在目标检测领域方向的相关经典文献包括Fast-RCNN、Faster-RCNN、SSD、YOLO以及RetinaNet等。话说“工欲善其事必先利其器”,而该 Object Detection API就是谷歌的牛逼工程师们开源给我们的最好“利器”。
今天我们将借助该API训练自己的数据集进行目标检测,这里选择的目标为扑克牌,收集了9,10,J,Q,K,A六类扑克。
1、下载TensorFlow Object Detection API
在github上该API存放在tensorflow/models项目下,下载地址为https://github.com/tensorflow/models
1.1安装protoc
在object_detection/protos中,可以看到一些proto文件,需要使用protoc程序将这些proto文件编译为python文件。下载地址为https://github.com/google/protobuf/releases解压后将bin文件夹中的protoc.exe放到C:\Windows下。(用于将protoc.exe所在的目录配置到环境变量当中)。
1.2编译proto文件
在\research\目录下打开命令行窗口输入以下代码(我是在anaconda prompt中输入)
protoc object_detection/protos/*.proto --python_out=.
如果在protos文件夹下各proto文件没有生成对应的py文件,就将*.proto换成文件夹下具体的文件名,一个一个运行,每运行一个,对应会生成一个py文件,亲测有效。
1.3将slim加入系统环境变量
将/research/slim添加到系统环境变量,在后面训练时好像还是会跳出ImportError: No module named nets错误,后来百度了许多发现原来这种方法只适用于Linux系统,可参考这篇博客https://blog.csdn.net/lgczym/article/details/79272579
对于Windows系统,首先打开命令行窗口将目录跳转到slim文件夹下,依次运行下面两行代码
python setup.py build
python setup.py install
运行后如果出现error: could not create 'build':(当文件已存在时,无法创建该文件)
原因是github下载下来的代码库中有个BUILD文件,而build和install指令需要新建build文件夹,这是名字冲突导致的问题。暂时不清楚BUILD文件的作用,将该文件移动到其他目录或删除掉,再运行上述指令,即可成功安装。
1.4安装完成测试
在检测API是否安装正常时,进入目录\research下运行(如果出现下面结果,说明已经安装成功)
run object_detection/builders/model_builder_test.py
>>....................
----------------------------------------------------------------------
Ran 22 tests in 0.462s
OK (skipped=1)
2、训练自己的数据集
2.1利用标准工具进行标注
这里我们利用的标注工具是LabelImg (https://tzutalin.github.io/labelImg/),我下载的是windows_v1.2这个版本。需要注意一点的是,该工具的路径中不能出现顿号和中文等字体。
标注前,先将data文件夹下的predefined_classes.txt文件进行修该,对应改成你训练目标类别的名称,如下:

运行labelImg.exe进行标注如下:

标注以后,每个图片都会在当前目录下产生成一个对应的.xml文件,如下图所示:

对于样本的采集大家可以按照自己的喜好从网上下载或者从公开数据集中选取部分进行实验,初次接触该API的话建议选取少量的类别。为了节省时间我是直接从一个作者的Github里面克隆的 (https://github.com/EdjeElectronics/TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10#1-install-tensorflow-gpu-15-skip-this-step-if-tensorflow-gpu-15-is-already-installed)该作者选取的也是扑克牌样本共6个类别,他将其分别命名为(nine ten jack queen king ace),都已经标注好了,我这里直接拿来用。
在object_detection文件夹下新建playing_card文件夹,将作者的images文件夹(图片及其标注文件)拷贝到playing_card文件夹下,再新建一个train_dir文件夹用于保存训练的数据和日志,新建一个pretrained文件夹,将下载的预训练模型解压后的文件复制到其中。
2.2将xml文件转换成csv文件
在object_detection文件夹下运行xml_to_csv.py函数,将在images文件夹下产生两个csv文件,分别为train_labels.csv和test_label.csv。
2.3将csv文件转换成TFRecord文件
继续在该文件夹下运行
run generate_tfrecord.py --csv_input=playing_card/images/train_labels.csv --image_dir=playing_card/images/train --output_path=playing_card/train.recordrun generate_tfrecord.py --csv_input=playing_card/images/test_labels.csv --image_dir=playing_card/images/test --output_path=playing_card/test.record2.4下载预训练模型
Object Detection API为我们提供了很多的预训练模型,大家可以在下面网址中进行下载:
我这里选择的是faster_rcnn_inception_resnet_v2模型,将模型解压后的文件都复制到pretrained文件夹下。
然后建立标签索引pbtxt文件,从object_detection/data文件夹下,随便拷贝一个pbtxt文件到playing_card文件夹下,进行修改,并重命名为label_map.pbtxt,具体信息如下:(根据自己实际情况修改)
item {
id: 1
name: 'nine'
}
item {
id: 2
name: 'ten'
}
item {
id: 3
name: 'jack'
}
item {
id: 4
name: 'queen'
}
item {
id: 5
name: 'king'
}
item {
id: 6
name: 'ace'
}
再将上述模型对应的配置文件pipeline.config拷贝到playing_card文件夹下,名称改为faster_rcnn_inception_resnet_v2_atrous_pets.config,对其进行如下修改:
- 第一处为num_classes,需要将它修改为你训练集中物体类别数,即6;
- 第二处为eval_config中的num_examples,它表示拿来验证的图片数量(这里我们没有创建验证集,直接用测试集进行代替);
- 还有5处为所有含PATH_TO_BE_CONFIGURED的地方需要修改为自己的目录:
gradient_clipping_by_norm: 10.0
fine_tune_checkpoint: "voc/pretrained/model.ckpt"#第一处目录修改
from_detection_checkpoint: true
# Note: The below line limits the training process to 200K steps, which we
# empirically found to be sufficient enough to train the pets dataset. This
# effectively bypasses the learning rate schedule (the learning rate will
# never decay). Remove the below line to train indefinitely.
num_steps: 200000
data_augmentation_options {
random_horizontal_flip {
}
}
}
train_input_reader: {
tf_record_input_reader {
input_path: "playing_card/train.record"#第二处目录修改
}
label_map_path: "playing_card/label_map.pbtxt"#第三处目录修改
}
eval_config: {
num_examples: 67#验证集图片数修改
# Note: The below line limits the evaluation process to 10 evaluations.
# Remove the below line to evaluate indefinitely.
max_evals: 10
}
eval_input_reader: {
tf_record_input_reader {
input_path: "playing_card/test.record"#第四处目录修改
}
label_map_path: "playing_card/label_map.pbtxt"#第五处目录修改
shuffle: false
num_readers: 1
}
2.5模型训练
run model_main.py --logtostderr \
--model_dir=playing_card/train_dir \
--pipeline_config_path=playing_card/faster_rcnn_inception_resnet_v2_atrous_pets.config(一个博客说最新的目标检测API在利用model_main.py进行训练时可能无法在GPU上顺利执行,因此我们采取了另外一个策略,即通过运行legacy文件夹下的train.py文件)
run legacy/train.py \
--train_dir playing_card/train_dir/ \#训练的数据和日志保存的位置
--pipeline_config_path playing_card/faster_rcnn_inception_resnet_v2_atrous_pets.config#该网络的配置文件运行后一般会遇到"error:No modul named pycocotools”这个问题,因为之前的COCOAPI没有windows版本,解决办法可参考这篇博客https://blog.csdn.net/qq_41271957/article/details/83586862
在 GIT官网上下载git https://git-scm.com/downloads/
安装,里面有些选项按照自己电脑选就可以了,比如windows,vim/notepad++等
然后再打开命令行 pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
最终pycocotools安装成功了
然后再运行上面的模型训练文件,惊喜的发现模型可以跑起来了,如下图所示:

模型训练结束后,我们进入到train_dir文件夹下可以看到有如下生成的文件:

需要注意的是,如果发生内存和显存不足报错的情况,除了使用较小模型进行训练外,还可以修改配置文件中的以下内容:
image_resizer {
keep_aspect_ratio_resizer {
min_dimension: 600
max_dimension: 1024
}
}
这个部分表示将输入图像进行等比例缩放再进行训练,缩放后的最大边长为1024,最小边长为600.可以将整两个数值改小(比如改成512和300),使用的显存就会变小。不过这样做也可能导致模型的精度下降,因此我们需要根据自己的情况选择适合的处理方法。另外由于我们在设置文件中设置的训练步数为200000步,因此整个训练可能会消耗大量时间,可以在配置文件中将num_steps改为20000步,或者不用改,等训练到一定步数时你觉得可以了就可以关闭程序终止训练,如果测试效果不好,还可以继续训练,它会接着上次训练的地方继续迭代训练。
3、导出模型并预测单张图片
如何将训练好的数据文件(train_dir文件下)导出并用于单张图片的目标检测?TensorFlow Object Detection API提供了一个export_inference_graph.py脚本用于导出训练好的模型。具体方法是在object_detection目录下执行:
run export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path playing_card/faster_rcnn_inception_resnet_v2_atrous_pets.config \
--trained_checkpoint_prefix playing_card/train_dir/model.ckpt-644 \
--output_directory playing_card/export/
其中model.ckpt-644表示使用第644步保存的模型。我们需要根据训练文件夹下checkpoint的实际步数改成对应的值。导出的模型是playing_card/export/frozen_inference_graph.pb文件。
如果出现如下错误(restart the kernel即可):

然后可以参考官方给的示例代码,自行编写利用导出模型对单张图片做目标检测的脚本。然后将PATH_TO_FROZEN_GRAPH的值赋值为playing_card/export/frozen_inference_graph.pb,即导出模型文件。将PATH_TO_LABELS修改为playing_card/label_map.pbtxt,即各个类别的名称。其它代码都可以不改变,然后测试我们的图片
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from distutils.version import StrictVersion
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
from object_detection.utils import ops as utils_ops
from utils import label_map_util
from utils import visualization_utils as vis_util
if StrictVersion(tf.__version__) < StrictVersion('1.9.0'):
raise ImportError('Please upgrade your TensorFlow installation to v1.9.* or later!')
%matplotlib inline
#frozen_inference_graph.pb文件就是后面需要导入的文件,它保存了网络的结构和数据
PATH_TO_FROZEN_GRAPH = 'playing_card/export/frozen_inference_graph.pb'
# mscoco_label_map.pbtxt文件中保存了index到类别名的映射,该文件就在object_dection/data文件夹下
PATH_TO_LABELS = os.path.join('playing_card', 'label_map.pbtxt')
#新建一个图
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
#这个函数也是一个方便使用的帮助函数,功能是将图片转换为Numpy数组的形式
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
#检测
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(9,11 ) ]
# 输出图像的大小(单位是in)
IMAGE_SIZE = (12, 8)
with tf.Session(graph=detection_graph) as sess:
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
#将图片转换为numpy格式
image_np = load_image_into_numpy_array(image)
#将图片扩展一维,最后进入神经网络的图片格式应该是[1,?,?,3],括号内参数分别为一个batch传入的数量,宽,高,通道数
image_np_expanded = np.expand_dims(image_np,axis = 0)
#获取模型中的tensor
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
#boxes变量存放了所有检测框
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
#score表示每个检测结果的confidence
scores = detection_graph.get_tensor_by_name('detection_scores:0')
#classes表示每个框对应的类别
classes = detection_graph.get_tensor_by_name('detection_classes:0')
#num_detections表示检测框的个数
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
#开始检测
boxes,scores,classes,num_detections = sess.run([boxes,scores,classes,num_detections],
feed_dict={image_tensor:image_np_expanded})
#可视化结果
#squeeze函数:从数组的形状中删除单维度条目,即把shape中为1的维度去掉
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)测试结果如下:


由于训练时间太长,我这电脑训练了一夜才训练到六百多步,所以检测效果并不好,一般至少要训练个几万步吧。
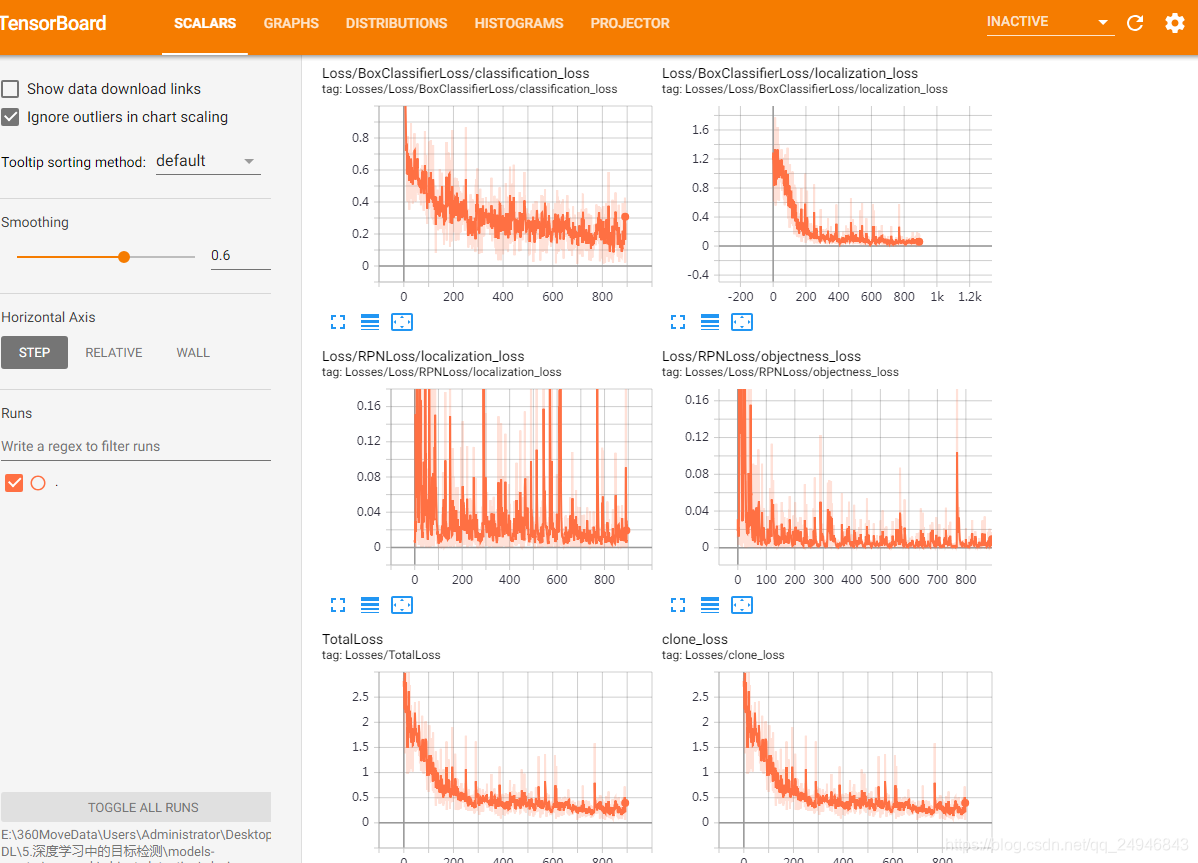
4、在Tensorboard中监控训练情况
打开anaconda prompt终端
将路径切换到训练生成的数据和日志文件下即train_dir文件夹下:

继续输入以下命令(train_dir最好也用绝对路径):

执行完该命令后会得到一个网址,在谷歌浏览器中打开(最好是谷歌,我用搜狗不行):
![]()
在谷歌浏览器中打开,张量流图如下图所示(通过鼠标滚轮可进行放大缩小和拖动):

训练时各个损失的变化情况如下图所示:
参考文献:21个项目玩转深度学习