('x = ', x)
print("mask = ", mask)为什么我们要记录最大的位置?这是因为这是最终影响输出的输入值,因此也影响了成本。Backprop计算与成本有关的梯度,因此影响最终成本的任何事物都应该具有非零梯度。因此,backprop会将渐变“传播”回到影响成本的特定输入值。
5.2.2 - 平均合并 - 向后传递
在最大池中,对于每个输入窗口,输出上的所有“影响”来自单个输入值 - 最大值。在平均池中,输入窗口的每个元素对输出具有相同的影响。因此,要实现backprop,您现在将实现一个反映此功能的辅助函数。
例如,如果我们使用2x2过滤器在前向传递中进行平均合并,那么您将用于向后传递的掩码将如下所示:
这意味着矩阵中的每个位置对输出的贡献相等,因为在向前传递中,我们取平均值。
练习:实现下面的函数,通过维度形状矩阵平均分配值dz。提示
def distribute_value(dz,shape):
(n_H,n_W)=shape
average=dz/(n_H*n_W)
a=average*np.ones(shape)
return aa = distribute_value(2, (2,2))
print('distributed value =', a)5.2.3将它们放在一起:向后汇集
您现在拥有了在池化层上计算向后传播所需的一切。
练习:pool_backward在两种模式("max"和"average")中实现该功能。您将再次使用4个for循环(迭代训练示例,高度,宽度和通道)。您应该使用if/elif语句来查看模式是否等于'max'或'average'。如果它等于'average',你应该使用distribute_value()上面实现的函数来创建一个形状相同的矩阵a_slice。否则,模式等于' max',您将创建一个掩码,create_mask_from_window()并将其乘以相应的dZ值。
def pool_backward(dA,cache,mode="max"):
(A_prev,hparameters)=cache
stride=hparameters["stride"]
f=hparameters["f"]
m,n_H_prev,n_W_prev,n_C_prev=A_prev.shape
m,n_H,n_W,n_C=dA.shape
dA_prev=np.zeros(np.shape(A_prev))
for i in range(m):
a_prev=A_prev[i,:,:,:]
for h in range(n_H):
for w in range(n_W):
for c in range(n_C):
vert_start=h*stride
vert_end=vert_start+f
horiz_start=w*stride
horiz_end=horiz_start+f
if mode=="max":
a_prev_slice=a_prev[vert_start:vert_end,horiz_start:horiz_end,c]
mask=create_mask_from_window(a_prev_slice)
dA_prev[i,vert_start:vert_end,horiz_start:horiz_end,c]+=np.multiply(mask,dA[i,h,w,c])
elif mode=="average":
da=dA[i,h,w,c]
shape=(f,f)
dA_prev[i,vert_start:vert_end,horiz_start:horiz_end,c]+=distribute_value(da,shape)
assert(dA_prev.shape==A_prev.shape)
return dA_prevnp.random.seed(1)
A_prev = np.random.randn(5, 5, 3, 2)
hparameters = {"stride" : 1, "f": 2}
A, cache = pool_forward(A_prev, hparameters)
dA = np.random.randn(5, 4, 2, 2)
dA_prev = pool_backward(dA, cache, mode = "max")
print("mode = max")
print('mean of dA = ', np.mean(dA))
print('dA_prev[1,1] = ', dA_prev[1,1])
print()
dA_prev = pool_backward(dA, cache, mode = "average")
print("mode = average")
print('mean of dA = ', np.mean(dA))
print('dA_prev[1,1] = ', dA_prev[1,1]) 恭喜!
祝贺你完成这项任务。您现在了解卷积神经网络的工作原理。您已经实现了神经网络的所有构建块。在下一个任务中,您将使用TensorFlow实现ConvNet。