FLUME的产生背景
- 对于关系型数据库和HDFS,Hive,等的数据,我们可以使用sqoop将数据进行导入导出操作,但对于一些日志信息(源端)的定时收集,这种方式显然不能给予满足,这时有人会想到使用shell脚本的定时作业调度将日志收集出来,但是这种方式在处理大的数据和可靠性方面也显现出很多缺点,再比如日志信息的存储与压缩格式,任务的监控,这些显然也不能满足。
- 基于以上,FLUME这个分布式,高可靠,高可用,已经非常成熟的日志信息收集框架随之诞生,他的简单,轻便,健壮等特性使得他在数据收集方面使用的较为广泛。
哪些方面可以使用到FLUME
- FLUME自身提供了多种sources(源端类型),多种sinks(传输端类型)使得他可以处理很多类型端的数据,并传输到多种指定的输出端,基于输出端的不同,可以大致分为:1)传输到HDFS(离线批处理);2)传输到kafka等消息中间件,再由像sparkstreaming流式化处理系统进行处理
FLUME基本架构
Event概念
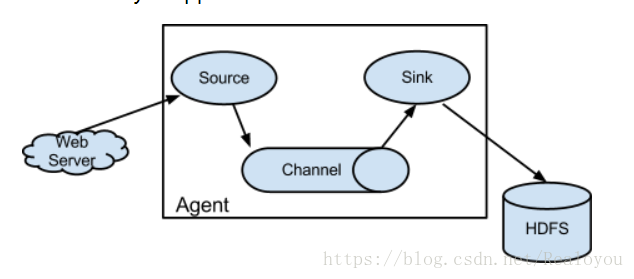
- flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
- 在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?—–event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
Agent
- 一个Agent就是一个Flume进程,agent本身是一个java进程,运行在日志收集节点—所谓日志收集节点就是服务器节点。
- 一个Agent有三大组件:Source,Channel,Sink.但是一个Agent可以由多个Source,多个Channel,多个Sink构成,一个Source可以对应多个Channel,但是一个Channel只能对应一个Sink。最简单的Agent是由一个Source,一个Channel,一个Sink构成。
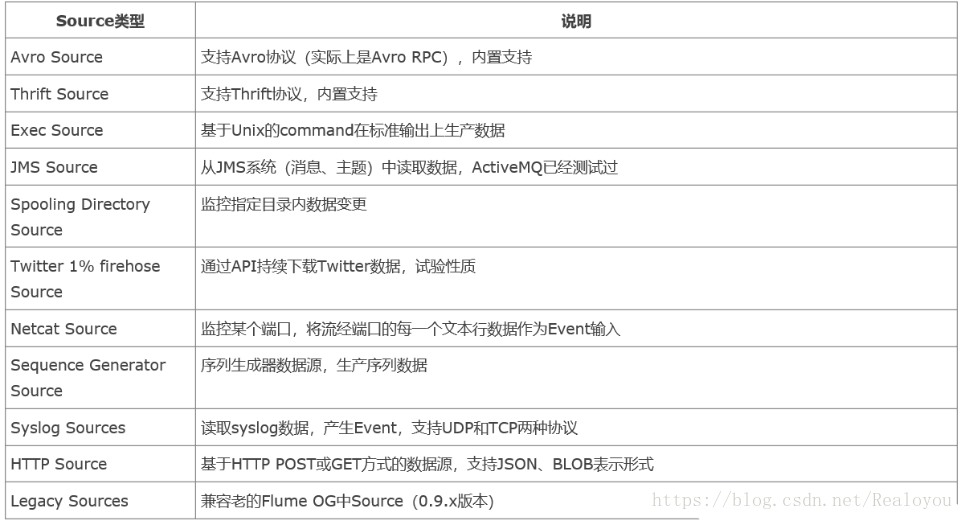
- Source :负责从源端采集数据,输出到channel中,常用的Source有exec/Spooling Directory/Taildir Source/NetCat
- Channel :负责缓存Source端来的数据,常用的Channel有Memory/File
- Sink : 处理Channel而来的数据写到目标端,常用的Sink有HDFS/Logger/Avro/Kafka
组件种类
Sources
Channels
Sinks


使用
- Flume的使用就是写一个Agent配置文件,根据场景和需求指定不同得组件类型,通过Channel将Source端和Sink端绑定串联起来,然后用flume -ng 启动flume进程
eg:
1. vi hello.conf 2. # Name the components on this agent 3. a1.sources = r1 4. a1.sinks = k1 5. a1.channels = c1 6. # Describe/configure the source 7. a1.sources.r1.type = netcat 8. a1.sources.r1.bind = 0.0.0.0 9. a1.sources.r1.port = 44444 10. # Describe the sink 11. a1.sinks.k1.type = logger 12. # Use a channel which buffers events in memory 13. a1.channels.c1.type = memory 14. # Bind the source and sink to the channel 15. a1.sources.r1.channels = c1 16. a1.sinks.k1.channel = c1启动:
1. ./flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/hello.conf -Dflume.root.logger=INFO,console
FLUME部署
- 下载:下载CDH版本 apache-flume-1.6.0-cdh5.7.0-bin
配置环境变量:
1. export FLUME_HOME=/opt/software/apache-flume-1.6.0-cdh5.7.0-bin 2. export PATH=$FLUME_HOME/bin:$PATH指定JAVA_HOME:
1. cp flume-env.sh.template flume-env.sh 2. export JAVA_HOME=/usr/java/jdk1.8.0_45
测试案例
使用Exec Source Sink 到HDFS
- Exec Source:监听一个指定的命令,获取一条命令的结果作为它的数据源
常用的是tail -F file指令,即只要应用程序向日志(文件)里面写数据,source组件就可以获取到日志(文件)中最新的内容 。 配置文件:
1. # Name the components on this agent 2. a1.sources = r1 3. a1.sinks = k1 4. a1.channels = c1 5. # Describe/configure the source 6. a1.sources.r1.type = exec 7. a1.sources.r1.command = tail -F /home/hadoop/data/data.log 8. # Describe the sink 9. a1.sinks.k1.type = hdfs 10. a1.sinks.k1.hdfs.path = hdfs://hadoop:9000/flume 11. a1.sinks.k1.hdfs.writeFormat = Text 12. a1.sinks.k1.hdfs.fileType = DataStream 13. a1.sinks.k1.hdfs.rollInterval = 10 14. a1.sinks.k1.hdfs.rollSize = 0 15. a1.sinks.k1.hdfs.rollCount = 0 16. a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H-%M-%S 17. a1.sinks.k1.hdfs.useLocalTimeStamp = true 18. # Use a channel which buffers events in memory 19. a1.channels.c1.type=memory 20. a1.channels.c1.capacity=10000 21. a1.channels.c1.transactionCapacity=1000 22. # Bind the source and sink to the channel 23. a1.sources.r1.channels = c1 24. a1.sinks.k1.channel = c1启动:
1. ./flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/test3.conf -Dflume.root.logger=INFO,console 2. echo hadoop >data.log查看结果:
1. [hadoop@hadoop001 ~]$ hdfs dfs -text /flume/2018-04-21-20-13-38.1524370418338 hadoop
使用Avro进行数据传输
- 以上的flume的使用方式都是启动的agent和sink端在一个节点之上,对于多节点的方式数据传输,flume给我们提供了Avro的Sink端和Avro的Source端,这样在多个Agent对接就提供了解决方案,在生产中的实际部署也多是使用Avro的方式。
使用Avro-client对接Avro source
A机器向B机器传输日志
A机器:avro-client
B机器:avro-source ,channel(memory) ,sink(logger)配置信息
1. B机器的agent文件: 2. a1.sources=r1 3. a1.sinks=k1 4. a1.channels=c1 5. a1.sources.r1.type=avro 6. a1.sources.r1.bind=0.0.0.0 7. a1.sources.r1.port=44444 8. a1.channels.c1.type=memory 9. a1.sinks.k1.type=logger 10. a1.sinks.k1.channel=c1 11. a1.sources.r1.channels=c1执行命令:
1. B机器上: 2. ./flume-ng agent \ 3. --name a1 \ 4. --conf $FLUME_HOME/conf \ 5. --conf-file $FLUME_HOME/conf/avro.conf \ 6. -Dflume.root.logger=INFO,console 7. 在A机器上: 8. ./flume-ng avro-client --host 0.0.0.0 --port 44444 --filename /home/hadoop/data/input.txt使用此种方式只能一次性传输文件,传输结束,进程也就自动结束了。
使用Avro Source和Avro Sink
定义A机器的agent:
1. a1.sources=r1 2. a1.sinks=k1 3. a1.channels=c1 4. a1.sources.r1.type=exec 5. a1.sources.r1.command=tail -F /home/hadoop/data/data.log 6. a1.channels.c1.type=memory 7. a1.sinks.k1.type=avro 8. a1.sinks.k1.bind=0.0.0.0 //与B机器相对应 9. a1.sinks.k1.port=44444 //与B机器相对应 10. a1.sinks.k1.channel=c1 11. a1.sources.r1.channels=c1定义B机器的agent:
1. b1.sources=r1 2. b1.sinks=k1 3. b1.channels=c1 4. b1.sources.r1.type=avro 5. a1.sources.r1.bind = 0.0.0.0 6. a1.sources.r1.port = 44444 7. b1.channels.c1.type=memory 8. b1.sinks.k1.type=logger 9. b1.sinks.k1.channel=c1 10. b1.sources.r1.channels=c1
*启动:
1. b机器先执行:
2. ./flume-ng agent \
3. --name b1 \
4. --conf $FLUME_HOME/conf \
5. --conf-file $FLUME_HOME/conf/avro_source.conf \
6. -Dflume.root.logger=INFO,console
7. 然后在A机器上执行:
8. ./flume-ng agent \
9. --name a1 \
10. --conf $FLUME_HOME/conf \
11. --conf-file $FLUME_HOME/conf/avro_sink.conf \
12. -Dflume.root.logger=INFO,console
13. [hadoop@hadoop001 data]$ echo aaa > data.log
14. [hadoop@hadoop001 data]$ echo 112121 > data.log
15. A机器目标目录下文件内容会被打印在B机器的控制台上