这篇是风格转移方面的综述,文中总结了多种风格转移的方法。因为18年看过很多风格转移方面的论文,因此翻译这篇综述。
Gatys等人的开创性工作。通过分离和重新组合图像内容和风格,展示了卷积神经网络(CNN)在创作艺术图像方面的力量。使用CNN以不同样式呈现内容图像的该过程被称为神经样式转移(NST)。从那时起,NST已经成为学术文献和工业应用中的热门话题。它正在受到越来越多的关注,并且提出了各种方法来改进或扩展原始NST算法。在本文中,我们的目的是全面概述当前在NST方面取得的进展。我们首先在NST领域提出当前算法的分类。然后,我们提出了几种评估方法,并定性和定量地比较了不同的NST算法。审查结束时讨论了NST的各种应用以及未来研究的未决问题。本评论中讨论的论文清单,相应代码,预先训练的模型和更多比较结果可在以下网址公开获取:https://github.com/ycjing/Neural-Style-Transfer-Papers。
STYLE TRANSFER WITHOUT NEURAL NETWORKS
艺术风格化是一个长期的研究课题。 由于其广泛的应用,二十多年来它一直是一个重要的研究领域。 在NST出现之前,相关研究已经扩展到一个称为非真实感渲染(NPR)的领域。 在本节中,我们将简要介绍一些没有CNN的艺术渲染(AR)算法。 具体而言,我们专注于2D图像的艺术风格化,在[14]中称为基于图像的艺术渲染(IB-AR)。 有关IB-AR技术的更全面概述,我们建议[3],[14],[15]。 遵循由Kyprianidis等人定义的IB-AR分类法。 [14],我们首先介绍了没有CNN的每类IB-AR技术,然后讨论它们的优缺点。
Stroke-Based Rendering:
基于笔画的渲染。 基于笔划的渲染(SBR)是指在数字画布上放置虚拟笔划(例如,笔刷笔触,平铺,点画)以渲染具有特定样式的照片的过程[16]。 SBR的过程通常从源照片开始,逐渐合成笔画以匹配照片,并最终产生非真实照片,其看起来像照片但具有艺术风格。 在此过程中,目标函数被设计用于指导笔画的贪婪或迭代放置。
Region-Based Techniques:
基于地区的技术。 基于区域的渲染是结合区域分割以基于区域中的内容实现渲染的自适应。 早期基于区域的IB-AR算法利用区域的形状来指导中风放置[17],[18]。 以这种方式,可以在图像中的不同语义区域中产生不同的笔划图案。 宋等人。 [19]进一步提出了一种基于区域的IB-AR算法来操纵艺术风格的几何。 他们的算法通过用几个规范形状替换区域来创建简化的形状渲染效果。 考虑到地区的提升需要对细节层面进行控制。 然而,SBR中的问题仍然存在:基于一个区域的渲染算法无法模拟任意样式。
Example-Based Rendering:
基于示例的渲染。 基于示例的渲染的目标是学习示例对之间的映射。 这类IB-AR技术是由Hertzmann等人提出的,他提出了一个名为图像类比的框架[9]。 图像类比旨在以受监督的方式学习一对源图像和目标风格化图像之间的映射。 图像类比训练集包括成对的未校正的源图像和具有特定样式的相应的程式化图像。 然后,图像类比算法从示例训练对中学习类似变换,并在给出测试输入照片时创建类似的程式化结果。 图像类比也可以以各种方式扩展,例如,以学习用于肖像绘制渲染的笔划放置[20]。
一般来说,图像类比对各种艺术风格都有效。 但是,实际上通常无法获得成对的训练数据。 另一个限制是图像类比仅利用低级图像特征。 因此,图像类比通常无法有效捕获内容和样式,从而限制了性能
Image Processing and Filtering:
创建艺术形象是一个旨在简化图像简化和抽象的过程。 因此,考虑采用和组合一些相关的图像处理滤波器来渲染给定的照片是很自然的。 例如,在[21]中,Winnem¨oller等人。 首次利用双边[22]和高斯滤波器[23]的差异自动产生卡通效果。
与其他类别的IB-AR技术相比,基于图像滤波的渲染算法通常可以直接实现并且在实践中有效。 在费用上,他们的风格多样性非常有限。

摘要。 基于上述讨论,虽然一些没有CNN的IB-AR算法能够忠实地描绘某些规定的风格,但它们通常在灵活性,风格多样性和有效的图像结构提取方面具有局限性。因此,需要新颖的算法。 解决这些限制,从而产生了NST的领域。
DERIVATIONS OF NEURAL STYLE TRANSFER
神经传递的衍生
为了更好地理解NST的发展,我们首先介绍它的推导。 为了自动转换艺术风格,第一个也是最重要的问题是如何从图像中建模和提取样式。 由于样式与纹理1非常相关,因此直观的方法是将视觉样式建模与之前经过深入研究的视觉纹理建模方法联系起来。在获得样式表示之后,问题是如何在保留其内容的同时利用期望的样式信息来重建图像,这通过图像重建技术来解决。
Visual Texture Modelling
视觉纹理建模[24]以前被研究作为纹理合成的核心[25],[26]。 在整个历史中,有两种不同的方法来模拟视觉纹理,即使用汇总统计的参数化纹理建模和使用马尔可夫随机场(MRF)的非参数纹理建模。
1)具有汇总统计的参数化纹理建模。纹理建模的一条途径是从样本纹理中捕获图像统计信息,并利用摘要统计属性来对纹理进行建模。这个想法首先由Julesz [27]提出,他将纹理建模为基于像素的N阶统计量。 后来,[28]中的工作利用过滤器分析纹理的响应,而不是直接的基于像素的测量。 之后,Portilla和Simoncelli [29]进一步引入了基于多尺度定向滤波器响应的纹理模型,并使用梯度下降来改善合成结果。Gatys等人提出的更新的参数纹理建模方法。 [30]是第一个测量CNN领域的汇总统计数据。 他们设计了一种基于Gram的表示来模拟纹理,这是预训练分类网络(VGG网络)不同层中过滤器响应之间的相关性[31]。更具体地说,基于Gram的表示编码CNN滤波器响应集的二阶统计量。 接下来,我们将详细解释此表示,以便使用以下部分。
假设样本纹理图像的特征图在预训练的深度分类网络的第1层是![]()
C是通道数,H和W待变特征图F的高度和宽度。基于Gram的表示可以通过计算Gram矩阵获取((Fl(Is)的重新形成版本)

来自CNN的这种基于Gram的纹理表示有效地模拟了天然和非自然纹理的各种变化。 然而,基于Gram的表示旨在捕获全局统计数据并抛出空间排列,这导致用于建模具有长距离对称结构的常规纹理的结果令人不满意。为了解决这个问题,Berger和Memisevic [32]提出用δ像素水平和垂直地转换特征图,以将位置(i,j)处的特征与位置(i +δ,j)和(i,j +)处的特征相关联。δ)。通过这种方式,表示结合了空间排列信息,因此在建模具有对称属性的纹理时更有效。
2)使用MRF进行非参数纹理建模。 另一个值得注意的纹理建模方法是使用非参数重采样。 各种非参数方法基于MRF模型,其假设在纹理图像中,每个像素完全由其空间邻域表征。在这种假设下,Efros和Leung [25]建议通过搜索源纹理图像中的相似邻域并分配相应的像素来逐个合成每个像素。 他们的工作是最早的MRF非参数算法之一。 在他们的工作之后,Wei和Levoy [26]通过始终使用固定的邻域来进一步加快邻域匹配过程。
Image Reconstruction
通常,许多视觉任务的关键步骤是从输入图像中提取抽象表示。 图像重建是一个逆过程,它是从提取的图像表示中重建整个输入图像。先前研究过分析特定图像表示并发现抽象表示中包含哪些信息。这里主要关注CNN基于图像优化的图像重构(IOB-IR)和基于模型优化的图像重建(MOB-IR)。
1)基于图像优化的在线图像重建。 第一种反转CNN表示的算法由Mahendran和Vedaldi提出[33],[34]。 给定要反转的CNN表示,他们的算法迭代地优化图像(通常从随机噪声开始),直到它具有类似的期望CNN表示。迭代优化过程基于图像空间中的梯度下降。因此,该过程是耗时的,尤其是当期望的重建图像很大时。
2)基于模型优化的图像重建。 为了解决[33],[34]的效率问题,Dosovitskiy和Brox [35]建议提前训练前馈网络并将计算负担置于训练阶段。在测试阶段,可以通过网络前向传递简单地完成相反的过程。 他们的算法显着加快了图像重建过程。 在他们后来的工作[36]中,他们进一步结合了生成对抗网络(GAN)[37]来改进结果。
A TAXONOMY OF NEURAL STYLE TRANSFER ALGORITHMS
NST是上述基于示例的IB-AR技术的子集。 在本节中,我们首先提供NST算法的分类,然后详细解释主要的基于2D图像的非真实感NST算法(图2,紫色框)。更具体地说,对于每种算法,我们首先介绍主要思想,然后讨论它的弱点和优势。 由于定义风格[3],[38]的概念很复杂,因此非常主观地定义哪个标准对于成功的风格转换算法很重要[39],这里我们尝试以更加结构化的方式评估这些算法 只关注细节,语义,深度和笔触的变化2。我们将在第8节中更多地讨论美学评价标准的问题,并在第6节中提出更多的评价结果。
我们提出的NST技术分类如图2所示。我们保留了Kyprianidis等人提出的IB-AR技术的分类。 [14]未受影响并通过NST算法扩展它。 当前的NST方法分为两类:基于图像优化的在线神经方法(IOB-NST)和基于模型优化的基于神经网络方法(MOB-NST)。第一类通过迭代地优化图像来传送样式,即,属于该类别的算法是基于IOB-IR技术构建的。 第二类优化了离线的生成模型,并通过单个前向传递产生风格化图像,其利用了MOB-IR技术的思想。
4.1 Image-Optimisation-Based Online Neural Methods
DeepDream [40]是通过使用IOB-IR技术反转CNN表示来产生艺术图像的第一次尝试。 通过进一步将视觉纹理建模技术与模型风格相结合,随后提出了IOB-NST算法,为NST领域构建了早期基础。 他们的基本思想是首先从相应的风格和内容图像中建模和提取风格和内容信息,将它们重新组合为目标表示,然后迭代地重建与目标表示匹配的风格化结果。 通常,不同的IOBNST算法共享相同的IOB-IR技术,但它们对视觉样式进行建模的方式不同,视觉样式是基于上述两类视觉纹理建模技术构建的。 IOB-NST算法的共同限制是由于迭代图像优化过程,它们在计算上是昂贵的。
4.1.1 Parametric Neural Methods with Summary Statistics
IOB-NST方法的第一个子集基于带有摘要统计的参数纹理建模。 该样式被表征为一组空间摘要统计。
我们首先介绍Gatys等人提出的第一个NST算法。 [4],[10]。 通过重建VGG-19网络中间层的表示,Gatys等人。 观察到深度卷积神经网络能够从任意照片和来自着名艺术品的一些外观信息中提取图像内容。根据这一观察,他们通过惩罚从内容和程式化图像派生的高级表示的差异来构建新风格化图像的内容组件,并通过匹配基于Gram的样式概要统计和程式化图像来构建样式组件, 这是从他们提出的纹理建模技术[30](第3.1节)得出的。 其算法的细节如下。
给定内容图像Ic和样式图像Is,[4]中的算法试图寻找最小化以下目标的程式化图像I.

其中Lc将给定内容图像的内容表示与风格化图像的内容表示进行比较,并且Ls将从样式图像导出的基于Gram的样式表示与风格化图像的表示进行比较。 α和β用于平衡风格化结果中的内容组件和样式组件。
内容损失Lc由层1中的内容图像Ic的特征表示F1与用噪声图像初始化的风格化图像I的特征表示F1之间的平方欧几里德距离来定义:

其中{lc}表示用于计算内容丢失的VGG层集。 对于样式损失Ls,[4]利用基于Gram的视觉纹理建模技术对样式进行建模,这已经在3.1节中进行了解释。 因此,样式损失是由Is和I的基于Gram的样式表示之间的欧几里德距离的平方定义的:
其中G是前面提到的Gram矩阵,用于编码滤波器响应集的二阶统计量。 {ls}表示用于计算样式丢失的VGG图层集。
内容和样式层的选择是样式转移过程中的一个重要因素。 不同的位置和层数可以导致非常不同的视觉体验。 鉴于预先训练的VGG-19 [31]作为损失网络,Gatys等人在[4]中选择{ls}和{lc}是{ls} = {relu1 1,relu2 1,relu3 1, relu4 1,relu5 1}和{lc} = {relu4 2}。对于{ls},组合多个层(高达高层)的想法对于Gatys等人的NST算法的成功至关重要。 匹配多尺度样式表示导致更平滑和更连续的样式化,这给出了视觉上最吸引人的结果[4]。对于内容层{lc},匹配较低层上的内容表示保留了不期望的结构(例如,风格化期间原始内容图像的,边缘和颜色图)。相反,通过匹配网络的较高层上的内容,可以改变细节结构以与期望的样式一致,同时保留内容图像的内容信息。 此外,使用基于VGG的损失网络进行样式转移不是唯一的选择。 通过选择其他预训练的分类网络,例如ResNet [41],可以实现类似的性能。
在等式(2)中,Lc和Ls是可微分的。 因此,利用随机噪声作为初始I,可以通过在具有反向传播的图像空间中使用梯度下降来最小化等式(2)。 此外,通常在实践中添加总方差去噪术语以鼓励程式化结果的平滑性。
Gatys等人的算法。 不需要用于训练的地面实况数据,也没有对样式图像类型的明确限制,这解决了以前没有CNN的IB-AR算法的局限性(第2节)。然而,由于CNN特征不可避免地会丢失一些低级信息,因此Gatys等人的算法在风格化过程中不能保持细节结构和细节的一致性。而且,由于基于Gram的样式表示的局限性,它通常不能用于照片级真实感合成。更重要的是,它没有考虑画笔笔画的变化以及内容图像中包含的语义和深度信息,这些是评估中的重要因素
此外,基于Gram的样式表示不是统计编码样式信息的唯一选择。 还有一些其他有效的统计风格表示,它们来自基于Gram的表示。 李等人[42]通过考虑转移学习领域中的风格转移,或更具体地,领域适应[43],得出一些不同的风格表征。鉴于来自不同分布的训练和测试数据,域适应的目标是使来自源域的标记训练数据训练的模型适应于预测来自目标域的未标记测试数据的标记。域适应的一种选择是匹配样本 通过最小化它们的分布差异,在源域中与目标域中的分布差异,其中最大均值差异(MMD)是衡量两个分布之间差异的流行选择。 李等人。 证明在一对样式和风格化图像之间匹配基于Gram的样式表示本质上是使用二次多项式内核最小化MMD。因此,期望MMD的其他核函数可以在NST中同等地应用,例如线性核,多项式核和高斯核。 另一个相关的表示是批量标准化(BN)统计表示,它使用VGG图层中要素图的均值和方差来建模样式:

其中F1c∈RH×W是VGG网络的第一层的第c个特征映射信道,C1是信道的数量。
Li等人算法的主要贡献在于理论上证明了NST中的Gram矩阵匹配过程相当于用二阶多项式核最小化MMD,从而提出了对NST的及时解释并使NST原理更加清晰。 但是,Li等人的算法。 没有解决Gatys等人的算法的上述限制。
基于Gram的算法的一个限制是其在优化期间的不稳定性。 此外,它需要手动调整参数,这是非常繁琐的。 Risser等。 [44]发现具有完全不同的均值和方差的特征激活仍然可以具有相同的革兰矩阵,这是稳定性的主要原因。在这种观察的情况下,Risser等人。 引入额外的直方图损失,引导优化以匹配特征激活的整个直方图。 它们还提供了自动参数调整的初步解决方案,即通过极端梯度归一化明确地防止具有极值的梯度。
通过额外匹配特征激活的直方图,Risser等人的算法。 通过更少的迭代和参数调整工作实现更稳定的样式传输。 然而,它的好处是以高计算复杂性为代价。 此外,Gatys等人的算法的上述缺点仍然存在,例如缺乏深度考虑和细节的一致性。
所有这些上述神经方法仅比较CNN特征空间中的内容和风格化图像,以使风格化图像在语义上与内容图像相似。 但由于CNN特征不可避免地丢失了图像中包含的一些低级信息,因此在程式化结果中通常会出现一些不具吸引力的扭曲结构和不规则的伪像。为了在风格化过程中保持细节结构的连贯性,Li等人。 [45]建议在像素空间中的低级特征上加入附加约束。 它们引入了一个额外的拉普拉斯损失,它被定义为方位图像的拉普拉斯滤波器响应与程式化结果之间的平方欧几里德距离。 拉普拉斯滤波器计算图像中像素的二阶导数,并广泛用于边缘检测。
Li等人的算法。 在风格化过程中保留了细节结构和细节方面具有良好的表现。但它在语义,深度,画笔笔划的变化等方面仍然缺乏考虑。
4.1.2 Non-parametric Neural Methods with MRFs
非参数化IOB-NST是在基于MRF的非参数化纹理建模的基础上建立起来的。此类别在本地级别考虑NST,即在补丁上操作以匹配样式。
LI和Wand[46]是第一个提出基于MRF的NST算法。他们发现,带有汇总统计的参数化NST方法只捕获了令人困惑的特征相关性,并且不限制空间布局,这导致了照片真实感样式在视觉上不太可信的结果。他们的解决方案是以非参数化的方式对样式进行建模,并引入一个新的样式丢失函数,其中包括基于补丁的MRF:
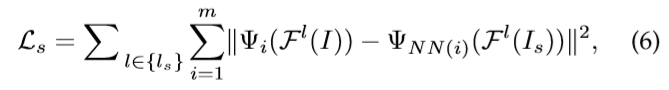
式中,ψ(fl(i))是特征图fl(i)中所有局部斑块的集合。ψi表示第i个局部面片,ψnn(i)是样式化图像i中与第i个局部面片最相似的样式面片。通过计算样式图像中所有样式块的归一化互相关,得到最佳匹配的ψnn(i)。m是本地补丁的总数。由于他们的算法匹配补丁级别的样式,因此可以更好地保留文件结构和排列。
LI和Wand算法的优点在于,当内容照片和样式在形状和角度上相似时,由于基于补丁的MRF丢失,它在照片真实感样式(或者更具体地说)中表现得特别好。然而,当内容和样式图像在透视和结构上存在很大差异时,由于图像补丁无法正确匹配,通常会失败。它在保存清晰的细节和深度信息方面也受到限制。
4.2 Model-Optimisation-Based Offline Neural Methods
虽然IOB-NST能够生成令人印象深刻的风格化图像,但仍然存在一些限制。最令人担忧的限制是效率问题。第二类mobst通过利用mob-ir重建风格化结果来解决速度和计算成本问题,也就是说,对于一个或多个风格的图像,前馈网络g在一组图像IC上优化为:
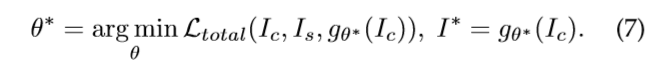
根据一个G可以产生的艺术风格的数量,MOB-NST算法进一步分为PerStyle per model(PSPM)MOB-NST方法、Multiple Styleper model(MSPM)MOB-NST方法和任意Styleper model(ASPM)MOB-NST方法。
4.2.1 Per-Style-Per-Model Neural Methods
1)具有汇总统计的参数化PSPM。前两种MOB-NST算法由Johnson等人提出。[47]和Ulyanov等人[48]分别。这两种方法有一个相似的想法,即预先训练前馈式专用网络,并在测试阶段通过一次前馈,产生一个风格化的结果。它们只在网络架构上有所不同,Johnson等人他的设计粗略地遵循了阿德福德等人提出的网络方案。但对于剩余块以及分段跨步卷积,Ulyanov等人使用多尺度结构作为发电机网络。目标函数类似于Gatys等人的算法。[4]表明它们也是具有汇总统计的参数化方法。
Johnson等人和乌里扬诺夫等人的算法实现了实时风格转换。然而,它们的算法设计基本上遵循了Gatys等人的算法,这使得它们与Gatys等人的算法同样面临上述问题(例如,在细节和深度信息的一致性方面缺乏考虑)。
在[47]、[48]之后不久,Ulyanov等人[50]进一步发现,简单地对每一个图像而不是一批图像应用归一化(精确的批量归一化(bn))会导致样式化质量的显著提高。这种单一图像归一化称为实例归一化(in),当批量大小设置为1时,这相当于批量归一化。带有in的样式传输网络的收敛速度比bn快,并且在视觉上也取得了更好的效果。一种解释是in是样式归一化的一种形式,可以直接将每个内容图像的样式归一化为所需的样式[51]。因此,这个目标更容易学习,因为网络的其他部分只需要处理内容丢失。
2)带MRF的非参数PSPM。Li和Wand[52]的另一项工作受到了第4.1.2节中基于MRF的NST[46]算法的启发。他们通过使用对抗性训练来训练马尔可夫前馈网络来解决效率问题。与[46]相似,他们的算法是一种基于补丁的非参数化MRF方法。结果表明,该方法优于Johnson等人的算法。乌里扬诺夫等人由于其基于补丁的设计,在复杂图像中保留了连贯的纹理。然而,他们的算法对于非纹理样式(例如,人脸图像)的性能不太满意,因为他们的算法在语义上缺乏考虑。他们算法的其他缺点包括缺乏对深度信息的考虑和画笔笔画的变化,这是重要的视觉因素。
4.2.2 Multiple-Style-Per-Model Neural Methods
虽然上述的PSPM方法可以比以前的IOBNST方法更快地生成两个数量级的风格化图像,但是必须为每个特定的风格图像训练单独的生成网络,这是非常耗时和灵活的。但许多绘画(如印象派绘画)都有相似的笔触,只是在色彩调色板上有所不同。直观地说,为每个人训练一个单独的网络是多余的。因此,提出了MSPM,进一步将多种样式合并到一个模型中,从而提高了PSPM的灵活性。处理这个问题通常有两条途径:1)将网络中的少量参数与每种样式联系起来([53],[54]),2)仍然只利用一个像pspm这样的网络,但将样式和内容作为输入结合起来([55],[56])。
1)仅将少量参数绑定到每个样式。Dumoulin等人的早期研究。[53]是根据PSPM算法[50]中建议的层内算法(第4.2.1节)构建的。他们出人意料地发现,使用相同的卷积参数,但只有层中的缩放和移动参数才能够模拟不同的样式。因此,他们提出了一种基于条件实例归一化(CIN)的条件多式传输网络训练算法,其定义如下:
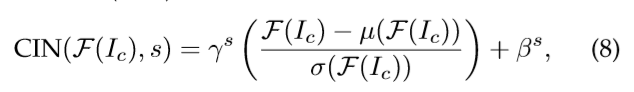
其中f是输入特征激活,s是一组样式图像中所需样式的索引。如式(8)所示,每种类型的调节是通过将特征激活f(ic)归一化后的参数γs和βs进行缩放和移动来完成的,即每种类型都可以通过调整一系列的参数转换来实现。解释与第4.2.1节中的[50]类似,即使用不同系列的参数对特征统计进行归一化,可以将输入内容图像归一化为不同的样式。此外,Dumoulin等人的算法。还可以通过组合不同样式的固定参数,到将多种样式扩展组合到一个单一样式化结果中。
Chen等人提出了另一种遵循MSPM第一条路径的算法。[54]。 他们的想法是明确地分离样式和内容,即使用单独的网络组件来学习相应的内容和样式信息。 更具体地说,他们使用中级卷积滤波器(称为“StyleBank”层)来单独学习不同的风格。 每个样式都绑定到“StyleBank”图层中的一组参数。 网络中的其余组件用于学习内容信息,这些信息由不同的样式共享。 他们的算法还支持灵活的增量训练,即训练网络中的内容组件,并且只为新风格训练“StyleBank”层。
总之,Dumoulin等人的算法都是如此。 和陈等人学习新风格和灵活控制风格融合需要付出很少的努力。 然而,它们没有解决NST算法的常见限制,例如,缺少细节,语义,深度和画笔笔划的变化。
2)将风格和内容结合起来作为输入。 第一类的一个缺点是模型尺寸通常随着学习样式数量的增加而变大。 MSPM的第二条路径通过充分探索单一网络的能力,并将内容和风格结合到网络中进行风格识别来解决这一局限性。 不同的MSPM算法在将样式合并到网络中的方式不同。
在[55]中,给定N个目标样式,Li等人。 设计一个样式选择的选择单元,它是一个N维单热矢量。 选择单元中的每个位代表目标样式集中的特定样式。 对于选择单元中的每个位,Li等人。 首先从均匀分布中采样相应的噪声图f(Is),然后将f(Is)馈入样式子网络以获得相应的样式编码特征F(f(Is))。 通过将样式编码特征F(f(Is))和内容编码特征Enc(Ic)的串联馈送到样式传送网络的解码器部分Dec中,可以产生期望的程式化结果:I = Dec(F( f(Is))⊕Enc(Ic))。
Zhang和Dana [56]的另一项工作首先通过预先训练的VGG网络转发每个风格图像,并获得不同VGG层中的多尺度特征激活F(Is)。 然后,通过其提出的灵感层,将多尺度F(Is)与来自编码器中的不同层的多尺度编码特征Enc(Ic)组合。 灵感层设计用于重塑F(Is)以匹配所需的尺寸,并且还具有可学习的权重矩阵以调整特征图以帮助最小化目标函数。
第二种类型的MSPM解决了第一类MSPM中增加的模型尺寸的限制。 第二种类型的MSPM的样式可扩展性要小得多,因为只有一个网络用于多种样式。 我们将在第6节中定量比较不同MSPM算法的样式可扩展性。此外,第一类MSPM中存在一些上述限制,即第二类MSPM算法仍然受限于保持细节结构的相干性和深度信息。
4.2.3 Arbitrary-Style-Per-Model Neural Methods
第三类,ASPM-MOB-NST,旨在实现单模式全能,即一种单一的可训练模型,以传递任意艺术风格。 还有两种类型的ASPM,一种建立在使用MRF的非参数纹理建模上,另一种建立在使用摘要统计的参数化纹理建模之上。
1)具有MRF的非参数ASPM。 第一个ASPM算法由Chen和Schmidt [57]提出。 他们首先从预先训练的VGG网络中计算的内容和样式特征激活中提取一组激活补丁。 然后他们将每个内容补丁匹配到最相似的样式补丁并交换它们(在[57]中称为“样式交换”)。可以通过使用IOB-IR或MOB-IR技术在“样式交换”之后重建所得到的激活图来产生程式化结果。 Chen和Schmidt的算法比以前的方法更灵活,因为它具有单模型的特点。但是[57]的程式化结果不太吸引人,因为内容补丁通常与不代表所需风格的样式补丁交换。 因此,内容得到很好的保留,而风格通常不会很好地反映出来。
2)具有汇总统计的参数化ASPM。 考虑到4.2.2节中的[53],任意样式转移的最简单方法是训练一个单独的参数预测网络P,用多种训练方式[58]预测方程(8)中的γs和βs。 给定测试样式图像Is,样式传递网络中的CIN层从P(Is)获取参数γs和βs,并且通过前向传递将输入内容图像归一化为期望的样式。
基于[53]的另一种类似方法由Huang和Belongie [51]提出。 Huang和Belongie建议将等式(8)中的条件实例归一化(CIN)修改为自适应实例归一化(AdaIN),而不是训练参数预测网络:
 |
AdaIN在内容和样式特征激活之间传递渠道方面的均值和方差特征统计,这与[57]也有类似的想法。 与[53]不同,[51]的样式传输网络中的编码器是固定的,并且包括预训练的VGG网络中的前几层。因此,[51]中的F是来自预训练的VGG网络的特征激活。 解码器部分需要使用大量样式和内容图像进行训练,以在AdaIN到样式化结果之后解码所得到的特征激活:I = Dec(AdaIN(F(Ic),F(Is)))。
Huang和Belongie [51]的算法是实现实时样式化的第一个ASPM算法。 然而,Huang和Belongie [51]的算法是数据驱动的,并且局限于看不见的风格。 此外,简单地调整要素统计的均值和方差使得难以合成具有丰富细节和局部结构的复杂样式模式。
Li等人最近的一项工作。 [59]试图利用一系列特征变换以一种无风格学习方式转移任意艺术风格。 与[51]类似,Li等人。 使用预先训练的VGG的前几层作为编码器并训练相应的解码器。 但是他们用一对白化和着色变换(WCT)代替编码器和解码器之间的AdaIN层[51]:I = Dec(WCT(F(Ic),F(Is)))。他们的算法建立在观察美白变换可以去除风格相关信息并保留内容结构的基础上。 因此,从编码器接收内容激活F(Ic),白化变换可以过滤输入内容图像中的原始样式并返回仅具有内容信息的过滤表示。然后,通过应用着色变换,将包含在F(Is)中的样式模式合并到滤波的内容表示中,并且可以通过解码变换的特征来获得程式化的结果I. 他们还将这种单级风格化扩展到多级风格化,以进一步提高视觉质量。
Li等人的算法。 是第一个以无学习方式传递艺术风格的ASPM算法。 因此,与[51]相比,它没有泛化能力的限制。 但李等人的算法。 仍然无法产生尖锐的细节和细微的笔触。 样式化结果将在第6节中显示。此外,它在保留深度信息和画笔笔划的变化方面缺乏考虑因素。
5 IMPROVEMENTS AND EXTENSIONS
自NST算法出现以来,还有一些研究致力于通过控制感知因素(例如,笔画大小控制,空间样式控制和颜色控制)来改进当前的NST算法(图2,绿框)。 而且,所有上述NST方法都是针对一般静止图像而设计的。 它们可能不适合于特殊类型的图像和视频(例如,涂鸦,头像和视频帧)。 因此,各种后续研究(图2,粉红色框)旨在将一般NST算法扩展到这些特定类型的图像,甚至将它们扩展到艺术图像样式(例如,音频样式)之外。
控制神经风格转移中的感知因素。 加蒂等人他们自己[60]提出了几个微小的修改来改进他们以前的算法[4]。 他们展示了一种空间风格控制策略来控制内容图像每个区域的风格。 他们的想法是为内容和风格图像的特征激活定义引导通道。引导通道具有[0,1]的值,指定哪个样式应该转移到哪个内容区域,即内容引导通道的内容区域。 应使用样式引导通道等于1的样式呈现1。对于颜色控制,原始NST算法产生具有样式图像的颜色分布的风格化图像。 然而,有时人们更喜欢保持颜色的样式转移,即在样式转移期间保留内容图像的颜色。 相应的解决方案是首先在样式传输之前变换样式图像的颜色以匹配内容图像的颜色,或者仅在亮度通道中执行样式传送。
对于笔划大小控制,问题要复杂得多。 我们在图3中显示了中风大小控制的样本结果。中风大小控制策略的讨论需要分成几个案例[61]:
1)具有非高分辨率图像的IOB-NST:由于当前样式统计(例如,基于Gram和基于BN的统计)是尺度敏感的[61],为了实现不同的笔划大小,解决方案只是调整给定的大小 风格图像到不同的尺度。
2)具有非高分辨率图像的MOB-NST:一种可能的解决方案是在前向通过之前将输入图像调整到不同的比例,这不可避免地损害了样式化质量。 另一种可能的解决方案是训练具有不同尺度的样式图像的多个模型,这是消耗空间和时间的。 而且,可能的解决方案不能保持具有不同笔划尺寸的结果之间的笔划一致性,即,结果在笔划方向,笔划配置等方面变化。然而,用户通常希望仅改变笔划大小而不改变其他大小。 为了解决这个问题,Jing等人。 [61]提出了一种可控制的PSPM算法。 他们的算法的核心部分是StrokePyramid模块,它通过自适应接收场学习不同的笔画大小。在不牺牲质量和速度的情况下,他们的算法首先利用单个模型来实现灵活的连续笔画大小控制,同时保持笔画一致性,并进一步实现空间笔画大小控制以产生新的艺术效果。 虽然也可以使用ASPM算法来控制笔划大小,但ASPM会降低质量和速度。 因此,与[61]相比,ASPM在产生细节和细节方面无效。
3)具有高分辨率图像的IOB-NST:对于高分辨率图像(例如,[60]中的3000×3000像素),通过简单地将样式图像大规模地调整大小,不能实现大的笔划尺寸。 由于只有具有接收场尺寸VGG的内容图像中的区域可能受到损耗网络中的神经元的影响,因此在具有接收场尺寸的小图像区域中,大的和较大的笔刷笔划之间几乎没有视觉差异。 加蒂等人。 [60]通过提出粗略到最终的IOB-NST程序,通过下采样,样式化,上采样和最终样式化的几个步骤来解决这个问题。
4)具有高分辨率图像的MOB-NST:类似于3),风格化结果中的笔划大小不随高分辨率图像的样式图像比例而变化。 该解决方案也类似于Gatys等人。 [60]中的算法,这是一种粗略的风格化程序[62]。 我们的想法是利用包含多个子网的多模型。 每个子网接收前一个子网的上采样程式化结果作为输入,并用更精细的笔划再次对其进行样式化。
当前NST算法的另一个限制是它们不考虑图像中包含的深度信息。 为了解决这一局限性,提出了深度保持NST算法[63]。他们的方法是在[47]的基础上增加深度损失函数来测量内容图像和程式化图像之间的深度差异。 通过应用单图像深度估计算法(例如,Chen等人在[64]中的工作)来获取图像深度。
语义风格转移。 给定一对内容相似的风格和内容图像,语义风格转移的目的是在风格和内容之间建立语义对应关系,将每个风格区域映射到对应的语义相似的内容区域。 然后将每个样式区域中的样式转移到语义上相似的内容区域。
1)基于图像优化的语义风格转移。 由于补丁匹配方案自然满足基于区域的通信的要求,Champandard [65]提出基于上述基于补丁的算法[46](第4.1.2节)构建语义样式转移算法。 尽管由Li和Wand [46]算法产生的结果接近于语义风格转移的目标,[46]并没有包含准确的分割掩码,这有时会导致错误的语义匹配。因此,Champandard在[46]上增加了一个额外的语义通道,这是一个下采样的语义分割图。 分割图可以手动注释,也可以来自语义分割算法[66],[67]。 尽管[65]有效,但基于MRF的设计并非唯一的选择。 Chen和Hsu [68]没有结合MRF先验,而是提供了一种语义风格转移的替代方法,即利用掩蔽过程来约束空间对应,并且还有一个更高阶的样式特征统计来进一步改善结果。 最近,Mechrez等人。 [69]提出了一种替代的语境损失,以无分割的方式实现语义风格转移。
2)基于模型优化的语义风格转移。 和以前一样,效率问题始终是一个大问题。 [65]和[68]都基于IOB-NST算法,因此留有很大的改进空间。 Lu等人。 [70]通过优化特征空间中的目标函数而不是像素空间来加速该过程。 更具体地说,他们建议进行特征重建,而不是像以前的算法那样进行图像重建。 这种优化策略减少了计算负担,因为损失不需要通过深层网络传播。 利用训练好的解码器将得到的重构特征解码成最终结果。由于[70]的速度没有达到实时,因此仍有很大的空间可供进一步研究。
实例样式转移。 实例样式传输基于实例分割,旨在仅对图像中的单个用户指定对象进行样式化。 挑战主要在于程式化对象和非固定背景之间的过渡。 Castillo等。 [71]通过向平滑和抗别名边界像素添加额外的基于MRF的损失来解决此问题。
涂鸦风格转移。 在[65]中可以找到一个有趣的扩展,即利用NST将粗略的草图转换为精美的艺术作品。 该方法简单地丢弃内容丢失术语并使用涂鸦作为分割图来进行语义样式转移。
立体风格转移。 受AR / VR需求驱动,陈等人。 [72]提出了用于立体图像的立体NST算法。 他们提出差异损失来惩罚双向差异。 他们的算法被证明可以为不同的视图产生更一致的笔画。
纵向样式Transfer.Current样式传输算法通常不针对头像进行优化。 由于它们没有施加空间限制,直接将这些现有算法应用于头部肖像会使面部结构变形,这对人类视觉系统来说是不可接受的.Selimet al。 [73]解决了这个问题并将[4]扩展到头像转移。 他们建议使用增益图的概念来约束空间配置,这可以在传递风格图像的纹理时保留面部结构。
视频风格转移。 用于视频序列的NST算法基本上是在Gatys等人的静止图像的第一个NST算法之后不久提出的[4]。 与静止图像样式传递不同,视频样式传递算法的设计需要考虑相邻视频帧之间的平滑过渡。 像以前一样,我们将相关算法划分为基于图像优化和基于模型优化的视频样式转换。
1)基于图像优化的在线视频风格转移。 第一种视频样式传输算法由Ruder等人提出。 [74],[75]。 它们引入了基于光学流动的时间一致性损失,以惩罚沿点轨迹的偏差。 光流通过使用新型光学流动估计算法计算[76],[77]。 结果,他们的算法消除了时间假象并产生了流畅的风格化视频。然而,他们在[4]上构建他们的算法并且需要几分钟来处理单个帧。
2)基于模型优化的视频样式转换。 一些后续研究专门用于实时定制给定视频。 黄等人。 [78]建议在现有的PSPM算法上增加Ruder等人的时间一致性损失[74]。 给定两个连续帧,使用样式转移网络的两个相应输出直接计算时间一致性损失以促进逐像素一致性,并且引入相应的两帧协同训练策略用于计算时间一致性损失。在[79]中可以找到另一项与[78]有相似想法但又对风格不稳定问题进行探索的并行工作。 与[78],[79]不同,陈等人。 [80]提出了一个流程子网来产生特征流,并在特征空间中包含光流信息。 他们的算法建立在预训练的样式传输网络(编码器 - 解码器对)上,并使用获得的特征流包裹来自预训练的样式编码器的特征激活。
字符样式转移。给出包含多个字符的样式图像,字符样式转移的目标是应用NST生成新字体和文本效果的想法。 在[81]中,Atarsaikhan等人。 直接将[4]中的算法应用于字体样式转换,并获得视觉上合理的结果。 而杨等人。 [82]建议首先表征风格元素并利用提取的特征来指导文本效果的生成。 最近的一项工作[83]设计了用于字形预测的条件GAN模型,以及用于颜色和纹理预测用法的装饰网络。 通过联合训练这两个网络,可以以端到端的方式实现字体样式传输。
逼真的风格转移。 真实感风格转移(也称为色彩风格转移)旨在转移色彩分布的风格。 一般的想法是建立在当前的语义样式转移上,但是消除失真并保留内容图像的原始结构。
1)基于图像优化的照片写实风格转换。 最早的照片写实风格转移方法是由Luan等人提出的。[84]。 他们提出了一个两阶段优化程序,即通过使用非真实感风格转移算法[65]对给定照片进行样式化来初始化优化,然后通过添加照片级正则化来惩罚图像失真。 但由于Luan等人的算法建立在基于图像优化的语义风格转移方法[65]的基础上,因此它们的算法计算成本很高。 与[84]类似,Mechrez等人提出的另一种算法。 [85]也采用两阶段优化程序。 他们建议通过将输出图像中的渐变与内容照片中的渐变相匹配来重新定义非照片写实风格化结果。 与[84]相比,Mechrez等人的算法。 实现更快的照片级逼真的程式化速度。
2)基于模型优化的照片写实风格转换。 Li etal。[86]通过两个步骤(样式化步骤和平滑步骤)处理这个问题来解决[84]的效率问题。 样式化步骤是在[59]中应用NST算法,但是将上采样层替换为未分层,以产生具有较少失真的样式化结果。 然后平滑步骤进一步消除了结构假象。 这两个上述算法[84],[86]主要是为自然图像设计的。 [87]中的另一项工作提出利用GAN将颜色从人类设计的动漫图像转移到草图。 他们的算法展示了一种有希望的现实应用,即现实主义风格传递,即自动图像着色。
属性样式转移。 图像属性通常被称为图像颜色,纹理等。以前,图像属性转移是通过图像类比[9]以监督方式完成的(第2节)。 来自基于补丁的NST [46],Liao等人的想法。 [88]提出了一种深度图像类比来研究CNN特征域中的图像类比。该算法基于匹配技术,实现了弱监督图像类比,即它们的算法只需要一对源图像和目标图像而不是大的训练集。
时尚风格转移。 时尚风格转移以时尚风格形象为目标,生成具有所需时尚风格的服装形象。时尚风格转移的挑战在于保留与基本输入服装相似的设计,同时融合所需的风格图案。 这个想法首先由Jiang和Fu [89]提出。 他们通过提出一对时尚风格的生成器和鉴别器来解决这个问题。
音频风格转移。 除了传输图像样式之外,[90],[91]还将图像样式的域扩展为音频样式,并通过从目标音频传输所需的样式来合成新的声音。 音频风格转移的研究也遵循图像风格转移的路线,即基于音频优化的在线音频风格转移,然后基于模型优化 - 基于音频风格转移。 受基于图像的IOB-NST的启发,Verma和Smith [90]提出了一种基于音频优化的在线音频传输算法,该算法基于在线音频优化。 它们从噪声信号开始,并使用反向传播迭代地优化它。 [91]通过以前馈方式传输音频来提高效率,并可以实时产生结果。
6 EVALUATION METHODOLOGY
NST算法的评估在这个领域仍然是一个开放和重要的问题。 一般而言,有两种主要类型的评估方法可用于NST领域,即定性评估和定量评估。 定性评估依赖于观察者的审美判断。 评估结果与许多因素(例如,参与者的年龄和职业)有关。 虽然定量评估侧重于精确的评估指标,包括时间复杂度,损失变化等。在本节中,我们通过实验比较不同的NST算法的定性和定量。
6.1 Experimental Setup
评估数据集。 总的来说,我们的实验中使用了十种风格图像和二十种内容图像。
对于风格图像,我们选择多种风格的艺术作品,如图4所示。例如,有印象派,立体派,抽象派,现代派,未来派,超现实主义和表现主义艺术。 关于介质,这些艺术品中的一些是在画布上绘制的,而其他的则是用纸板或羊毛,棉花,聚酯等涂漆。此外,我们还尝试对图像特征(例如细节,对比度,复杂性和颜色分布)进行处理。 ),受[92],[93],[95]中作品的启发。 表1给出了我们风格图像的更多详细信息。
对于内容图像,已经有精心挑选和描述良好的基准数据集,用于评估Mold和Rosin的样式化[92],[93],[95]。 他们提出的NPR基准称为NPR一般由覆盖广泛特征(例如,对比度,纹理,边缘和有意义的结构)的图像组成,并且满足许多标准。 因此,我们直接在他们提出的NPR通用基准中使用所选择的二十个图像作为我们的内容图像。
对于基于系列模型优化的算法,MS-COCO数据集[96]用于执行训练。 所有内容图像都不用于训练。
原则。 为了最大限度地提高比较的公平性,我们在实验过程中也遵循以下原则:
1)为了涵盖每个算法中的每个细节,我们尝试使用他们发布的文献中提供的实现。 为了最大化比较的公平性,尤其是速度比较,[10],我们使用了一种流行的基于火炬的开源代码[97],作者也承认了这一点。 在我们的实验中,除了基于TensorFlow的[32],[53]之外,所有其他代码都是基于Torch 7实现的。
2)由于视觉效果受到内容和风格重量的影响,因此很难将结果与不同程度的风格进行比较。 由于在每种算法中计算损失的不同方式(例如,内容和样式层的不同选择,不同的损失函数),简单地给出相同的内容和样式权重不是最佳解决方案。 因此,在我们的实验中,我们尽力平衡不同算法之间的内容和样式权重。
3)我们尝试使用作者建议的默认参数(例如,图层的选择,学习率等),除了上述内容和样式权重。 虽然通过更仔细的超参数调整可以进一步改进某些算法的结果,但我们选择作者的默认参数,因为我们认为超参数的灵敏度也是一个重要的隐式比较标准。 例如,如果算法需要大量工作来调整每个样式的参数,我们就不能说算法是有效的。
还有一些其他实现细节需要注意。 对于[47]和[48],我们使用[50]中提出的实例归一化策略,这在发表的论文中没有涉及。 此外,我们不考虑所有算法的分集损失项(在[50],[55]中提出),即,一对内容和样式图像对应于我们实验中的一个程式化结果。 对于Chen和Schmidt的算法[57],我们使用前馈重建来重建程式化结果。
6.2 Qualitative Evaluation
示例程式化结果显示在图5,图7和图9中。可以在补充材料3中找到更多结果
1)IOB-NST的结果。 在内容和样式图像之后,图5包含了基于在线图像优化的Gatys等人的IOBNST算法的结果[4]。 样式转移过程在计算上很昂贵,但相比之下,结果在视觉质量上很有吸引力。 因此,Gatys等人的算法。 通常被认为是NST社区的黄金标准方法。
2)PSPM-MOB-NST的结果。 图5显示了每个模型的每个模型MOB-NST算法的结果(第4.2节)。 每个型号只有一种款式。 可以注意到Ulyanov等人的程式化结果。 [48]和约翰逊等人。 [47]有些相似。 这并不奇怪,因为他们有着相似的想法,只是在他们详细的网络架构上有所不同。 对于Li和Wand [52]的结果,结果不那么令人印象深刻。 由于[52]基于生成对抗网络(GAN),在某种程度上,培训过程并不稳定。 但我们认为基于GAN的风格转移是一个非常有前景的方向,并且在NST领域已经有一些其他基于GAN的作品[83],[87],[98](第5节)。
3)MSPM-MOB-NST的结果。图7展示了多模式每模型MOB-NST算法的结果。 多种样式合并到一个模型中。 Dumoulin等人的算法[53]和Chen等人的算法[54]的想法是将少量参数与每种风格联系起来。同时,他们都在[[]的架构上构建算法。47。 因此,它们的结果在视觉上相似并不奇怪。 虽然[53],[54]的结果很吸引人,但随着学习风格数量的增加,它们的模型尺寸会变大。 相比之下,Zhang和Dana的算法[56]和Li等人的算法[55]使用单一网络,具有相同的可训练网络权重,用于多种样式。模型大小问题得到解决,但似乎存在一些干扰 不同的款式,略微影响了款式的质量。
4)ASPM-MOB-NST的结果。 图9显示了最后一类MOB-NST算法,即ArbitraryStyle-Per-Model MOB-NST算法。 他们的想法是一个模型。 在全球范围内,ASPM的结果比其他类型的算法稍微不那么令人印象深刻。这是可以接受的,因为在研究中,速度,灵活性和质量之间的三方面权衡是常见的。 Chen和Schmidt基于补丁的算法[57]似乎没有将足够的样式元素组合到内容图像中。 他们的算法基于类似的补丁交换。 当许多内容补丁与不包含足够样式元素的样式补丁交换时,目标样式将无法很好地反映出来。Ghiasi等人的算法[58]是数据驱动的,其样式化质量非常依赖于各种训练方式。 对于Huang和Belongie [51]的算法,他们建议匹配全局概要特征统计,并与[57]相比成功地提高视觉质量。 然而,他们的算法似乎不善于处理复杂的风格模式,他们的风格化质量仍然与各种训练风格有关。 Li等人的算法。 [59]用一系列转换取代了训练过程。但[59]并不能有效地产生尖锐的细节和细节。
显着性比较。 NST是一个艺术创作过程。如[3],[38],[39]所述,风格的定义是主观的,也是非常复杂的,涉及个人偏好,纹理成分以及使用的工具和媒介。因此,它很难定义风格化艺术品的审美标准。对于相同的程式化结果,不同的人可能具有不同甚至相反的视图。尽管如此,我们的目标是尽可能客观地比较不同NST技术的结果(如图5,图7和图9所示)。在这里,我们考虑比较显着性图,如[63]中提出的。相应的结果显示在图6,图8和图10中。显着性图可以显示图像中的视觉主导位置。直观地说,成功的样式转移可能削弱或增强内容图像中的显着性图,但不应改变完整性和连贯性。从图6(IOB-NST和PSPM-MOB-NST的显着性检测结果)可以看出,[4],[47],[48]的程式化结果很好地保留了内容图像的结构;然而,对于[52],观察者在风格化之后识别对象可能更难。使用类似的分析方法,从图8(MSPM-MOB-NST的显着性检测结果),[53]和[54]保留了原始内容图像的类似显着性,因为它们都将少量参数与每种样式联系起来。 [56]和[55]在保留原始显着性图的完整性方面也是类似的,因为它们都使用单个网络用于所有样式。 如图10所示,对于ASPMMOB-NST的显着性检测结果,[58]和[51]的表现优于[57]和[59]; 然而,[58]和[51]都是数据驱动的方法,其质量取决于培训方式的多样性。 一般来说,似乎MSPM-MOB-NST的结果比ASPM-MOB-NST保持更好的显着一致性,但略逊于IOB-NST和PSPM-MOB-NST。
6.3 Quantitative Evaluation
关于定量评估,我们主要关注五个评估指标,即:为不同大小的单个内容图像生成时间; 单个模型的培训时间; 内容图像的平均损失,以衡量损失函数的最小化程度; 训练期间的损失变化以测量模型收敛的速度; 样式可伸缩性来衡量学习样式集的大小。
1)程式化速度。 效率问题是MOB-NST算法的重点。 在本小节中,我们根据样式化速度定量地比较不同的算法。 表2演示了使用不同算法对具有三种分辨率的一个图像进行样式化的平均时间。 在我们的实验中,样式图像具有与内容图像相同的大小。 表2中的第五列表示每种算法的一个模型可以产生的样式数。k(k∈Z+)表示单个模型可以产生多个样式,这对应于MSPM算法。 ∞表示单个模型适用于任何样式,对应于ASPM算法。 表2中报告的数字是通过平均100个图像的生成时间获得的。 请注意,我们不包括表2中[53],[58]的速度,因为他们的算法是基于Johnson等人的算法来缩放和移动参数。[47]。使用[32],[53]对一个图像进行样式化所需的时间在相同设置下非常接近[47]。 对于陈等人在[54]中的算法,由于他们的算法受专利保护,他们没有公开详细的架构设计,这里我们只附上作者提供的速度信息以供参考:Ona Pascal TitanXGPU,256×256:0.007s;512×512:0.024s; 1024×1024:0.089s。 对于Chen和Schmidt的算法[57],由于视频内存的限制,没有报告处理1024×1024图像的时间。两个1024×1024图像的交换补丁需要超过24 GB的视频内存,因此,样式化过程不实用。 我们可以观察到除了[57],[59]之外,所有其他MOBNST算法都能够实时地对高分辨率内容图像进行样式化。 ASPM算法通常比PSPM和MSPM慢,这再次证明了前面提到的三向权衡。
2)训练时间。另一个问题是单个模型的训练时间。 不同算法的训练时间很难比较,因为有时仅用几次迭代训练的模型能够产生足够的视觉吸引力的结果。 因此,我们只是概述了不同算法(在相同设置下)的训练时间,作为后续研究的参考。在NVIDIA Quadro M6000上,对于Johnson等人的算法,单个模型的训练时间约为3.5小时。 [47],Ulyanov等人的算法需要3个小时。 [48],Li和Wand [52]算法需要2小时,Zhang和Dana算法需要4小时[56],Li等人需要8小时。[55]。 Chen和Schmidt的算法[57]以及Huang和Belongie的算法[51]需要更长的时间(例如,几天),这是可以接受的,因为预训练的模型可以适用于任何风格。 [58]的训练时间取决于训练方式的大小。 对于MSPM算法,可以通过预训练模型的增量学习进一步减少训练时间。 例如,Chen等人的算法。 只需要8分钟就可以逐步学习新风格,如[54]中所述。
3)损失比较。 评估共享相同损失函数的一些MOBNST算法的一种方法是比较它们在训练期间的损失变化,即训练曲线比较。 它可以帮助研究人员通过测量模型收敛的速度以及最小化相同损耗函数的程度来证明建筑设计的选择。 在这里,我们比较了图11中两种流行的MOB-NST算法[47],[48]的训练曲线,因为大多数后续工作都是基于它们的架构设计。我们删除了总变异项,并为两种算法保持相同的目标。 其他设置(例如,丢失网络,所选择的层)也保持相同。 对于样式图像,我们从样式集中随机选择四种样式,并在图11中以不同颜色表示它们。可以观察到两种算法在收敛速度方面相似。 此外,两种算法在训练期间都很好地最小化了内容丢失,并且它们主要在于学习风格目标的速度不同。 [47]中的算法可以更好地减少样式损失。
另一个相关标准是比较一组测试图像上不同算法的最终损失值。 该度量标准演示了使用不同算法可以最小化相同损失函数的程度。 为了公平比较,损失函数和其他设置也需要保持不变。 我们在图12中显示了一个IOB-NST算法[4]和两个MOB-NST算法[47],[48]的结果。结果与上述速度和质量之间的权衡相一致。 尽管MOB-NST算法能够实时地对图像进行样式化,但就最小化相同的损失函数而言,它们并不像IOB-NST算法那样好。
4)样式可扩展性。 可伸缩性是MSPM算法的一个非常重要的标准。 但是,由于单个模型的最大功能与特定样式集高度相关,因此很难测量。 如果大多数样式具有某些相似的模式,则单个模型可以生成数千种样式甚至更多样式,因为这些相似样式的样式特征统计分布有些相似。 相反,如果风格模式在不同风格图像之间变化很大,则单个模型的能力将小得多。 但很难衡量这些风格在风格模式上的差异程度。 因此,为了向读者提供参考,这里我们只是总结了作者对样式可扩展性的尝试:[53]的数量为32,[54]和[55]的数量为1000,[56]的数量为100。
在该实验部分中提到的算法的优点和缺点的总结可以在表3中找到。
7 APPLICATIONS
由于视觉上看似合理的风格化结果,NST的研究已经导致许多成功的工业应用并开始提供商业利益。 在本节中,我们总结了这些应用程序并提供了一些潜在的用法。
7.1 Social Communication
NST在学术界和工业界引起注意的一个原因是它在一些社交网站(例如Facebook和Twitter)中的受欢迎程度。最近出现的名为Prisma的移动应用程序[11]是提供NST算法作为服务的第一个工业应用程序之一。由于其高风格质量,Prisma取得了巨大成功,并在全球范围内广受欢迎。提供相同服务的一些其他应用程序一个接一个地出现并开始提供商业利益,例如,Web应用程序Ostagram [12]要求用户支付更快的样式化速度。在这些工业应用[13],[99],[100]的帮助下,人们可以创建自己的艺术画作,并在Twitter和Facebook上与他人分享他们的作品,这是一种新的社交方式。还有一些相关的应用论文:[101]介绍了一个iOS应用程序Pictory,它结合了风格转移技术和图像过滤; [102]进一步介绍了Pictory的技术实施细节; [103]演示了另一个基于GPU的移动应用程序ProsumerFX的设计。
NST在社交沟通中的应用加强了人与人之间的联系,也对学术界和工业界产生了积极影响。 对于学术界来说,当人们分享他们自己的杰作时,他们的评论可以帮助研究人员进一步改进算法。 此外,NST在社交传播中的应用也推动了其他新技术的进步。 例如,受到NST对视频的实时要求的启发,Facebook AI Research(FAIR)首先开发了一种新的移动嵌入式深度学习系统Caffe2Go,然后是Caffe2(现在与PyTorch合并),可以在手机上运行深度神经网络[104]。 对于工业而言,该应用带来了商业利益并促进了经济发展。
7.2 User-assisted Creation Tools
NST的另一个用途是使其充当用户辅助的创建工具。 虽然没有流行的应用程序将NST技术应用于创建工具,但我们相信它将来会成为一种很有前途的潜在用途。
作为画家和设计师的创作工具,NST可以让画家更方便地创作出特定风格的艺术作品,特别是在创作计算机制作的艺术品时。 此外,使用NST算法,为时装设计师制作风格化的时尚元素和为各种风格的建筑师制作风格化的CAD图纸是微不足道的,这在手工创建时会很昂贵。
7.3 Production Tools for Entertainment Applications
一些娱乐应用程序,如电影,动画和游戏可能是NST的最多应用形式。 例如,创建动画通常需要每秒8到24个彩绘帧。 如果NST可以应用于将真人视频自动设计为动画风格,则生产成本将大大降低。 同样,当应用于创建一些电影和电脑游戏时,NST可以显着节省时间和成本。已经有一些申请文件旨在介绍如何将NST用于生产,例如Joshi等。 探索使用NST重绘一部名为Come Swim [105]的电影中的一些场景,这表明NST在这个领域有潜在的应用前景。 在[106],Fiser等人。 研究用于3D渲染风格化的照明引导式传输算法。 他们演示了如何利用他们的算法在不使用参考3D模型的情况下渲染各种几何体的预览,自动完成着色和传输样式。
8 FUTURE CHALLENGES
NST领域的进步令人鼓舞,一些算法已经在工业应用中得到应用。 尽管当前的算法具有良好的性能,但仍然存在一些挑战和开放性问题。 在本节中,我们总结了NST这一领域的主要挑战,并讨论了在未来工作中如何处理这些挑战的可能策略。 由于NST与NPR密切相关,NPR中的一些关键问题(在[3],[14],[107],[108],[109],[110]中总结)也是NST研究的未来挑战。 因此,我们首先回顾了NPR和NST中存在的一些主要挑战,然后讨论了专门针对NST领域的研究问题。
8.1 Evaluation Methodology
审美评估是NPR和NST的关键问题。 在NPR领域,许多研究人员解释了审美评价的必要性[3],[14],[107],[108],[109],[110],例如,[3],Rosin和Collomosse 用两章来探讨这个问题。 随着NPR和NST领域的成熟,这个问题越来越重要。 正如[3]中所指出的,研究人员需要一些可靠的标准来评估他们提出的方法相对于现有技术的好处,并且还需要一种评估一种特定方法对一种特定方案的适用性的方法。然而,大多数NPR和NST论文通过并排主观视觉比较或通过各种用户研究得出的测量来评估他们提出的方法[59],[111],[112]。 例如,为了评估所提出的通用样式转移算法,Li等人。 [59]进行用户研究,要求参与者投票选出他们最喜欢的程式化结果。 我们认为它不是最佳解决方案,因为不同观察者的结果差异很大。 受[113]的启发,我们使用不同NST算法的程式化结果进行了一个简单的用户研究实验。在我们的实验中,每个风格化的图像由8个不同的评估者(4名男性和4名女性)评定,具有相同的职业和年龄。如图13所示,给定相同的程式化结果,具有相同职业和年龄的不同观察者仍然有很大不同收视率。 然而,目前还没有用于评估NPR和NST算法的黄金标准评估方法。 审美评估的挑战将继续成为NPR和NST社区的一个悬而未决的问题,其解决方案可能需要与专业艺术家合作以及确定潜在美学原则的努力。
在NST的领域,还有另一个与审美评价有关的重要问题。目前,没有用于评估NST算法的标准基准图像集。不同的作者通常使用自己的图像进行评估。在我们的实验中,我们使用精心挑选的NPR基准图像集NPR general [92],[93]作为我们的内容图像来比较不同的技术,这是由[92],[93]中的综合研究支持;但是,我们必须承认,我们的风格图像的选择远非标准的NST基准样式集。与NPR不同,NST算法对样式图像的类型没有明确的限制。因此,为了比较不同NST方法的风格可扩展性,寻找基准风格集合是至关重要的,这些风格集合共同展示了广泛的可能属性,同时详细描述了所采用的原理,图像特征的数值测量以及讨论与[92],[93],[95]中的作品有关。基于上述讨论,寻求NST基准图像集是一个独立而重要的研究方向,它不仅为研究人员提供了一种方法来证明他们提出的方法相对于现有技术的改进,而且还提供了一种测量适用性的工具。 一个特定的NST算法对一个特定要求的影响。 此外,随着几个NST扩展(第5节)的出现,研究专业基准数据集以及评估这些扩展工作的相应评估标准(例如,视频风格转移,音频风格转移,立体视觉)仍然是另一个开放性问题。 风格转移,个性风格转移和时尚风格转移)。
8.2 Interpretable Neural Style Transfer
另一个具有挑战性的问题是NST算法的可解释性。 像许多其他基于CNN的视觉任务一样,NST的过程就像一个黑盒子,这让它变得无法控制。 在这一部分,我们关注与NST可解释性相关的三个关键问题,即通过解缠结表示的可解释和可控制的NST,与NST相关的标准化方法,以及NST中的对抗性示例。代表解开。表征解开的目标是学习维度可解释的表示,其中一个或多个特定维度的某些变化对应于单个变异因子中的精确变化,而对其他因素不变[114],[115],[116] ,[117]。这种表示对于各种机器学习任务是有用的,例如,视觉概念学习[118]和转移学习[119]。例如,在风格转移中,如果可以学习其中变化因素(例如,颜色,形状,笔划大小,笔划方向和笔画组成)被精确地解开的表示,则可以在风格化期间自由地控制这些因素。例如通过简单地改变学习的解缠结表示中的相应维度,可以改变风格化图像中的笔画方向。为了解开表示的目标,当前的方法分为两类,即监督方法和无监督方法。监督解开方法的基本思想是利用注释数据来监督输入和属性之间的映射[120],[121]。尽管它们有效,但是有监督的解开方法通常需要大量的训练样本。 然而,在NST的情况下,模拟和捕获一些上述变化因素是相当复杂的。 例如,很难收集具有不同笔划方向但具有完全相同的颜色分布,笔划大小和笔划组成的一组图像。 相比之下,无监督解开方法不需要注释; 然而,它们通常会产生解析的表示,这些表示是维度不可控且无法解释的[122],即我们无法控制在每个特定维度中编码的内容。 基于上述讨论,为了获得NST中的解开的表示,要解决的第一个问题是如何定义,建模和捕获NST中复杂的变化因素。
规范化方法。 NST领域的进步与新型标准化方法的出现密切相关,如表4所示。这些标准化方法中的一些还会影响超出风格转移的更大视觉社区(例如,图像重新着色[123]和 视频颜色传播[124])。 在这一部分中,我们首先简要回顾一下NST中的这些规范化方法,然后讨论相应的问题。 NST中首先出现的归一化方法是由Ulyanov等人提出的实例归一化(或对等正规化)。[50]。 当批量大小为1时,实例规范化等同于批量规范化。 结果表明,与具有批量标准化层的网络相比,具有实例标准化层的样式转移网络收敛速度更快,并且产生视觉上更好的结果。Ulyanovetal。认为实例规范化的优越性能源于实例规范化使网络能够丢弃内容图像中的对比度信息,从而使学习更简单。 Huang和Belongie [51]提出的另一种解释是实例归一化通过归一化特征统计(即均值和方差)来执行一种样式归一化。 通过实例规范化,可以将每个单独图像的样式直接标准化为目标样式。 因此,网络的其余部分只需要处理内容丢失,使目标更容易学习。 基于实例规范化,Dumoulin等人。 [53]进一步提出条件实例归一化,其是在实例归一化层中缩放和移位参数(如等式(8)所示)。根据Huang和Belongie提出的解释,通过使用不同的参数,可以将特征统计量归一化为不同的值。 相应地,每个样本的样式可以归一化为不同的样式。 此外,在[51]中,Huang和Belongie提出了自适应实例归一化,以通过样式特征统计自适应地实例化内容特征(如等式(9)所示)。 通过这种方式,他们相信单个图像的样式可以归一化为任意样式。 尽管通过实例规范化,条件实例规范化和自适应实例规范化实现了卓越的性能,但其成功背后的原因仍然不清楚。虽然Ulyanov等人。 [50] Huang和Belongie [51]分别基于像素空间和特征空间提出了他们自己的假设,他们提出的理论缺乏理论证据。 此外,他们提出的理论也建立在其他假设之上,例如,Huang和Belongie基于Li等人的观察提出了他们的解释。 [42]:渠道特征统计,即均值和方差,可以代表风格。 然而,仍然不确定为什么特征统计可以表示样式,或者甚至特征统计是否可以表示所有样式,这与样式表示的可解释性有关。
对抗性的例子。一些研究表明,深层分类网络很容易被对抗性的例子[125],[126]所愚弄,这些例子是通过对输入图像应用扰动而产生的(例如,图14(c))。之前关于对抗性实例的研究主要集中在深层分类网络上。然而,如图14所示,我们发现在生成风格转移网络中也存在对抗性的例子。在图14(d)中,人们很难识别出最初包含在图14(c)中的内容。它揭示了生成网络和人类视觉系统之间的差异。扰动的图像仍然可以被人识别,但导致生成风格转移网络的不同结果。然而,仍然不清楚为什么一些扰动可以产生这样的差异,以及用户上传的一些类似的噪声图像是否仍然可以最佳化为所需的样式。解释和理解NST中的对抗性示例可以帮助避免样式化中的一些失败案例。
8.3 Three-way Trade-off in Neural Style Transfer
在NST的领域,速度,灵活性和质量之间存在三方面的权衡。 IOB-NST在质量方面实现了卓越的性能,但计算成本很高。 PSPM-MOB-NST实现了实时样式化; 但是,PSPM-MOB-NST需要为每种风格训练一个单独的网络,这是不灵活的。 MSPM-MOB-NST通过将多种样式合并到一个单一模型中来提高灵活性,但仍需要针对一组目标样式预先训练网络。 尽管ASPM-MOB-NST算法成功地传输了任意样式,但它们在感知质量和速度方面并不令人满意。 数据驱动ASPM的质量完全依赖于培训方式的多样性。 然而,由于艺术品的多样性,很难涵盖每种风格。 基于图像变换的ASPM算法以无学习的方式传递任意样式,但速度落后于其他样式。另一个相关问题是超参数调整的问题。 为了产生最具视觉吸引力的结果,仍然不确定如何设置内容和样式权重的值,如何选择用于计算内容和样式丢失的层,使用哪个优化器以及如何设置学习率的值。 目前,研究人员根据经验设置这些超参数;但是,一组超参数不一定适用于任何样式,并且为内容和样式图像的每个组合手动调整这些参数是繁琐的。 解决此问题的关键之一是更好地理解NST中的优化过程。 深入了解优化程序将有助于了解如何找到导致高质量的局部最小值。
9 DISCUSSIONS AND CONCLUSIONS
在过去几年中,NST一直是一个鼓舞人心的研究领域,受到科学挑战和工业需求的推动。 在NST领域进行了大量的研究。 图2总结了该领域的主要进展。表5中列出了相应的样式转移损失函数的摘要.NST是一个相当快节奏的领域,我们正在寻找更多令人兴奋的工作,致力于推动开发 这个领域。
在准备本次审查期间,我们也很高兴发现有关NST的相关研究也为其他领域[127],[128],[129],[130],[131]带来了新的启示,并加速了NST的发展。 更广阔的视觉社区。 对于图像重建领域,受到NST,Ulyanov等人的启发。 [127]提出了一种新的深度图像先验,用随机初始化的深度神经网络取代了[33]中手动设计的总变差规则器。 给定任务相关的损失函数L,图像Io和固定的均匀噪声z作为输入,它们的算法可以表示为:
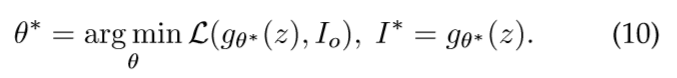
人们可以很容易地注意到等式(10)与等式(7)非常相似。 [127]中的过程与MOB-NST的训练过程相当,当训练集中只有一个可用图像时,但用Z替换Ic,用L替换Ltotal。换句话说,[127]中的g被训练为 超过一个样本。 灵感来自NST,Upchurch等。 [128]提出了一种深度特征插值技术,并为图像变换领域提供了新的基线(例如,面部老化和微笑)。 根据IOB-NST算法[4]的过程,他们添加了一个额外的步骤,该步骤在VGG特征空间中进行插值。通过这种方式,他们的算法以无学习的方式成功地改变了图像内容。 与NST密切相关的另一个领域是Face Photo-sketch Synthesis。 例如,[132]利用样式转换为最终面部草图生成阴影和纹理。 同样,对于Face Swapping领域,MOB-NST算法[48]的思想可以直接应用于构建前馈Face-Swap算法[133]。 NST还提供了一种新的域适应方式,正如Atapour-Abarghouei和Breckon [131]的工作所证实的那样。他们应用样式转换技术来翻译来自不同领域的图像,以提高其单目深度估计模型的泛化能力。
尽管近年来取得了很大进展,但NST领域还远未成熟。 目前,NST的第一阶段是重新定义和优化最近的NST算法,旨在完美地模仿各种风格。 这个阶段涉及两个技术方向。 第一个是减少故障情况并提高各种风格和内容图像的风格化质量。 虽然没有对样式类型的明确限制,但是NST确实具有它特别擅长的样式以及它所弱的某些样式。例如,NST通常在生成不规则样式元素(例如,绘画)方面表现良好, 正如许多NST论文[4],[47],[53],[59]所证明的那样; 然而,对于具有常规元素的一些样式,例如低多样式[134],[135]和像素化器样式[136],由于基于CNN的图像重建的特性,NST通常产生失真和不规则的结果。
对于内容图像,以前的NST论文通常使用自然图像作为内容来演示他们提出的算法;然而,给定抽象图像(例如,草图和漫画)作为输入内容,NST通常不组合足够的样式元素以匹配内容[137],因为预训练的分类网络不能从这些抽象图像中提取适当的图像内容。第一阶段的另一个技术方向在于从一般的NST算法中获得更多的扩展。例如,随着3D视觉技术的出现,有望研究3D表面样式化,即直接优化和生成用于照片级真实感和非真实感风格化的3D对象。在超越第一阶段之后,NST的另一个趋势是不仅用NST技术模仿人类创造的艺术,而是在潜在的美学原则的指导下创造一种新形式的AI创作艺术。朝着这个方向迈出了第一步,即使用当前的NST方法[53],[54],[62]来组合不同的风格。例如,在[62]中,Wang等人。成功地利用他们提出的算法来产生一种新风格,它将一种风格的粗糙纹理扭曲与另一种风格图像的精细笔触相融合。