Markdown
来源:CCF
标签:
参考资料:
相似题目:
题目
Markdown 是一种很流行的轻量级标记语言(lightweight markup language),广泛用于撰写带格式的文档。例如以下这段文本就是用 Markdown 的语法写成的:
这些用 Markdown 写成的文本,尽管本身是纯文本格式,然而读者可以很容易地看出它的文档结构。同时,还有很多工具可以自动把 Markdown 文本转换成 HTML 甚至 Word、PDF 等格式,取得更好的排版效果。例如上面这段文本通过转化得到的 HTML 代码如下所示:
本题要求由你来编写一个 Markdown 的转换工具,完成 Markdown 文本到 HTML 代码的转换工作。简化起见,本题定义的 Markdown 语法规则和转换规则描述如下:
●区块:区块是文档的顶级结构。本题的 Markdown 语法有 3 种区块格式。在输入中,相邻两个区块之间用一个或多个空行分隔。输出时删除所有分隔区块的空行。
○段落:一般情况下,连续多行输入构成一个段落。段落的转换规则是在段落的第一行行首插入<p>,在最后一行行末插入</p>。
○标题:每个标题区块只有一行,由若干个#开头,接着一个或多个空格,然后是标题内容,直到行末。#的个数决定了标题的等级。转换时,# Heading转换为<h1>Heading</h1>,## Heading转换为<h2>Heading</h2>,以此类推。标题等级最深为 6。
○无序列表:无序列表由若干行组成,每行由*开头,接着一个或多个空格,然后是列表项目的文字,直到行末。转换时,在最开始插入一行<ul>,最后插入一行</ul>;对于每行,* Item转换为<li>Item</li>。本题中的无序列表只有一层,不会出现缩进的情况。
●行内:对于区块中的内容,有以下两种行内结构。
○强调:_Text_转换为<em>Text</em>。强调不会出现嵌套,每行中_的个数一定是偶数,且不会连续相邻。注意_Text_的前后不一定是空格字符。
○超级链接:[Text](Link)转换为<a href="Link">Text</a>。超级链接和强调可以相互嵌套,但每种格式不会超过一层。
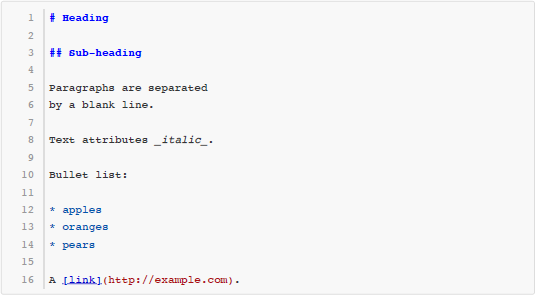
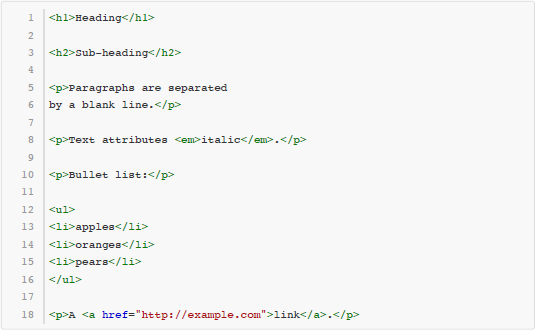
输入
输入由若干行组成,表示一个用本题规定的 Markdown 语法撰写的文档。
输出
输出由若干行组成,表示输入的 Markdown 文档转换成产生的 HTML 代码。
输入样例
# Hello
Hello, world!
输出样例
<h1>Hello</h1>
<p>Hello, world!</p>
提示
本题的测试点满足以下条件:
●本题每个测试点的输入数据所包含的行数都不超过100,每行字符的个数(包括行末换行符)都不超过100。
●除了换行符之外,所有字符都是 ASCII 码 32 至 126 的可打印字符。
●每行行首和行末都不会出现空格字符。
●输入数据除了 Markdown 语法所需,内容中不会出现#、*、_、[、]、(、)、<、>、&这些字符。
●所有测试点均符合题目所规定的 Markdown 语法,你的程序不需要考虑语法错误的情况。
每个测试点包含的语法规则如下表所示,其中“√”表示包含,“×”表示不包含。
解题思路
注意一种情况:
A [_link_](https://blog.csdn.net/wingrez)
<p>A <a href="https://blog.csdn.net/wingrez"><em>link</em></a></p>
参考代码
#include<iostream>
#include<cstdio>
#include<string>
#include<cstring>
using namespace std;
const int MAXN=10010;
char md[MAXN];
int cnt;
string html;
int deal_h(int pos);
int deal_p(int pos);
int deal_list(int pos);
int deal_empha(int pos, string &text=html);
int deal_link(int pos);
int deal_h(int p){
int sc=0; //对#计数
while(md[p+sc]=='#') sc++;
html+="<h"+string(1,'0'+sc)+">";
int i=p+sc;
while(md[i]==' ') i++;
while(md[i]!='\n'){
if(md[i]=='_') i=deal_empha(i);
else if(md[i]=='[') i=deal_link(i);
else html+=md[i];
i++;
}
html+="</h"+string(1,'0'+sc)+">\n";
return i;
}
int deal_p(int p){
html+="<p>";
int i=p;
while(true){
if(md[i]=='_') i=deal_empha(i);
else if(md[i]=='[') i=deal_link(i);
else if(md[i]=='\n' && md[i+1]=='\n') break;
else html+=md[i];
i++;
}
html+="</p>\n";
return i;
}
int deal_list(int p){
html+="<ul>\n";
int i=p;
while(md[i]=='*'){
html+="<li>";
while(md[++i]==' ');
while(md[i]!='\n'){
if(md[i]=='_') i=deal_empha(i);
else if(md[i]=='[') i=deal_link(i);
else html+=md[i];
i++;
}
html+="</li>\n";
i++;
}
html+="</ul>\n";
return i;
}
int deal_empha(int p, string &text){
int i=p+1;
text+="<em>";
while(md[i]!='_'){
if(md[i]=='[') i=deal_link(i);
else text+=md[i];
i++;
}
text+="</em>";
return i;
}
int deal_link(int p){
int i=p+1;
string text,url;
while(md[i]!=']'){
if(md[i]=='_') i=deal_empha(i, text);
else text+=md[i];
i++;
}
i+=2;
while(md[i]!=')'){
url+=md[i++];
}
html+="<a href=\""+url+"\">"+text+"</a>";
return i;
}
int main(){
char ch;
while((ch=getchar())!=EOF){
md[cnt++]=ch;
}
md[cnt++]='\n';
md[cnt]='\0';
int i=0;
while(i<cnt){
if(md[i]=='\n') i++;
else if(md[i]=='#') i=deal_h(i);
else if(md[i]=='*') i=deal_list(i);
else i=deal_p(i);
}
cout<<html;
return 0;
}