在多变量的线性回归中主要讨论一下三个问题:
-
特征缩放
-
学习率α的选择策略
-
标准方程法
特征缩放
在Andrew Ng的机器学习里面,讲到使用梯度下降的时候应当进行特征缩放(Feature Scaling)。进行缩放后,多维特征将具有相近的尺度,这将帮助梯度下降算法更快地收敛。
特征缩放的一些方法:
调节比例(Rescaling)
这种方法是将数据的特征缩放到[0,1]或[-1,1]之间。缩放到什么范围取决于数据的性质。对于这种方法的公式如下:
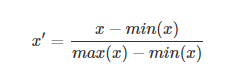
xx是最初的特征值,x'x′是缩放后的值。
平均值规范化(Mean normalisation)
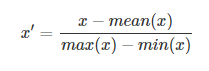
标准化(Standardization)
特征标准化使每个特征的值有零均值(zero-mean)和单位方差(unit-variance)。这个方法在机器学习地算法中被广泛地使用。例如:SVM,逻辑回归和神经网络。这个方法的公式如下:
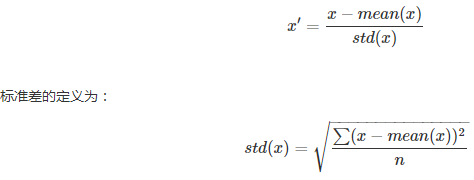
缩放到单位长度(Scaling to unit length)
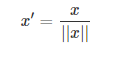
就是除以向量的欧拉长度( the Euclidean length of the vector),二维范数。
学习率α的选择策略
如果学习速率太小,则会使收敛过慢,如果学习速率太大,那么训练可能不会收敛甚至是扩散的,权重的变化会非常大,以至于会越过局部最优解,使损失变得更严重。
在实践中,怎么粗略地确定一个比较好的学习速率呢?只能通过尝试。我们可以先把学习速率设置为0.01,然后观察training cost的走向,如果cost在减小,那就可以逐步地调大学习速率,试试0.1,1.0….如果cost在增大,那就得减小学习速率,试试0.001,0.0001….经过一番尝试之后,就可以大概确定学习速率的合适的值。
标准方程法
正规方程是通过求解下面的方程来找出使得代价函数最小的参数的:假设我们的训练集特征矩阵为 X(包含了 x0=1)并且我们的训练集结果为向量y,则利用正规方程解出向量。上标T代表矩阵转置,上标-1代表矩阵的逆。

针对梯度下降与正规方程的比较,结果如下:
