1.介绍
在自动编码器一文中,我们已经简单介绍了基于隐藏神经元数量较小的假设,本文主要基于隐藏神经元数量较大的假设。此时,我们仍然通过给自编码神经网络施加一些其他的限制条件来发现输入数据中的结构。比如我们给隐藏神经元加入稀疏性限制。
稀疏性可以被简单地解释如下:假设神经元的激活函数时sigmoid函数,那么当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。如果使用tanh作为激活函数的话,当神经元输出为-1的时候,我们认为神经元是被抑制的。
2.KL散度
在介绍自动编码器之前,我们先看下KL散度:
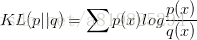
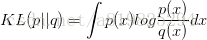
KL散度可以很好地测量两个概率分布之间的距离,比如公式中的p和q。如果两个分布越接近,那么KL散度越小;如果越远,KL散度就会越大。
KL散度的实战——1维高斯分布
我们先来一个相对简单的例子。假设我们有两个随机变量x1,x2,各自服从一个高斯分布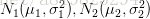
我们知道:
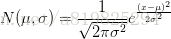
那么KL(p1,p2)就等于

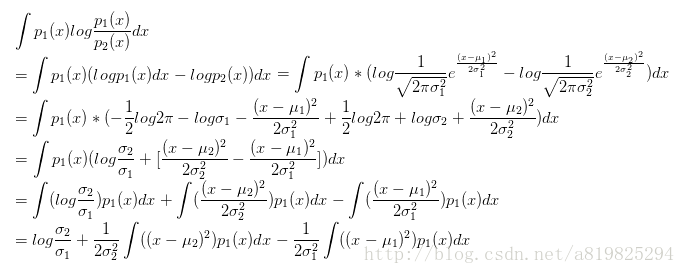
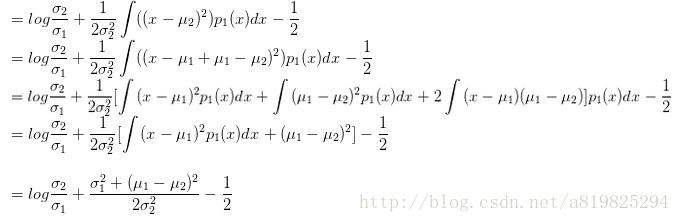
同理:多维高斯分布的KL散度
首先给出多维高斯分布的公式:
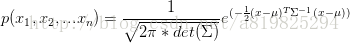
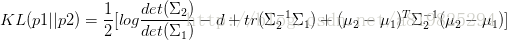
3.稀疏 based on KL散度
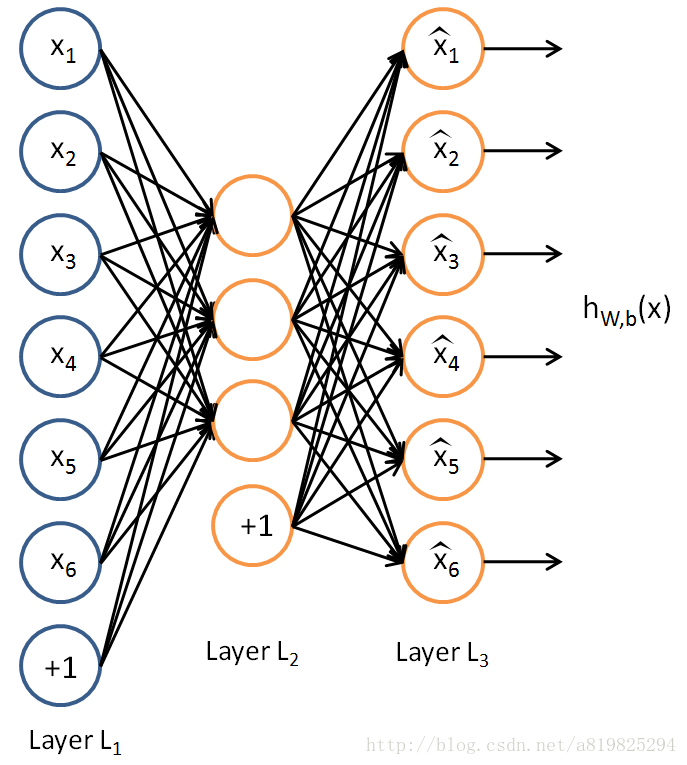
注意到图1中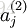
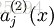
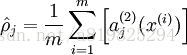
表示隐藏神经元 j 的平均活跃度(在训练集上取平均)。我们可以近似的加入一条限制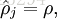
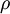
为了实现这一限制,我们将会在我们的优化目标函数中加入一个额外的惩罚因子,而这一惩罚因子将惩罚那些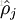
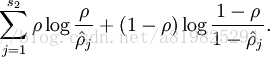
所以,总体代价函数:
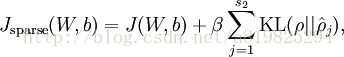
另外还有一种稀疏方式:加L0、L1、L2正则项,可以看参考文献2
基于正则化稀疏的keras实现:
from keras import regularizers
encoding_dim = 32
input_img = Input(shape=(784,))
# add a Dense layer with a L1 activity regularizer
encoded = Dense(encoding_dim, activation='relu',
activity_regularizer=regularizers.activity_l1(10e-5))(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(input=input_img, output=decoded)参考文献:
(1)http://deeplearning.stanford.edu/wiki/index.php/Autoencoders_and_Sparsity
(2)http://deeplearning.stanford.edu/wiki/index.php/Sparse_Coding
(3)Bengio Y,Lamblin P,Popovici D,et al. Greedy layerwise training of deep networks[C]. Proc. of the 20th Annual Conference on Neural Information Processing System.2006: 153-160.
(4)https://zhuanlan.zhihu.com/p/22464760