1、什么是RDD
RDD是Spark的基本数据结构,是不可变数据集。RDD中的数据集进行逻辑分区,每个分区可以单独在集群节点进行计算。可以包含任何java,scala,python和自定义类型。
RDD是只读的记录分区集合。RDD具有容错机制。
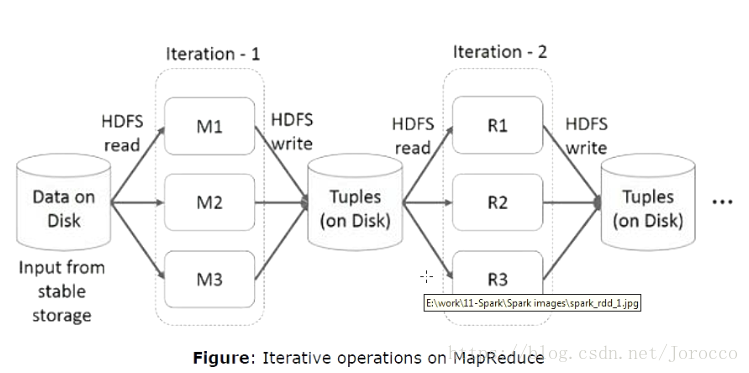
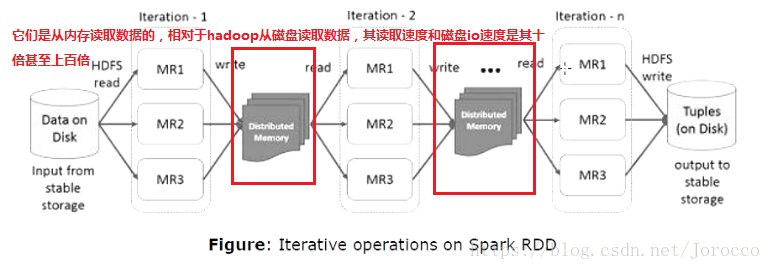
Spark主要是内存处理计算,在job间进行数据共享,内存的IO速率高于网络和磁盘的10~100之间,而hadoop花费90%的时间用于读写数据,因为它的中间数据是存储在磁盘上的,IO速率较慢,需要耗费大量的时间。
内部包含5个主要属性
1.分区列表
2.针对每个split的计算函数。
3.对其他rdd的依赖列表
4.可选,如果是KeyValueRDD的话,可以带分区类。
5.可选,首选块位置列表(hdfs block location);
//默认并发度
local.backend.defaultParallelism() = scheduler.conf.getInt("spark.default.parallelism", totalCores)
taskScheduler.defaultParallelism = backend.defaultParallelism()
sc.defaultParallelism =...; taskScheduler.defaultParallelism
defaultMinPartitions = math.min(defaultParallelism, 2)
sc.textFile(path,defaultMinPartitions) //1,22、RDD变换
返回指向新rdd的指针,在rdd之间创建依赖关系。每个rdd都有计算函数和指向父RDD的指针。
map() //对每个元素进行变换,应用变换函数
//(T)=>V
filter() //过滤器,(T)=>Boolean
flatMap() //压扁,T => TraversableOnce[U]
mapPartitions() //对每个分区进行应用变换,输入的Iterator,返回新的迭代器,可以对分区进行函数处理。
//Iterator<T> => Iterator<U>
mapPartitionsWithIndex(func) //同上,(Int, Iterator<T>) => Iterator<U>
sample(withReplacement, fraction, seed) //采样返回采样的RDD子集。
//withReplacement 元素是否可以多次采样.
//fraction : 期望采样数量.[0,1]
union() //类似于mysql union操作。
//select * from persons where id < 10
//union select * from id persons where id > 29 ;
intersection //交集,提取两个rdd中都含有的元素。
distinct([numTasks])) //去重,去除重复的元素。
groupByKey() //(K,V) => (K,Iterable<V>)
reduceByKey(*) //按key聚合。
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])
//按照key进行聚合
key:String U:Int = 0
sortByKey //排序
join(otherDataset, [numTasks]) //连接,(K,V).join(K,W) =>(K,(V,W))
cogroup //协分组
//(K,V).cogroup(K,W) =>(K,(Iterable<V>,Iterable<!-- <W> -->))
cartesian(otherDataset) //笛卡尔积,RR[T] RDD[U] => RDD[(T,U)]
pipe //将rdd的元素传递给脚本或者命令,执行结果返回形成新的RDD
coalesce(numPartitions) //减少分区
repartition //可增可减
repartitionAndSortWithinPartitions(partitioner)
//再分区并在分区内进行排序2.1 Map
import org.apache.spark.{SparkConf, SparkContext}
/**
*
*/
object MapDemo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("WordCountScala")
conf.setMaster("local[4]") ;
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("d:/scala/test.txt",4)
val rdd2 = rdd1.flatMap(_.split(" ")) ;
//val rdd3 = rdd2.map(word=>{println("start") ;val t = (word,1) ;println(t + " : end") ; t})
// val rdd3 = rdd2.mapPartitions(it=>{
// import scala.collection.mutable.ArrayBuffer ;
// val buf = ArrayBuffer[String]()
// val tname = Thread.currentThread().getName
// println(tname + " : mapPartitions start ");
// for (e <- it) {
// buf.+=("_" + e);
// }
// buf.iterator
// });
val rdd3 = rdd2.mapPartitionsWithIndex((index,it) => {
import scala.collection.mutable.ArrayBuffer;
val buf = ArrayBuffer[String]()
val tname = Thread.currentThread().getName
println(tname + " : " + index + " : mapPartitions start ");
for (e <- it) {
buf.+=("_" + e);
}
buf.iterator
});
val rdd5 = rdd3.map(word=>{
val tname = Thread.currentThread().getName
println(tname + " : map " + word);
(word,1)});
val rdd4 = rdd5.reduceByKey(_ + _)
val r = rdd4.collect()
r.foreach(println)
}
}2.2 Sample
import org.apache.spark.{SparkConf, SparkContext}
/**
*
*/
object SampleDemo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("WordCountScala")
conf.setMaster("local[4]") ;
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("d:/scala/test.txt",4)
val rdd2 = rdd1.flatMap(_.split(" "))
val rdd3 = rdd2.sample(false,0.5)
rdd3.collect().foreach(println)
}
}2.3 Union
import org.apache.spark.{SparkConf, SparkContext}
/**
*
*/
object UnionDemo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("WordCountScala")
conf.setMaster("local[4]") ;
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("d:/scala/log.txt",4)
//所有error
val errorRDD = rdd1.filter(_.toLowerCase.contains("error"))
//所有warn行
val warnRDD = rdd1.filter(_.toLowerCase.contains("warn"));
val allRDD = errorRDD.union(warnRDD);
allRDD.collect().foreach(println)
}
}2.4 Intersection
import org.apache.spark.{SparkConf, SparkContext}
/**
*
*/
object IntersectionDemo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("WordCountScala")
conf.setMaster("local[4]") ;
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("d:/scala/log.txt",4)
//所有error
val errorRDD = rdd1.filter(_.toLowerCase.contains("error"))
//所有warn行
val warnRDD = rdd1.filter(_.toLowerCase.contains("warn"));
val intersecRDD = errorRDD.intersection(warnRDD);
intersecRDD.collect().foreach(println)
}
}2.5 Distinct
import org.apache.spark.{SparkConf, SparkContext}
/**
*
*/
object DistinctDemo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("WordCountScala")
conf.setMaster("local[4]") ;
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("d:/scala/log.txt",4)
val rdd2 = rdd1.flatMap(_.split(" "))
val rdd3 = rdd2.distinct()
rdd3.collect().foreach(println)
}
}
2.6 GroupByKey
import org.apache.spark.{SparkConf, SparkContext}
/**
*
*/
object GroupByKeyDemo1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("WordCountScala")
conf.setMaster("local[4]") ;////开启4个线程
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("d:/scala/stus.txt",4)//设置4个分区
val rdd2 = rdd1.map(line=>{
val key = line.split(" ")(3)
(key,line)
})
val rdd3 = rdd2.groupByKey()
rdd3.collect().foreach(t=>{
val key = t._1;
println(key + " : ====================")
for (e <- t._2){
println(e)
}
})
}
}2.7 Join
package cn.ctgu.WordCountDemo
import org.apache.spark.{SparkConf, SparkContext}
//连接查询
/*
结果:
4 : (tomson,600)
2 : (tomas,580)
1 : (tom,600)
3 : (tommasLee,450)*/
object JoinDemo1{
def main(args: Array[String]): Unit = {
val conf=new SparkConf();
conf.setAppName("WordCountScala");
conf.setMaster("local[4]");//开启4个线程
val sc=new SparkContext(conf);
//名单
val nameRdd1=sc.textFile("F:\\comp\\name.txt");
val nameRdd2=nameRdd1.map(line=>{
var arr=line.split(" ")
(arr(0).toInt,arr(1))
})
//总成绩
val scoreRdd1=sc.textFile("F:\\comp\\score.txt")
val scoreRdd2=scoreRdd1.map(line=>{
var arr=line.split(" ")
(arr(0).toInt,arr(1).toInt)
})
val rdd=nameRdd2.join(scoreRdd2)
rdd.collect().foreach(t=>{
println(t._1+" : "+t._2)
})
}
}2.8 cogroup
package cn.ctgu.WordCountDemo
import org.apache.spark.{SparkConf, SparkContext}
//协分组
/*
结果:
henan :==============
tom
tomas
tomasLee
100
1000
10000
100000
hebei :==============
jerry
jexxica
kaola
9000
900*/
object cogroupDemo1{
def main(args: Array[String]): Unit = {
val conf=new SparkConf();
conf.setAppName("WordCountScala");
conf.setMaster("local[4]");//开启4个线程
val sc=new SparkContext(conf);
//K,v
val rdd1=sc.textFile("F:\\comp\\cogroup-1.txt");
val rdd2=rdd1.map(line=>{
var arr=line.split(" ")
(arr(0),arr(1))
})
//K,W
val rdd3=sc.textFile("F:\\comp\\cogroup-2.txt")
val rdd4=rdd3.map(line=>{
var arr=line.split(" ")
(arr(0),arr(1))
})
val rdd=rdd2.cogroup(rdd4)
rdd.collect().foreach(t=>{
println(t._1+" :==============")
for (e<-t._2._1){
println(e)
}
for(e<-t._2._2){
println(e)
}
})
}
}2.9 cartesian
package cn.ctgu.WordCountDemo
import org.apache.spark.{SparkConf, SparkContext}
//笛卡尔积
/*
结果:
(tom,1234)
(tom,3456)
(tom,5678)
(tom,7890)
(tomas,1234)
(tomas,3456)
(tomas,5678)
(tomas,7890)
(tomasle,1234)
(tomasle,3456)
(tomasle,5678)
(tomasle,7890)
(tomson,1234)
(tomson,3456)
(tomson,5678)
(tomson,7890)*/
object cartesianDemo1{
def main(args: Array[String]): Unit = {
val conf=new SparkConf();
conf.setAppName("WordCountScala");
conf.setMaster("local[4]");//开启4个线程
val sc=new SparkContext(conf);
val rdd1=sc.parallelize(Array("tom","tomas","tomasle","tomson"));
val rdd2=sc.parallelize(Array("1234","3456","5678","7890"));
val rdd=rdd1.cartesian(rdd2);
rdd.collect().foreach(t=>println(t))
}
}2.10 Pipe
package cn.ctgu.WordCountDemo
import org.apache.spark.{SparkConf, SparkContext}
//管道
object PipeDemo1{
def main(args: Array[String]): Unit = {
val conf=new SparkConf();
conf.setAppName("WordCountScala");
conf.setMaster("local[4]");//开启4个线程
val sc=new SparkContext(conf);
val rdd=sc.parallelize(Array("d:\\","e:\\","f:\\"));
val rdd0=rdd.pipe("dir d:\\")
rdd0.collect().foreach(println)
}
}2.11 coalesce
package cn.ctgu.WordCountDemo
import org.apache.spark.{SparkConf, SparkContext}
//压缩分区
/*
结果:
rdd1' parti: 5
rdd2' parti: 3
rdd3' parti: 3*/
object CoalesceDemo1{
def main(args: Array[String]): Unit = {
val conf=new SparkConf();
conf.setAppName("WordCountScala");
conf.setMaster("local[8]");//开启8个线程
val sc=new SparkContext(conf);
val rdd1=sc.textFile("F:\\comp\\name.txt",4);
println("rdd1' parti: "+rdd1.partitions.length)
val rdd11=rdd1.coalesce(3);//压缩分区为3个,及后面的都为3个分区
// 再分区
val rdd111=rdd11.repartition(5);//再分区为5个
val rdd2=rdd111.flatMap(_.split(" "))
println("rdd2' parti: "+rdd2.partitions.length)
//
val rdd3=rdd2.map((_,1))
println("rdd3' parti: "+rdd3.partitions.length)
}
}3、RDD Action
collect() //收集rdd元素形成数组.
count() //统计rdd元素的个数
reduce() //聚合,返回一个值。
first //取出第一个元素take(1)
take //取出所有元素
takeSample (withReplacement,num, [seed])
takeOrdered(n, [ordering]) //取出前n个元素,并采用某种排序方法进行排序
saveAsTextFile(path) //保存到文件
saveAsSequenceFile(path) //保存成序列文件
saveAsObjectFile(path) (Java and Scala)
countByKey() //按照key,统计每个key下value的个数.解决数据倾斜问题
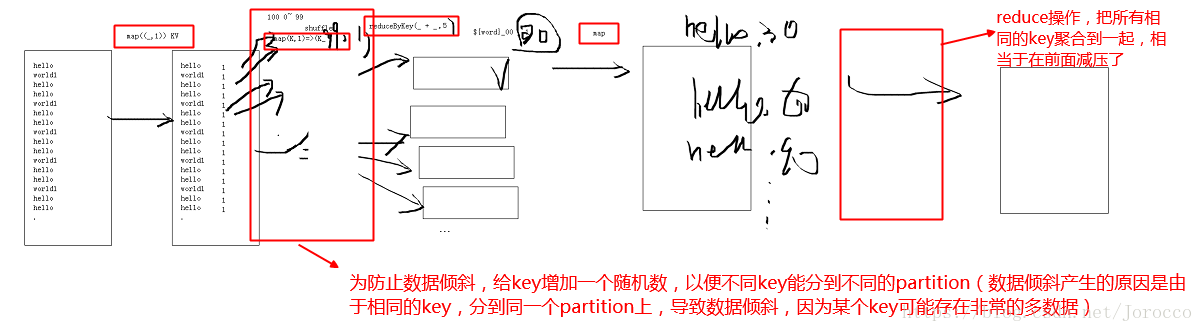
package cn.ctgu.WordCountDemo
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.Random
//解决数据倾斜
/*
结果:
rdd1' parti: 5
rdd2' parti: 3
rdd3' parti: 3*/
object DateLeanDemo1{
def main(args: Array[String]): Unit = {
val conf=new SparkConf();
conf.setAppName("WordCountScala");
conf.setMaster("local[8]");//开启8个线程
val sc=new SparkContext(conf);
val rdd1=sc.textFile("F:\\comp\\name.txt",4);
rdd1.flatMap(_.split(" ")).map((_,1)).map(t=>{
val word=t._1
var r=Random.nextInt(100)
(word+"_"+r,1)
}).reduceByKey(_+_,4).map(t=>{//reduceByKey(_+_,4),4个分区
val word=t._1;
val count=t._2;
val w=word.split("_")(0)
(w,count)
}).reduceByKey(_+_,4).saveAsTextFile("F:\\comp\\out");
}
}