2.Spark运行模式?
1).Local:在eclipse/IDEA中编写代码,在本地运行
2).Standalone:Spark自带的资源调度框架,支持分布式搭建。
3).Yarn:Hadoop生态圈内的资源调度框架。
4).Mesos:资源调度框架。
3.Spark核心RDD
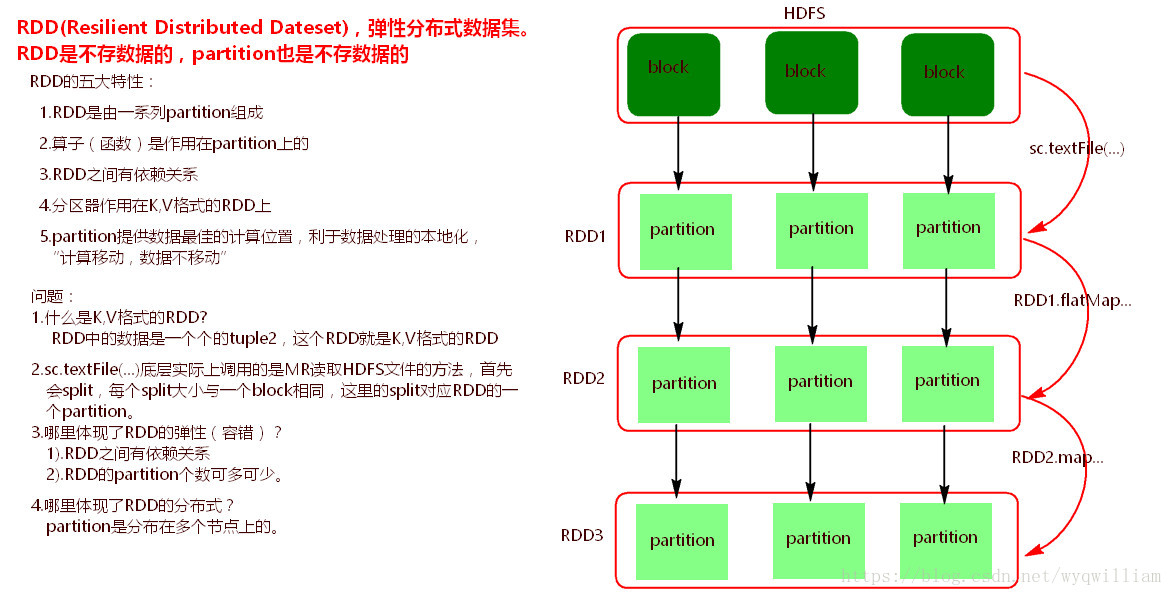
1).RDD(Resilient Distributed Dateset),弹性分布式数据集。Spark底层操作数据都是基于RDD。
2).RDD五大特性:
a).RDD由一系列Partition组成。
b).函数(算子)是作用在partition上的。
c).RDD之间有依赖关系。
d).分区器是作用在K,V格式的RDD上。
e).partition提供最佳计算位置,利于处理数据的本地化。符合“计算移动,数据不移动”
3).注意:
a).sc.textFile(...)读取HDFS中文件的方法,底层调用的是MR读取HDFS中文件的方法,首先会split,每个split大小默认
与一个block大小相同,每个split与RDD中的一个partition对应。
b).什么是K,V格式的RDD?
RDD中元素是一个个的tuple2 二元组,这个RDD就是K,V格式的RDD。
c).哪里体现了RDD的弹性(容错)?
i).RDD之间有依赖关系
ii).partition个数可多可少。
d).哪里体现了RDD的分布式?
partition是分布在多个节点上的。
RDD:RDD(Resilient Distributed Datasets) ,弹性分布式数据集, 是分布式内存的一个抽象概念,RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建,然而这些限制使得实现容错的开销很低。对开发者而言,RDD可以看作是Spark的一个对象,它本身运行于内存中,如读文件是一个RDD,对文件计算是一个RDD,结果集也是一个RDD ,不同的分片、 数据之间的依赖 、key-value类型的map数据都可以看做RDD。
RDD是基于内存的,是实时读取的。
MapReduce是基于磁盘的,是离线读取的。
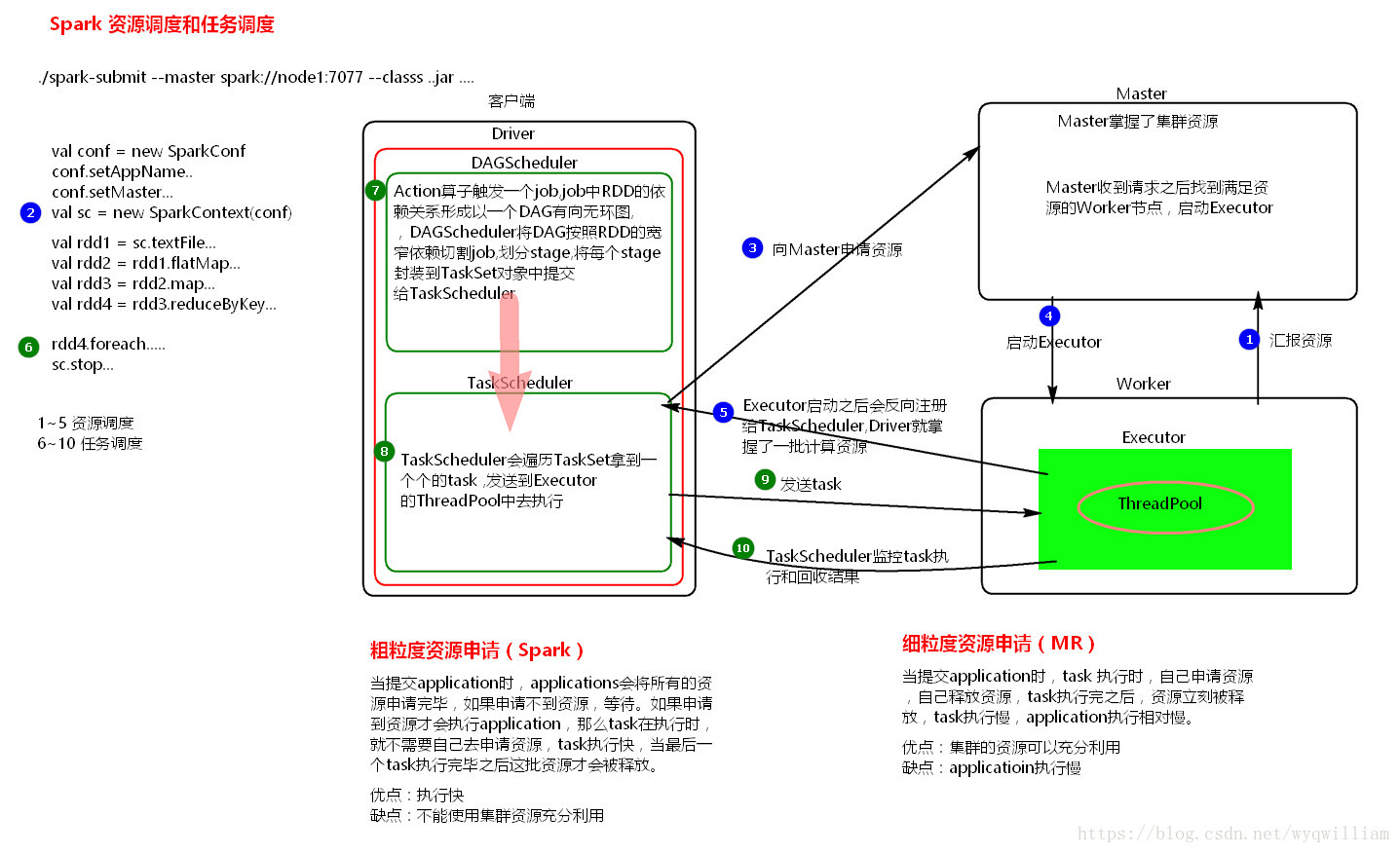
4.Spark代码流程?
1).val conf = new SparkConf().setMaster(...).setAppName(...)
2).val sc = new SparkContext(conf)
3).创建RDD。
4).对RDD使用Transformation类算子进行数据转换。
5).使用Action类算子触发Transformation类算子执行。
如果觉得有用,那就鼓励一下我呗。
