- 业务现状分析
- WebServer/ApplicationServer分散在各个机器上,想在大数据平台hadoop上进行统计分析,就需要先把日志收集到hadoop平台上。
- 思考:如何解决我们的数据从其他的server上移动到Hadoop之上?
- 脚本shell,用cp拷贝到hadoop集群上,再通过hadoop fs -put xxxx存储到hdfs上,但是这种方式会有如下问题:
- 如何做监控?如果拷贝过程中某台机器断掉了怎么做到很好的监控?
- 采用cp方式,需要设定一个复制的间隔时间,这样做时效性如何?
- log一般存为txt文本文件,如果把文本格式的数据直接通过网络传输,对i/o的开销很大
- 如何做负载均衡,压缩等等
- 脚本shell,用cp拷贝到hadoop集群上,再通过hadoop fs -put xxxx存储到hdfs上,但是这种方式会有如下问题:
- Flume概述
- Flume is a distributed, reliable, and available service for efficiently collecting(收集), aggregating(聚合), and moving(移动) large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
- Flume设计目标:可靠性,扩展性,管理性
- 业界同类产品的对比
-
- Flume:Cloudera/Apache java
- Scribe:Facebook c/c++ 不再维护
- Chuka:Yahoo/Apache java 不再维护
- kafka:
- Fluentd:Ruby
- Logstash:ELK
- Flume架构及核心组件
-
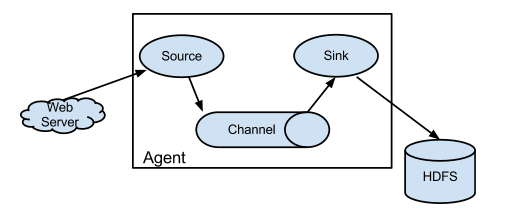
- Source :收集,常用的Source:Avro Source,Exce Source,Spooling,NetCat TCP Source,Kafka Source
- Channel : 聚集,常用的Channels:Memory Channels,File Channels,Kafka Channels
- Sink :输出,常用的Sink:HDFS Sink,Hive Sink,Logger Sink,Avro Sink,Hbase,Kafka
- 设置multi-agent flow(可参看官网)
-
- Flume环境搭建
- 安装JDK
- 安装Flume
- Flume实战案例
- 案例一的需求:从指定网络端口采集数据输出到控制台
# example.conf: A single-node Flume configuration #使用Flume的关键就是写配置文件 #配置Source #配置Channel #配置Sink #把以上三个组件串起来 #a1:agent名称;r1:source名称;k1:sink名称;c1:channels的名称 # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动agent:
bin/flume-ng agent --name a1 -c $FLUME_HOME/conf --conf-file xxx(刚刚定义的example.conf) -Dflume.root.logger=INFO,consol
- 案例二的需求:监控一个文件实时采集新增的数据输出到控制台
#agent选型:exec source + memory channel + logger sink #文件名:exec-memory-logger.conf a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command= tail -F /home/hadoop/data.log#要监控的文件 a1.sinks.k1.type = logger a1.channels.c1.type = memory # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动agent命令同上:
bin/flume-ng agent --name a1 -c $FLUME_HOME/conf --conf-file exec-memory-logger.conf
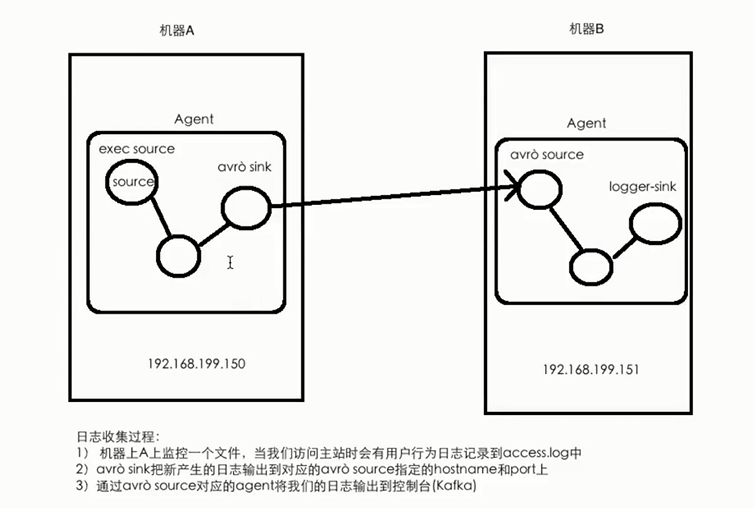
- 案例三的需求:将A服务器上的日志实时采集到B服务器上
#技术选型: #exec source + memory channel + avro sink #avro source + menory channel + logger sink #第一个conf文件内容如下:exec-memry-avro.conf exec-memory-avro.source = exec-source exec-memory-avro.sink = avro-sink exec-memory-avro.channels = memory-channel exec-memory-avro.sources.exec-source.type=exec exec-memory-avro.sources.exec-source.command=tail - F /home/hadoop/data.log exec-memory-avro.sinks.avro-sink.type=avro exec-memory-avro.sinks.avro-sink.hostname=hadoop000 exec-memory-avro.sinks.avro-sink.port=4444 exec-memory-avro.channels.memory-channel.type = memory exec-memory-avro.source.exec-memory.channels=memory-channel exex-memory-avro.sinks.avro-sinks.channel = memory-channel #第二个conf文件内容如下:avro-memory-logger.conf avro-memory-logger.source = avro-source avro-memory-logger.sink = logger-sink avro-memory-logger.channels = memory-channel avro-memory-logger.source.exec-source.type=avro avro-memory-logger.source.exec-source.bind=hadoop000 avro-memory-logger.source.exec-source.port=4444 avro-memory-logger.sinks.logger-sink.type=logger avro-memory-logger.channels.memory-channel.type = memory avro-memory-logger.source.avro-memory.channels=memory-channel avro-memory-logger.sinks.logger-sinks.channel = memory-channel
启动两个对应的conf文件:
bin/flume-ng agent --name avro-memory-logger -c $FLUME_HOME/conf --conf-file avro-memory-logger.conf
bin/flume-ng agent --name exec-memory-logger -c $FLUME_HOME/conf --conf-file exec-memory-logger.conf
- 案例一的需求:从指定网络端口采集数据输出到控制台
学习笔记:分布式日志收集框架Flume
猜你喜欢
转载自www.cnblogs.com/hsy060314/p/10558473.html
今日推荐
周排行