使用Tensorflow object detection API训练自己的数据教程
1. 环境配置
-
安装Tensorflow和用来做Tensorflow object detection API的models文件夹。
安装教程参考博文:安装不同版本的tensorflow与models -
安装coco API。
安装教程参考博文:安装coco API教程 -
编译models文件
(1)在models/research/下运行: protoc object_detection/protos/*.proto --python_out=.
(2)添加Libraries到PYTHONPATH
打开~/.bashrc文件,在里面添加:
export PYTHONPATH=export PYTHONPATH="/home/rcus-cv-group/CODEs/TF/models:/home/rcus-cv-group/CODEs/TF/models/slim:$PYTHONPATH"
(3)测试安装是否成功
在models/research/下运行: python object_detection/builders/model_builder_test.py -
上述运行可能会报错,几种报错解决方案:安装tensorflow的models错误解决方案
-
进入models/research/object_detection/文件夹,文件夹内有做目标检测所需的所有文件。在该文件夹内新建一个自己工程的文件夹my_project,下面所有设计的文件都放入该文件夹内。
2. 数据准备
2.1 制作数据集
- 制作目标检测的数据集,可以使用LabelImg工具进行标注;
- 制作目标实例分割的数据集,可以使用Labelme工具进行标注。
- 制作label map文件:label_map.pbtxt,将里面的mouth和teeth换成自己数据的类别名称。
item {
id: 1
name: 'mouth'
}
item {
id: 2
name: 'teeth'
}
2.2 数据集格式转换
- 以目标检测为例,使用LabelImg生成的标签格式为xml,需要将数据集转换成tensorflow可用的record格式。
可参考博文:将xml格式数据转化为record格式的教程。 - 以实例分割数据集为例,使用Labelme生成的label格式为.json文件,需要将数据集转换成tensorflow可用的record格式。
可参考博文:将json格式数据集转化为record格式的教程。 - 转换之后将原始数据、label map、转换之后的数据都放入一个用于数据集管理的文件夹内,取名为dataset
3. 训练教程
3.1 预训练模型的下载
-
在tensorflow detection model zoo里可以下载大量在coco数据集上训练好的模型,这些模型可以作为训练自己网络的预训练模型,使用Tensfer Learning方式训练自己的数据集。
TensorFlow 1 Detection Model Zoo
TensorFlow 2 Detection Model Zoo -
在my_project下建立存放预训练模型的文件夹models,将下载好的模型存放到文件夹下。
-
在object_detection文件夹下的samples/configs里找到对应预训练模型的config文件,将其复制到my_project里。
3.2 训练网络
- 将object_detection文件夹下的legacy下的train.py和trainer.py文件复制到my_project里。
- 修改训练模型的config文件,以mask_rcnn_inception_v2_coco.config为例:
(1)第10行修改num_classes为自己数据集的类别数(不包括背景)。
(2)第105-125行,修改train_config里的batch_size、initial_learning_rate、step等参数。
(3)第127行,修改fine_tune_checkpoint的路径,制定到models里的对应预训练模型里,如:
fine_tune_checkpoint: “/home/ubuntu/Tensorflow/modelsTF1.8/research/object_detection/my_train/mouth/model/mask_rcnn_inception_v2_coco_2018_01_28/model.ckpt”
(4)第133行,修改num_steps。
(5)第140-147行,修改train_input_reader里的input_path、label_map_path。
(6)第149-154行,修改eval_config里的num_examples、max_evals。
(7)第156-165行,修改eval_input_reader里的input_path、label_map_path。 - 训练网络
在object_detection文件夹下执行:
# 调用model_main.py执行
python model_main.py --model_dir=training --pipeline_config_path=training/ssd_mobilenet_v1_coco.config --num_train_steps=60000 --num_eval_steps=20 --alsologtostderr
# 也可以使用旧版本训练
python legacy/train.py --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config --logtostderr
3.3 验证网络
- 将object_detection文件夹下的legacy下的eval.py和evaler.py文件复制到my_project里。
- 在object_detection路径下运行:
python my_project/eval.py --logtostderr --checkpoint_dir=my_project/training/ --eval_dir=my_project/eval --pipeline_config_path=my_project/mask_rcnn_inception_v2_coco.config
注意:–checkpoint_dir=my_project/training/添加的是训练生成的文件夹路径
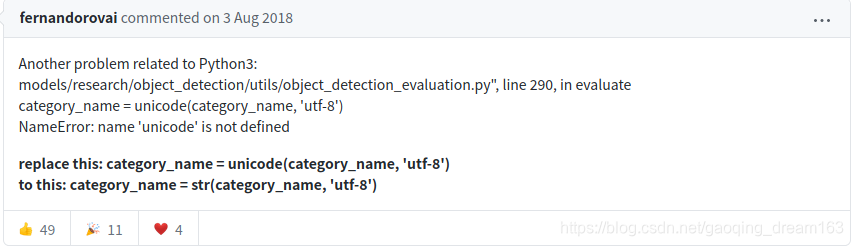
- 可能会报错:NameError: name ‘unicode’ is not defined in object_detection/utils/object_detection_evaluation.py
错误分析: 'unicode’是python2的写法,python3换成了str。
修改方式:参考
3.4 可视化
- 在 object_detection 目录执行:
tensorboard --logdir='my_project'
然后在网站上输入本地游览器网址:localhost:6006
- 显示如下
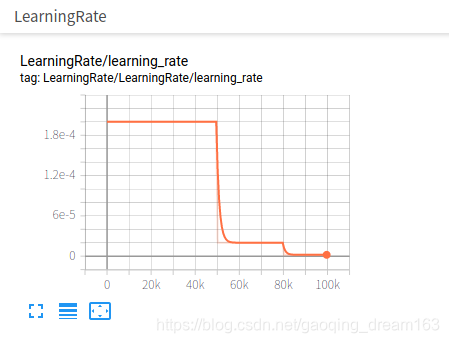
 学习率变化:
学习率变化:
误差变化:
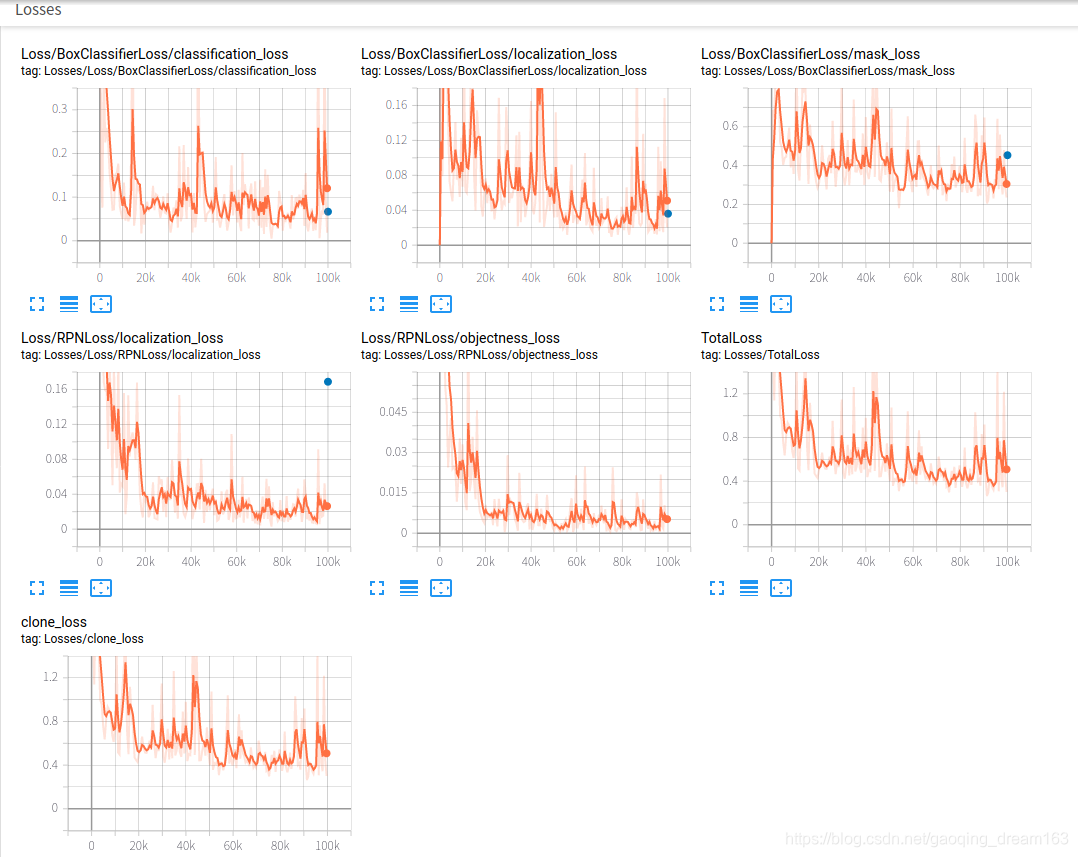 准确率mAP:
准确率mAP:

图像示例:
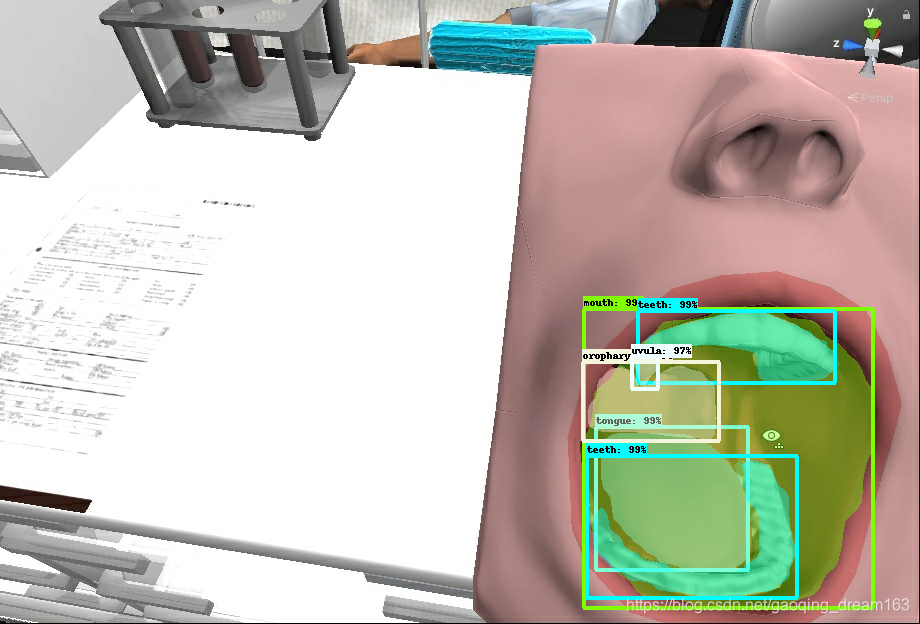
4. 测试教程
4.1 导出训练模型
- 使用API自带的export_inference_graph.py文件可以将训练好的模型导出成pb文件,方便后续调用模型。
- 在 object_detection 目录执行:
python export_inference_graph.py --input_type image_tensor --pipeline_config_path my_project/mask_rcnn_inception_v2_coco.config --trained_checkpoint_prefix my_project/training/model.ckpt-100000 --output_directory my_project/exported_model
- 会在my_project文件下建立exported_model文件夹,内部生成文件如下:
 其中frozen_inference_graph.pb文件为需要用到的导出的训练模型。
其中frozen_inference_graph.pb文件为需要用到的导出的训练模型。
4.2 通过opencv实现图像/摄像头下的目标检测
- 如果做目标检测任务,需要检测出图像中目标的bbox并显示,可以参考博客:Tensorflow调用目标检测模型并显示
- 如果做实例分割任务,需要检测出图像中目标的mask和bbox并显示,可以参考博客:
Tensorflow调用实例分割模型并显示mask