首先,集群分布条件需要三台或三台以上服务器主机,如果只有一台笔记本的话可以使用VMware Workstation安装三个虚拟主机。
一.安装JDK
1). 下载JDK

2). 解压并配置JDK环境变量
[root@localhost java]# tar -zxvf jdk-8u201-linux-x64.tar.gz
[root@localhost java]# vim /etc/profile #在其中添加以下内容:
export JAVA_HOME=/usr/java/jdk1.8.0_171
export JRE_HOME=/usr/java/jdk1.8.0_171/jre
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin保存并退出后: [root@localhost java]# sourch /etc/profile 使环境变量立即更新
二.配置SSH免密登陆
如果要实现无密登陆到其它的主机,只需将生成的 “ id_rsa.pub " 追加到其它主机的 ” ~/.ssh/authorized_keys “ 中去。这里我们使用的方法是先将本机的 ” ~/.ssh/id_rsa.pub “ 拷贝到你想无密登陆的主机上,再在相应的主机上使用 ” cat " 命令将” ~/.ssh/id_rsa.pub “ 追加到该主机的 ” ~/.ssh/authorized_keys “ 中。
1.安装ssh: [root@localhost java]# yum install ssh
2.进入.ssh文件夹: [root@localhost java]# cd ~/.ssh # 如果找不到这个文件夹,先执行一下 "ssh localhost"
3.生成密钥::[root@localhost .ssh]# ssh-keygen -t rsa #一路回车即可
4.创建存放密钥文件: [root@localhost .ssh]# touch authorized_keys
5.追加密钥到文件:[root@localhost .ssh]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[root@localhost .ssh]# ll
total 20
-rw-r--r--. 1 root root 408 Jan 29 01:41 authorized_keys
-rw-------. 1 root root 1679 Jan 29 01:38 id_rsa
-rw-r--r--. 1 root root 408 Jan 29 01:38 id_rsa.pub
三.关闭防火墙
- 目的:使外网可以访问linux端口
- 关闭防火墙命令
- [root@localhost /]# systemctl stop firewalld.service #停止firewall
- [root@localhost /]# systemctl disable firewalld.service #禁止firewall开机启动
- [root@localhost /]# reboot #重新启动
四.配置hosts列表
该项也需要在HadoopSlave节点配置。
[root@localhost /]# vi /etc/hosts #将下面三行添加到/etc/hosts文件中:
192.168.38.136 master
192.168.38.137 slave1
192.168.38.138 slave2
ping slave1 如果能ping通表示配置成功
五.hadoop分布式集群安装
- hadoop安装包下载:https://hadoop.apache.org/releases.html
- 安装前需要在/usr/hadoop下新建文件夹:tmp/hdfs/name 与 tmp/hdfs/data #后面会用到
解压安装包:[root@localhost hadoop]# tar -zxvf hadoop-2.8.5.tar.gz
六.配置hadoop环境变量(etc/hadoop)目录下,hadoop-env.sh,core-site.xml,mapred-site.xml.template,hdfs-site.xml。)
1)配置hadoop-env.sh
将hadoop-env.sh文件靠前export JAVA_HOME=${JAVA_HOME} 修改为 export JAVA_HOME=/usr/java/jdk1.8.0_201
保存并退出
2) 配置core-site.xml文件
#用下面代码替换文件中<configuration></configuration>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
3) 配置hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/hadoop/tmp/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/hadoop/tmp/hdfs/data</value>
</property>
</configuration>
4) 配置mapred-site.xml.template文件
#先将 mapred-site.xml.template文件改为 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5) 配置yarn-site.xml文件
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>6) 配置slaves文件
[root@localhost /]# vi slaves
master
slave1
slave2
7) 配置hadoop环境变量
[root@localhost /]# vi /etc/profile
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME=/usr/hadoop/hadoop-2.8.5#生效 [root@localhost /]# source /etc/profile
8) 将主节点上的文件复制到从节点上
[root@localhost /]# scp /usr/hadoop 192.168.38.137:/usr
[root@localhost /]# scp /usr/hadoop 192.168.38.138:/usr
9) 初始化HDFS(只在master上执行)
[root@localhost /]# bin/hadoop namenode -format
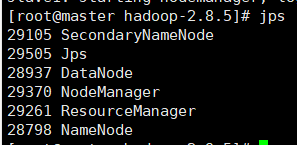
七. 启动测试
启动HDFS(只在master上执行)
进入到hadoop主安装目录后使用 sbin/start-all.sh
如果出现下图则hadoop启动成功