版权为吴恩达老师所有,参考Koala_Tree的博客,部分根据自己实践添加
使用google翻译,部分手工翻译
你可能需要的参考资料https://pan.baidu.com/s/1y_pb9HiAIBwQVKuMG_ZONw
第2部分:卷积神经网络:应用
欢迎来到课程4的第二个作业!在这个笔记本中,您将:
- 实现在实现TensorFlow模型时将使用的辅助函数
- 使用TensorFlow实现功能完备的ConvNet
完成此任务后,您将能够:
- 在TensorFlow中构建和训练ConvNet以解决分类问题
我们在此假设您已熟悉TensorFlow。如果不是,请参考课程2第三周的TensorFlow教程(“ 改进深度神经网络 ”)。
1.0 - TensorFlow模型
在之前的任务中,您使用numpy构建了辅助函数,以了解卷积神经网络背后的机制。今天深度学习的大多数实际应用都是使用编程框架构建的,编程框架具有许多可以简单调用的内置函数。
像往常一样,我们将从加载包中开始。
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import scipy
from PIL import Image
from scipy import ndimage
import tensorflow as tf
from tensorflow.python.framework import ops
from cnn_utils import *
np.random.seed(1)运行下一个单元格以加载要使用的“SIGNS”数据集。
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()作为提醒,SIGNS数据集是6个符号的集合,表示从0到5的数字。
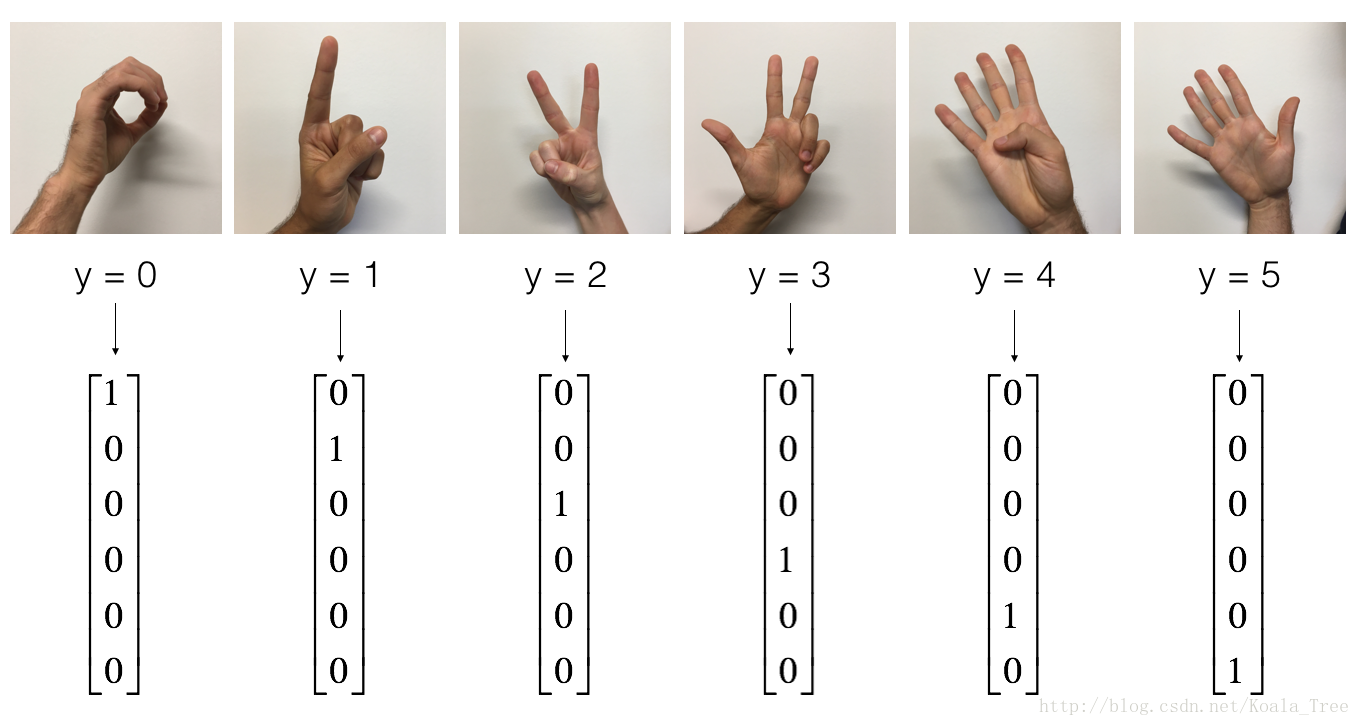
下一个单元格将显示数据集中标记图像的示例。随意更改index下面的值并重新运行以查看不同的示例。
index=4
plt.imshow(X_train_orig[index])
plt.show()
print("y = "+str(np.squeeze(Y_train_orig[:,index])))
在课程2中,您为此数据集构建了一个完全连接的网络。但由于这是一个图像数据集,因此将ConvNet应用于它是更自然的。
首先,让我们检查一下数据的形状。
X_train=X_train_orig/255.0
X_test=X_test_orig/255.0
Y_train=convert_to_one_hot(Y_train_orig,6).T
Y_test=convert_to_one_hot(Y_test_orig,6).T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
conv_layers = {}1.1 - 创建占位符
TensorFlow要求您为输入数据创建占位符,这些输入数据将在运行会话时提供给模型。
练习:实现下面的函数为输入图像X和输出Y创建占位符。您不应该定义当前训练示例的数量。为此,您可以使用“None”作为批量大小,它将使您可以在以后选择它。因此X应该是维度[None,n_H0,n_W0,n_C0],Y应该是维度[None,n_y]。提示。
def create_placeholders(n_H0,n_W0,n_C0,n_y):
X=tf.placeholder(tf.float32,shape=[None,n_H0,n_W0,n_C0])
Y=tf.placeholder(tf.float32,shape=[None,n_y])
return X,YX, Y = create_placeholders(64, 64, 3, 6)
print ("X = " + str(X))
print ("Y = " + str(Y))1.2 - 初始化参数
您将初始化权重/过滤器和
使用
tf.contrib.layers.xavier_initializer(seed = 0)。您不必担心偏差变量,因为您很快就会发现TensorFlow函数会处理偏差。另请注意,您只会初始化conv2d函数的权重/过滤器。TensorFlow自动初始化完全连接部件的层。我们将在本作业后面详细讨论。
练习:实现initialize_parameters()。下面提供了每组过滤器的尺寸。提醒 - 初始化参数W.该 在Tensorflow中的形状[1,2,3,4],使用:
W = tf.get_variable("W", [1,2,3,4], initializer = ...)def initialize_parameters():
tf.set_random_seed(1)
W1=tf.get_variable("W1",[4,4,3,8],initializer=tf.contrib.layers.xavier_initializer(seed=0))
W2=tf.get_variable("W2",[2,2,8,16],initializer=tf.contrib.layers.xavier_initializer(seed=0))
parameters={"W1":W1,
"W2":W2}
return parameterstf.reset_default_graph()
with tf.Session() as sess_test:
parameters=initialize_parameters()
init=tf.global_variables_initializer()
sess_test.run(init)
print("W1 = "+str(parameters["W1"].eval()[1,1,1]))
print("W2 = "+str(parameters["W2"].eval()[1,1,1]))1.2 - 前向传播
在TensorFlow中,有内置函数可以为您执行卷积步骤。
-
tf.nn.conv2d(X,W1,strides = [1,s,s,1],padding ='SAME'):给定输入X和一组过滤器W1,这个函数卷入W1在X上的过滤器。第三个输入([1,f,f,1])表示输入的每个维度的步幅(m,n_H_prev,n_W_prev,n_C_prev)。您可以在此处阅读完整的文档
-
tf.nn.max_pool(A,ksize = [1,f,f,1],strides = [1,s,s,1],padding ='SAME'):给定输入A,此函数使用一个窗口大小(f,f)和大小(s,s)的跨度,以在每个窗口上执行最大池化。您可以在此处阅读完整的文档
-
tf.contrib.layers.flatten(P):给定输入P,此函数将每个示例展平为1D向量,同时保持批量大小。它返回一个形状为[batch_size,k]的平坦张量。您可以在此处阅读完整的文档。
-
tf.contrib.layers.fully_connected(F,num_outputs):给定一个展平的输入F,它返回使用完全连接的层计算的输出。您可以在此处阅读完整的文档。
在上面的最后一个函数(tf.contrib.layers.fully_connected)中,完全连接的图层会自动初始化图形中的权重,并在训练模型时继续训练它们。因此,初始化参数时不需要初始化这些权重。
练习:
实现以下forward_propagation功能以构建以下模型:CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED。您应该使用上述功能。
详细地说,我们将对所有步骤使用以下参数:
- Conv2D:stride 1,padding为“SAME”
- ReLU
- Max pool:使用8 x 8过滤器大小和8 x 8步长,填充为“SAME”
- Conv2D:stride 1,padding为“SAME”
- ReLU
- Max pool:使用4 x 4过滤器大小和4 x 4步长,填充为“SAME”
- 展平前一个输出。
- FULLYCONNECTED(FC)层:应用完全连接的层而不使用非线性激活功能。不要在这里调用softmax。这将导致输出层中的6个神经元,然后将其传递到softmax。在TensorFlow中,softmax和cost函数被集中在一个函数中,在计算成本时,您将在不同的函数中调用它。
def forward_propagation(X,parameters):
W1=parameters["W1"]
W2=parameters["W2"]
Z1=tf.nn.conv2d(X,W1,strides=[1,1,1,1],padding="SAME")
A1=tf.nn.relu(Z1)
P1=tf.nn.max_pool(A1,ksize=[1,8,8,1],strides=[1,8,8,1],padding="SAME")
Z2=tf.nn.conv2d(P1,W2,strides=[1,1,1,1],padding="SAME")
A2=tf.nn.relu(Z2)
P2=tf.nn.max_pool(A2,ksize=[1,4,4,1],strides=[1,4,4,1],padding="SAME")
P2=tf.contrib.layers.flatten(P2)
Z3=tf.contrib.layers.fully_connected(P2,6,activation_fn=None)
return Z3tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
X,Y=create_placeholders(64,64,3,6)
parameters=initialize_parameters()
Z3=forward_propagation(X,parameters)
init=tf.global_variables_initializer()
sess.run(init)
a=sess.run(Z3,{X:np.random.randn(2,64,64,3),Y:np.random.randn(2,6)})
print("Z3 = "+str(a))tips:
1.我在这里计算出的Z3以及下面的cost,与网上公布的数据不同,不过一些网友也出现了这些问题,如果你知道原因,请告诉我,谢谢
2.数据的不同,影响最终的结果1.3 - 计算成本
在下面实现计算成本函数。您可能会发现这两个函数很有用:
- tf.nn.softmax_cross_entropy_with_logits(logits = Z3,labels = Y):计算softmax熵损失。该功能既可以计算softmax激活功能,也可以计算产生的损耗。您可以在此处查看完整的文档 。
- tf.reduce_mean:计算张量维数的元素均值。使用它来总结所有示例的损失以获得总体成本。您可以在此处查看完整的文档。
*练习*:使用上述功能计算以下费用。
def compute_cost(Z3,Y):
cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3,labels=Y))
return cost
tf.reset_default_graph()
with tf.Session() as sess:
np.random.seed(1)
X,Y=create_placeholders(64,64,3,6)
parameters=initialize_parameters()
Z3=forward_propagation(X,parameters)
cost=compute_cost(Z3,Y)
init=tf.global_variables_initializer()
sess.run(init)
a=sess.run(cost,{X:np.random.randn(4,64,64,3),Y:np.random.randn(4,6)})
print("cost = "+str(a))
1.4模型
最后,您将合并上面实现的辅助函数来构建模型。您将在SIGNS数据集上训练它。
您已random_mini_batches()在优化编程分配中实现了课程2.请记住,此函数返回一个迷你批次列表。
练习:完成下面的功能。
下面的模型应该:
- 创建占位符
- 初始化参数
- 向前传播
- 计算成本
- 创建一个优化器
最后,您将创建一个会话并为num_epochs运行for循环,获取mini-batches,然后对于每个小批量,您将优化该功能。提示初始化变量
def model(X_train,Y_train,X_test,Y_test,learning_rate=0.009,num_epochs=100,minibatch_size=64,print_cost=True):
ops.reset_default_graph()
tf.set_random_seed(1)
seed=3
(m,n_H0,n_W0,n_C0)=X_train.shape
n_y=Y_train.shape[1]
costs=[]
X,Y=create_placeholders(n_H0,n_W0,n_C0,n_y)
parameters=initialize_parameters()
Z3=forward_propagation(X,parameters)
cost=compute_cost(Z3,Y)
optimizer=tf.train.AdamOptimizer(learning_rate).minimize(cost)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(num_epochs):
minibatch_cost=0
num_minibatches=int(m/minibatch_size)
seed=seed+1
minibatches=random_mini_batches(X_train,Y_train,minibatch_size,seed)
for minibatch in minibatches:
(minibatch_X,minibatch_Y)=minibatch
_,temp_cost=sess.run([optimizer,cost],feed_dict={X:minibatch_X,Y:minibatch_Y})
minibatch_cost+=temp_cost/num_minibatches
if print_cost==True and epoch%5==0 :
print("Cost after epoch %i: %f"%(epoch,minibatch_cost))
if print_cost==True :
costs.append(minibatch_cost)
plt.clear()
plt.plot(np.squeeze(costs))
plt.ylabel("cost")
plt.xlabel("iterations (per tens)")
plt.title("Learnint rate = "+str(learning_rate))
plt.show()
predict_op=tf.argmax(Z3,1)
correct_prediction=tf.equal(predict_op,tf.argmax(Y,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,"float"))
print(accuracy)
train_accuracy=accuracy.eval({X:X_train,Y:Y_train})
test_accuracy=accuracy.eval({X:X_test,Y:Y_test})
print("Train Accuracy:",train_accuracy)
print("Test Accuracy:",test_accuracy)
return train_accuracy,test_accuracy,parameters运行以下单元格以训练您的模型100个世代。检查第0和第5世代后的成本是否与我们的输出相匹配。如果没有,请停止单元格并回到您的代码!
X_train=X_train_orig/255.0
X_test=X_test_orig/255.0
Y_train=convert_to_one_hot(Y_train_orig,6).T
Y_test=convert_to_one_hot(Y_test_orig,6).T
_, _, parameters = model(X_train, Y_train, X_test, Y_test)tips:
1.我试过上面的代码,准确度很低
2.将前向传播的代码改为
def forward_propagation(X,parameters):
W1=parameters["W1"]/np.sqrt(2)
W2=parameters["W2"]/np.sqrt(2)
会取得理想的准确度
恭喜!您已完成任务并构建了一个识别SIGN语言的模型,其测试集的准确度几乎达到80%。如果您愿意,可以随意使用此数据集。实际上,您可以通过花费更多时间调整超参数或使用正则化来提高其准确性(因为此模型显然具有较高的方差)。
再一次,这是你的工作竖起大拇指!