一、日志生成环境模拟
Tomcat安装:
新建一台虚拟机作为webserver,安装jdk和Tomcat,把安装包传入至虚拟机中
[root@slave02 spark]# tar -zxf apache-tomcat-8.5.63.tar.gz -C /opt/software/spark/
[root@slave02 spark]# mv apache-tomcat-8.5.63/ tomcat8563
[root@slave02 spark]# cd tomcat8563/
[root@slave02 conf]# vi server.xml
- 因为8080容易被占用,因此把<connector port="8080" ...>端口改成8888
[root@slave02 conf]# cd ../bin/
[root@slave02 bin]# ./startup.sh
Tomcat started.
- Tomcat启动后,进入浏览器输入ip:8888即可进入Tomcat webUI
[root@slave02 bin]# jps
2325 Bootstrap
2471 Jps
[root@slave02 bin]# ./shutdown.sh
[root@slave02 logs]# cd ../webapps/
[root@slave02 webapps]# mkdir mycurd
[root@slave02 webapps]# cd mycurd/
- 把模拟日志文件拖入到当前目录中,模拟Tomcat产出的日志文件,注意检查文件的字符集是否和虚拟机同步,否则虚拟机无法识别
二、flume任务配置
1、任务脚本文件配置
######任务配置文件
#组件名称缩写
a1.channels = c1
a1.sources = s1
a1.sinks = k1
# 一个channel只能有一个sink
# 组件类型名
a1.sources.s1.type = spooldir
#指定 Channels,多个 Channel 以空格分隔
a1.sources.s1.channels = c1
#指定要从中读取文件的目录
a1.sources.s1.spoolDir = /opt/software/spark/tomcat8563/webapps/mycurd/logmake_py
# channel组件类型为file
a1.channels.c1.type = file
#检查点,防止丢失,设置目录
a1.channels.c1.checkpointDir = /opt/flume/checkpoint
# 逗号分隔的目录列表,用于存储日志文件。在不同的磁盘上使用多个目录可以提高文件通道的性能
a1.channels.c1.dataDirs = /opt/flume/data
#指定sink组件类型为hdfs
a1.sinks.k1.type = hdfs
#sink的hdfs输出路径
a1.sinks.k1.hdfs.path = hdfs://192.168.221.221:9000/upload/%Y%m%d
#Flume 在 HDFS 文件夹下创建新文件的固定前缀
a1.sinks.k1.hdfs.filePrefix = upload-
#替换转义序列时是否使用本地时间戳(否则使用Event header 中的 timestamp )
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#每个事务写入的 Event 数量
a1.sinks.k1.hdfs.batchSize = 100
#1.DataStream 不会压缩文件,不需要设置hdfs.codeC
a1.sinks.k1.hdfs.fileType = DataStream
#当前文件写入达到该值时间后触发滚动创建新文件(0 表示不按照时间来分割文件),单位:秒
a1.sinks.k1.hdfs.rollInterval = 600
#当前文件写入达到该大小后触发滚动创建新文件(0 表示不根据文件大小来分割文件),单位:字节
a1.sinks.k1.hdfs.rollSize = 134217700
#当前文件写入Event 达到该数量后触发滚动创建新文件(0 表示不根据 Event 数量来分割文件)
a1.sinks.k1.hdfs.rollCount = 0
#指定每个 HDFS 块的最小副本数。 如果未指定, 则使用 classpath 中 Hadoop 的默认配置
a1.sinks.k1.hdfs.minBlockReplicas = 1
#指定sink的 channel
a1.sinks.k1.channel = c1
2、执行flume任务
#######执行flume任务
flume-ng agent -n a1 --conf /opt/software/spark/flume160/conf/ -f /opt/flumeconf/filetohdfs.conf -Dflume.root.logger=DEBUG,console
执行后会报如下错误,原因是缺少jar包,在hadoop中拷贝以下jar包至flume/lib目录下即可
错误1:
java.lang.NoClassDefFoundError: org/apache/hadoop/io/SequenceFile$CompressionType
缺少jar包:/opt/software/hadoop/hadoop260/share/hadoop/common/hadoop-common-2.7.2.jar
错误2:
java.lang.NoClassDefFoundError: org/apache/commons/configuration/Configuration
缺少jar包:/opt/software/hadoop/hadoop260/share/hadoop/common/lib/commons-configuration-1.6.jar
错误3:
java.lang.NoClassDefFoundError: org/apache/hadoop/util/PlatformName
缺少jar包/opt/software/hadoop/hadoop260/share/hadoop/common/lib/hadoop-auth-2.6.0-cdh5.14.2.jar
错误4:
java.lang.NoClassDefFoundError: org/apache/htrace/core/Tracer$Builder
缺少jar包/opt/software/hadoop/hadoop260/share/hadoop/hdfs/lib/htrace-core4-4.0.1-incubating.jar
错误5:
java.io.IOException: No FileSystem for scheme: hdfs
缺少jar包/opt/software/hadoop/hadoop260/share/hadoop/hdfs/hadoop-hdfs-2.6.0-cdh5.14.2.jar
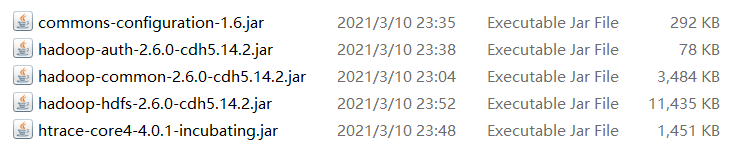
错误6:

内存溢出,进入flume/bin目录下,扩大文件flume-ng的内存配置,原为20M,此处修改为1G