业务现状:公司有Hadoop集群;同时拥有大量日志数据;你想要把大量日志数据放入Hadoop中进行分析。
- WebServer/ApplicationServer分散在各个机器上
- 想大数据平台Hadoop进行统计分析
- 日志如何收集到Hadoop平台上
- 解决方案及存在的问题
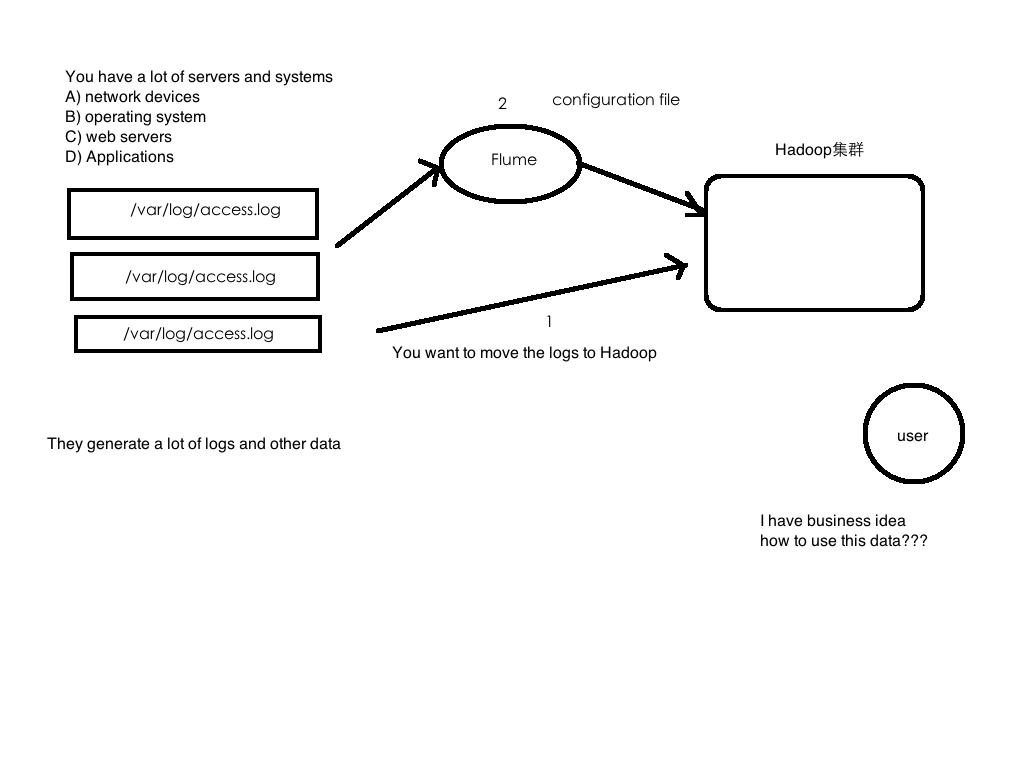
如何解决我们的数据从其他的server上移动到Hadoop之上???
shell cp hadoop集群的机器上, hadoop fs -put … /
缺点:
1、无法做监控
2、必须间隔时间;时效性不好;不是实时的
3、网络传输对于io开销大
4、如何做负载均衡等等
Flume概述
官方文档:学习建议多多参考官方文档
http://flume.apache.org/FlumeUserGuide.html
- Flume官网: http://flume.apache.org/
- Flume是由Cloudera提供的一个分布式、高可靠、高可用的服务用于分布式的海量日志的高效收集、聚合、移动系统
- Flume设计目标
- 可靠性
- 扩展性
- 管理性
- 业界同类产品对比
- (***)Flume: Cloudera/Apache Java
- Scribe: Facebook C/C++ 不再维护
- Chukwa: Yahoo/Apache Java 不再维护
- Kafka:(有人可能会说这个框架)这是个消息队列;和flume不是一类
- Fluentd: Ruby
- (***)Logstash: ELK(ElasticSearch,Kibana)
- Flume发展史
- Cloudera 0.9.2 Flume-OG
- flume-728 Flume-NG ==> Apache
- 2012.7 1.0
- 2015.5 1.6 (*** + )
- 2016.10 1.7
- 2017.10 1.8
Flume是一种分布式、可靠和可用的服务,用于有效地收集、聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有健壮性和容错性,具有可调的可靠性机制和许多故障转移和恢复机制。它使用一个简单的可扩展数据模型,支持在线分析应用程序。
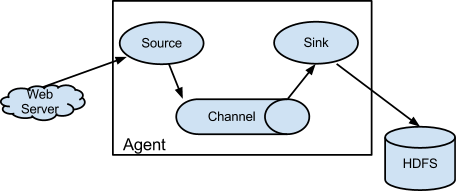
Flume架构及核心组件
- 1 Source 收集
http://flume.apache.org/FlumeUserGuide.html#flume-sources
主要是采集各种数据;将收集的数据放入channel中 - 2 Channel 聚集
主要是数据缓存;相当于一个小型消息队列 - 3 Sink 输出
主要是从channel拿去数据放入目的地中
架构一:
为了在多个Agent或跃点source之间传输数据,前一个代理的sink和当前source需要是avro类型,接收器指向源的主机名(或IP地址)和端口。

架构二:
日志收集中一个非常常见的场景是,大量日志生成客户机将数据发送到附加到存储子系统的几个使用者代理。例如,从数百台web服务器收集的日志被发送到12个写入HDFS集群的代理。
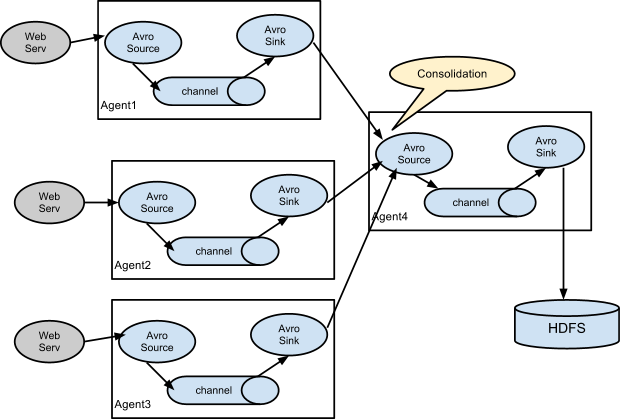
这可以在Flume中通过配置许多具有avro接收器的第一层代理来实现,所有这些代理都指向单个代理的avro源(同样,您可以在这种场景中使用thrift sources/sink /client)。第二层代理上的源将接收到的事件合并到单个通道中,接收通道由接收方使用到其最终目的地。
架构三:
Flume支持将事件流多路复用到一个或多个目的地。这是通过定义一个流多路复用器来实现的,该复用器可以复制或选择性地将事件路由到一个或多个通道。
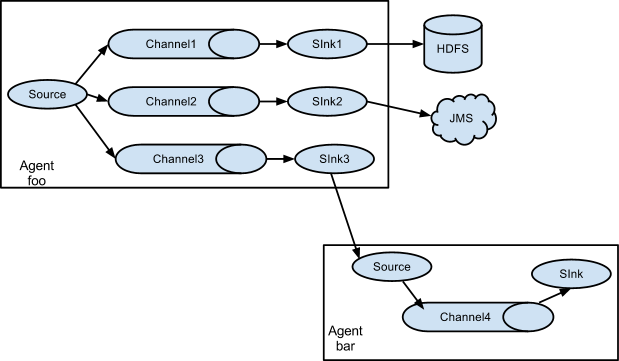
上面的示例显示了来自代理“foo”的源,它将流分散到三个不同的通道。这个散开的方式可以复制或多路复用。在复制流的情况下,每个事件被发送到所有三个通道。对于多路复用情况,当事件的属性与预先配置的值匹配时,将事件交付给可用通道的子集。例如,如果一个名为“txnType”的事件属性被设置为“customer”,那么它应该转到channel1和channel3,如果它是“vendor”,那么它应该转到channel2,否则就是channel3。这些都是可以配置的。
Flume&JDK环境部署
1、Flume(1.6.0)安装前置条件
- Java运行时环境——Java 1.7或更高版本
- 内存——足够的内存用于源、通道或接收器使用的配置
- 磁盘空间——足够的磁盘空间用于通道或接收器使用的配置
- 目录权限——代理使用的目录的读/写权限
2、安装jdk
下载
解压到~/app
将java配置系统环境变量中: ~/.bash_profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
export PATH=$JAVA_HOME/bin:$PATH
source下让其配置生效
检测: java -version
3、安装Flume
下载
解压到~/app
将java配置系统环境变量中: ~/.bash_profile
export FLUME_HOME=/home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH
source下让其配置生效
flume-env.sh的配置:export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
检测: flume-ng version
Flume实战案例一
需求:从指定网络端口采集数据输出到控制台
example.conf: A single-node Flume configuration
example.conf: 单节点Flume配置文件
使用Flume的关键就是写配置文件
A) 配置Source
B) 配置Channel
C) 配置Sink
D) 把以上三个组件串起来
a1: agent名称
r1: source的名称
k1: sink的名称
c1: channel的名称
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop000
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意:
一个source可以输出多个channel
一个sink只能从一个channel拿去数据
启动agent
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example.conf \
-Dflume.root.logger=INFO,console
使用telnet进行测试: telnet hadoop000 44444
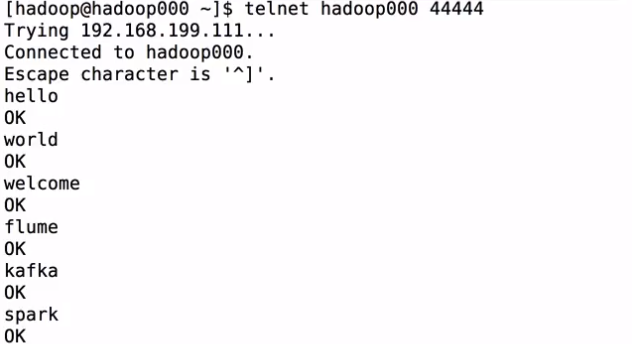
转到启动flume的页面看到:
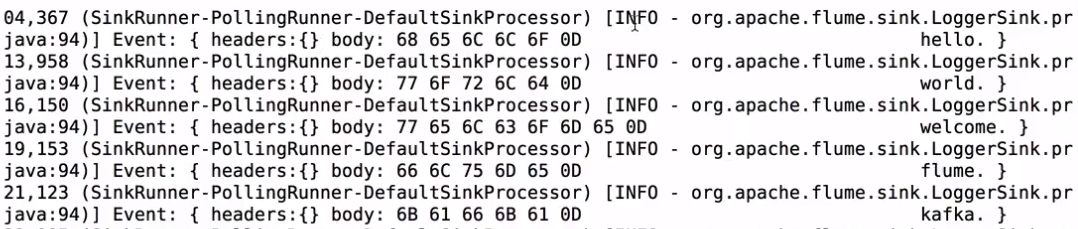
Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
Event是FLume数据传输的基本单元
Event = 可选的header + byte array
Flume实战案例二
需求:监控一个文件实时采集新增的数据输出到控制台
Agent选型:exec source + memory channel + logger sink
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/data.log
a1.sources.r1.shell = /bin/sh -c
#用于运行该命令的shell调用。例如/bin/sh -c;仅对依赖于shell特性(如通配符、反勾号、管道等)的命令需要。
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动agent
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-logger.conf \
-Dflume.root.logger=INFO,console
向文件中输入字符串:

启动flume的界面:

Flume实战案例三(重点掌握)
需求:将A服务器上的日志实时采集到B服务器
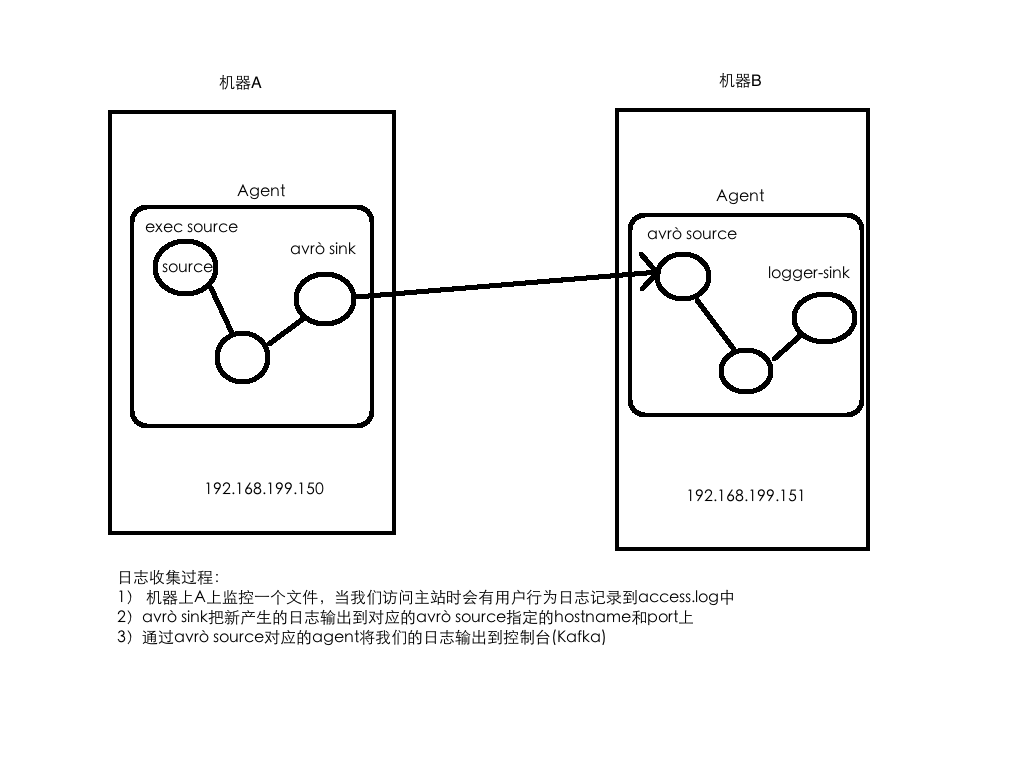
技术选型:
exec source + memory channel + avro sink
avro source + memory channel + logger sink
exec-memory-avro.conf
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -F /home/hadoop/data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop000
exec-memory-avro.sinks.avro-sink.port = 44444
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
avro-memory-logger.conf
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = hadoop000
avro-memory-logger.sources.avro-source.port = 44444
avro-memory-logger.sinks.logger-sink.type = logger
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
先启动avro-memory-logger
flume-ng agent \
--name avro-memory-logger \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/avro-memory-logger.conf \
-Dflume.root.logger=INFO,console
再启动exec-memory-avro
flume-ng agent \
--name exec-memory-avro \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-avro.conf \
-Dflume.root.logger=INFO,conso
测试和Flume实战案例二一样