这次我们介绍RDD的原理和spark运行机制
- RDD依赖关系
- RDD缓存
- RDD容错机制
- spark运行架构
- spark任务调度
1. RDD原理
首先我们对之前的单词统计的代码做一个画图展示
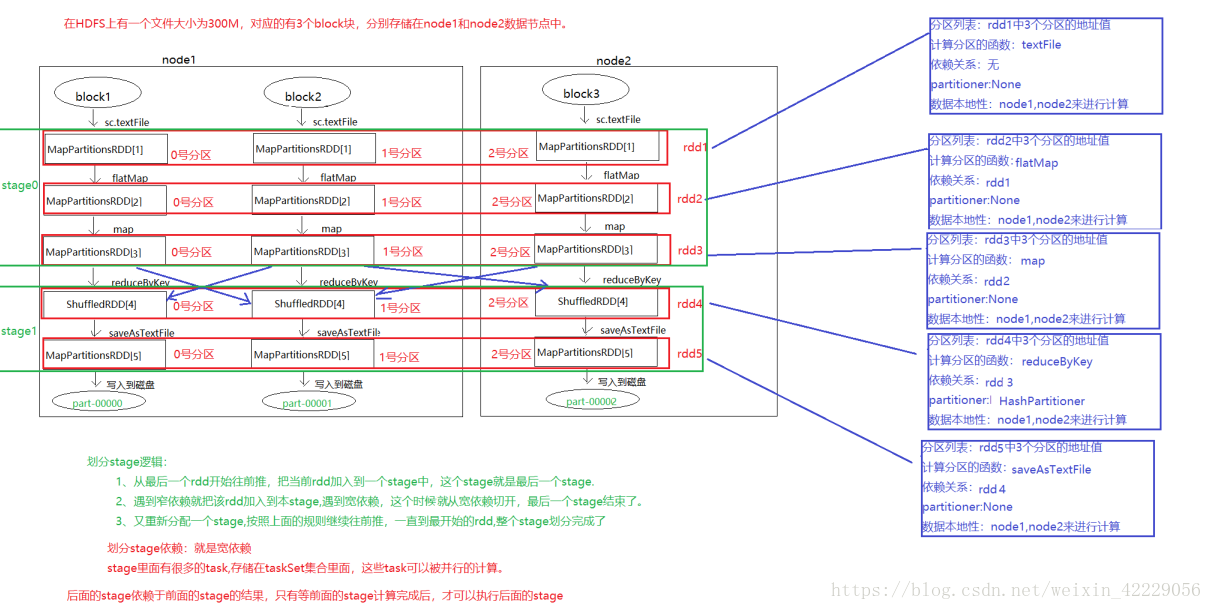
1.1 RDD依赖关系
RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
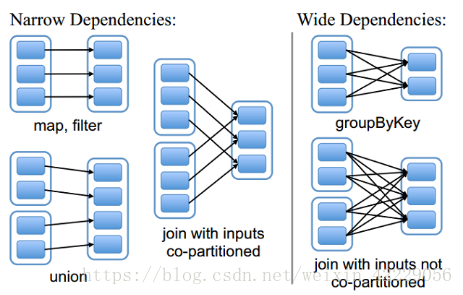
- 窄依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用
总结:窄依赖我们形象的比喻为独生子女 - 宽依赖
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition
总结:宽依赖我们形象的比喻为超生 - Lineage(血统)
RDD只支持粗粒度转换,即只记录单个块上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
1.2 RDD缓存
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或者缓存数据集。当持久化某个RDD后,每一个节点都将把计算分区结果保存在内存中,对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。
- 缓存方式
RDD通过persist方法或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。 - cache方法
通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def cache(): this.type = persist()
- Persist方法
在persist方法中,可以设置多个缓存级别,查看源码会看到不同的缓存机制
用法 file.persist(StorageLevel.MEMORY_ONLY_2)
/**
* Various [[org.apache.spark.storage.StorageLevel]] defined and utility functions for creating
* new storage levels.
*/
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
- 缓存丢失的处理机制
从上一个缓存的位置读取文件,重新执行lineage中的任务信息,重新计算,而不是重新加载文件,如果所有的。
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
1.3RDD的容错机制之checkpoint
- checkpoint是什么?
(1)Spark 在生产环境下经常会面临transformation的RDD非常多(例如一个Job中包含1万个RDD)或者具体transformation的RDD本身计算特别复杂或者耗时(例如计算时长超过1个小时),这个时候就要考虑对计算结果数据持久化保存;
(2)Spark是擅长多步骤迭代的,同时擅长基于Job的复用,这个时候如果能够对曾经计算的过程产生的数据进行复用,就可以极大的提升效率;
(3)如果采用persist把数据放在内存中,虽然是快速的,但是也是最不可靠的;如果把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏,系统管理员可能清空磁盘。
(4)Checkpoint的产生就是为了相对而言更加可靠的持久化数据,在Checkpoint的时候可以指定把数据放在本地,并且是多副本的方式,但是在生产环境下是放在HDFS上,这就天然的借助了HDFS高容错、高可靠的特征来完成了最大化的可靠的持久化数据的方式;
假如进行一个1万个算子操作,在9000个算子的时候persist,数据还是有可能丢失的,但是如果checkpoint,数据丢失的概率几乎为0。 - checkpoint原理机制
当RDD使用cache机制从内存中读取数据,如果数据没有读到,会使用checkpoint机制读取数据。此时如果没有checkpoint机制,那么就需要找到父RDD重新计算数据了,因此checkpoint是个很重要的容错机制。
checkpoint就是对于一个RDD chain(链)多次反复使用的数据,就可以针对该RDD启动checkpoint机制,使用checkpoint
- 首先需要调用sparkContext的setCheckpoint方法,设置一个容错文件系统目录,比如hdfs,
- 然后对RDD调用checkpoint方法。之后在RDD所处的job运行结束后,会启动一个单独的job来将checkpoint过的数据写入之前设置的文件系统持久化,进行高可用。
- 后面的计算在使用该RDD时,如果数据丢失了,但是还是可以从它的checkpoint中读取数据,不需要重新计算。
RDD缓存和checkpoint的区别
- persist或者cache与checkpoint的区别在于,前者持久化只是将数据保存在BlockManager中但是其lineage是不变的
- 但是后者checkpoint执行完后,rdd已经没有依赖RDD,只有一个checkpointRDD,checkpoint之后,RDD的lineage就改变了。
- persist或者cache持久化的数据丢失的可能性更大,因为可能磁盘或内存被清理,但是checkpoint的数据通常保存到hdfs上,放在了高容错文件系统。
2. spark运行机制
2.1 spark运行基本流程
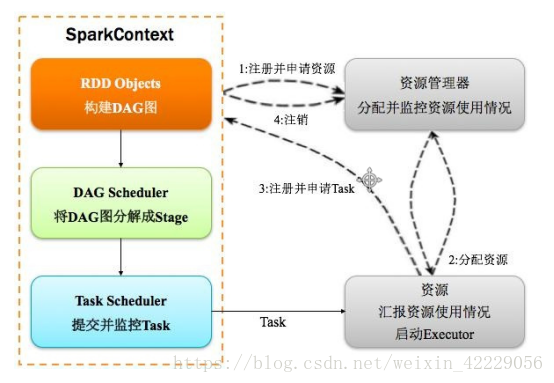
-
构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
-
资源管理器分配Executor资源并启动Executor,Executor运行情况将随着心跳发送到资源管理器上;
3)SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
4)Task在Executor上运行,运行完毕释放所有资源。
2.2 Spark运行架构特点
- 每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。
- Spark任务与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
- 提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark程序运行过程中SparkContext和Executor之间有大量的信息交换;如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。
- Task采用了数据本地性和推测执行的优化机制。
2.3什么是ADG
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间依赖关系的不同将DAG划分成不同的Stage(调度阶段)。对于窄依赖,partition的转换处理在一个Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
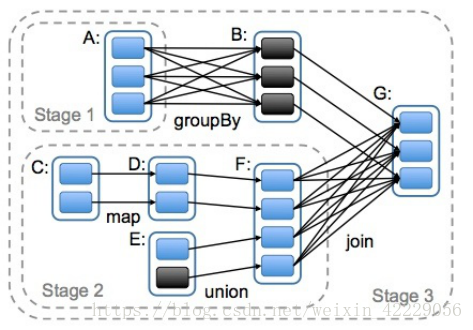
2.4 spark任务调度流程图
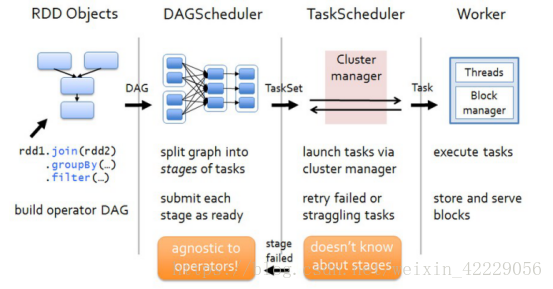

各个RDD之间存在着依赖关系,这些依赖关系就形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分。DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,最后在Worker节点上启动task。
-
DAGScheduler
(1)DAGScheduler对DAG有向无环图进行Stage划分。
(2)记录哪个RDD或者 Stage 输出被物化(缓存),通常在一个复杂的shuffle之后,通常物化一下(cache、persist),方便之后的计算。
(3)重新提交shuffle输出丢失的stage(stage内部计算出错)给TaskScheduler
将 Taskset 传给底层调度器
(4)将 Taskset 传给底层调度器- a)– spark-cluster TaskScheduler
- b)– yarn-cluster YarnClusterScheduler
- c)– yarn-client YarnClientClusterScheduler
-
TaskScheduler
(1)为每一个TaskSet构建一个TaskSetManager 实例管理这个TaskSet 的生命周期
(2)数据本地性决定每个Task最佳位置
(3)提交 taskset( 一组task) 到集群运行并监控
(4)推测执行,碰到计算缓慢任务需要放到别的节点上重试
(5)重新提交Shuffle输出丢失的Stage给DAGScheduler
本次介绍结束