1.前期工作
2.时间同步
思路:让主节点连接外网的时间,从节点仅仅连接主节点的时间,达到3台机时间一样的目的
2.1 主节点时间同步
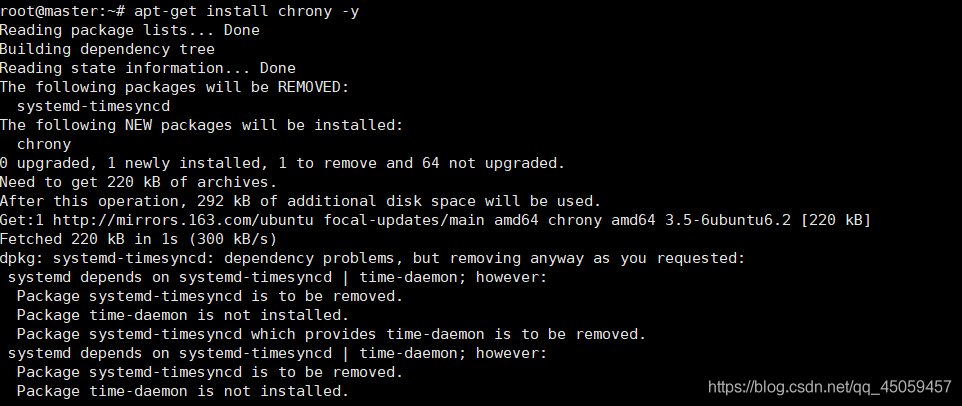
2.1.1 安装软件包
apt-get install chrony -y
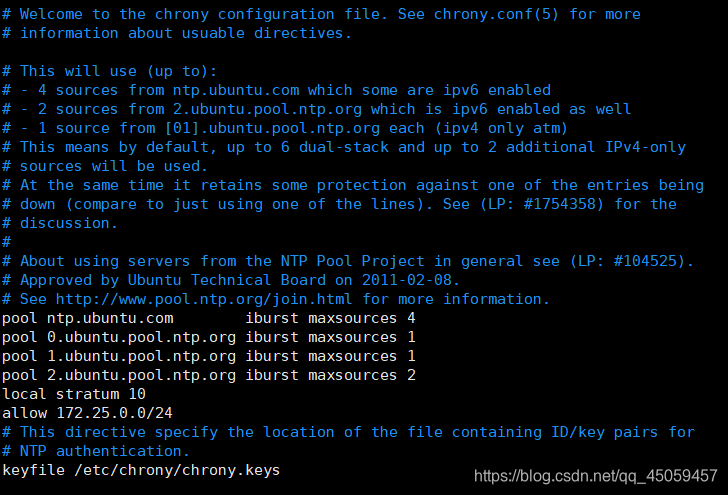
2.1.2 编辑/chrony.conf
vi /etc/chrony/chrony.conf
添加
local stratum 10
allow 172.25.0.0/24
2.1.3 激活启动NTP服务
systemctl enable chrony
systemctl restart chrony

2.2 从节点时间同步
2.2.1 安装软件包
apt-get install chrony -y
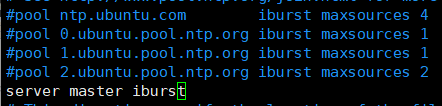
2.2.2 编辑/chrony.conf
vi /etc/chrony/chrony.conf
注释这4行,添加server master iburst
2.2.3 激活启动NTP服务

2.3 检测是否成功
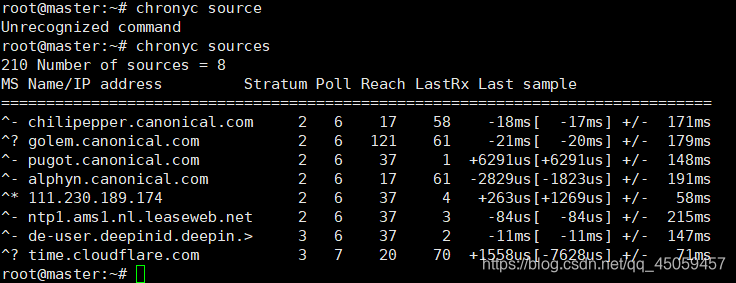
2.3.1 主节点测试
chronyc sources
2.3.2 从节点测试

到此NTP完成。
3 . 免密码SSH设置
目的是为了将编辑好的文档下发到从节点
3.1所有节点创建组
sudo groupadd -g 285 angel
(可以在bass普通用户下操作,可以在root用户下操作。若在bass需要提高权限sudo,root用户则不用。)

285 是组号,angel是组名。
3.2 所有节点创建用户
$ sudo useradd -u 285 -g 285 -m -s /bin/bash angel

用户号为285,用户组号为285,用户名为angel。
3.3 设置angel用户的密码
sudo gpasswd -a angel sudo
将angel用户添加到sudo组。

sudo passwd angel
密码为123

3.4 切换angel用户
su - angel
密码:123

3.5 生成证书(在主节点上操作)
ssh-keygen -t rsa
加密算法选择rsa,

3.6 将公钥复制到所有点
3.6.1 主节点
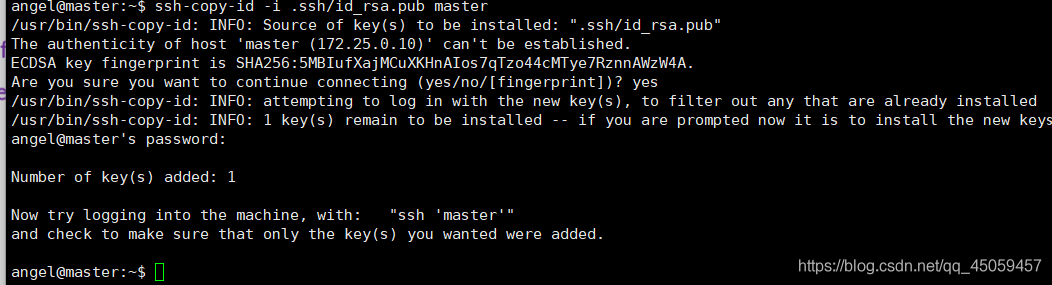
ssh-copy-id -i .ssh/id_rsa.pub master
yes
密码:123
3.7 测试
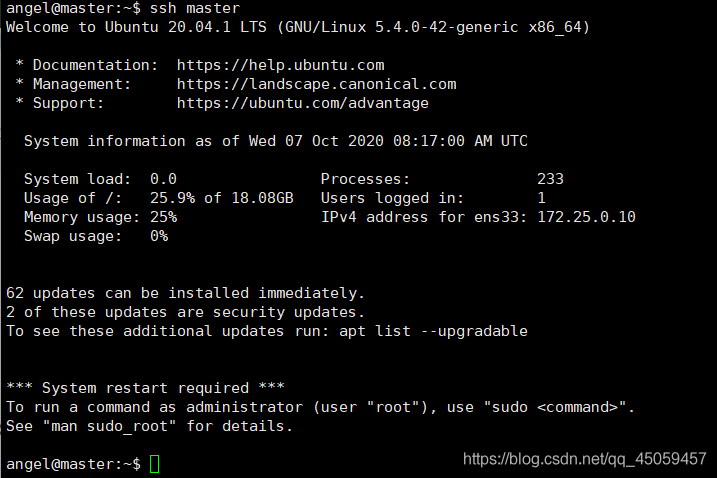
ssh master
ctrl+D 退出
logout
3.7.1 在主节点连接从节点
ssh slave1
ssh slave2
4.Java安装
4.1 所有节点建立app目录
在angel用户下建立
sudo mkdir /app

sudo chown -R angel:angel /app
4.2 所有节点编辑jdk环境变量
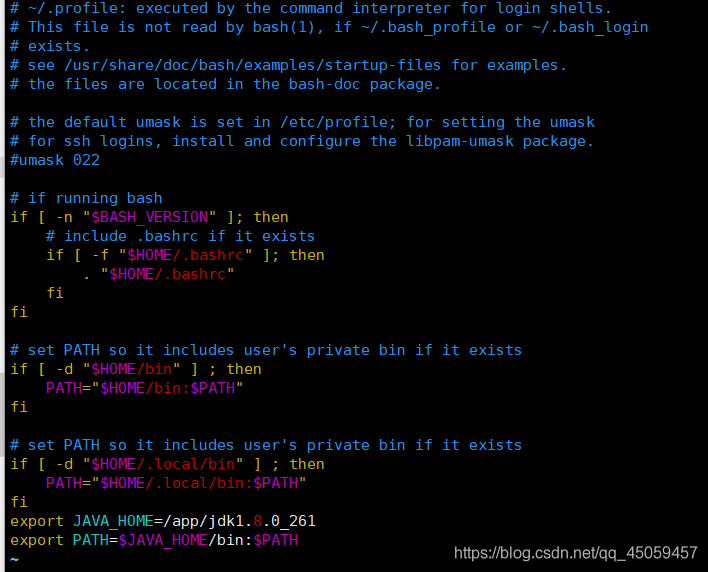
vi /home/angel/.profile
在最后添加2行
4.3 所有节点jdk环境变量生效
source /home/angel/.profile
4.4 上传jdk压缩到angel用户下
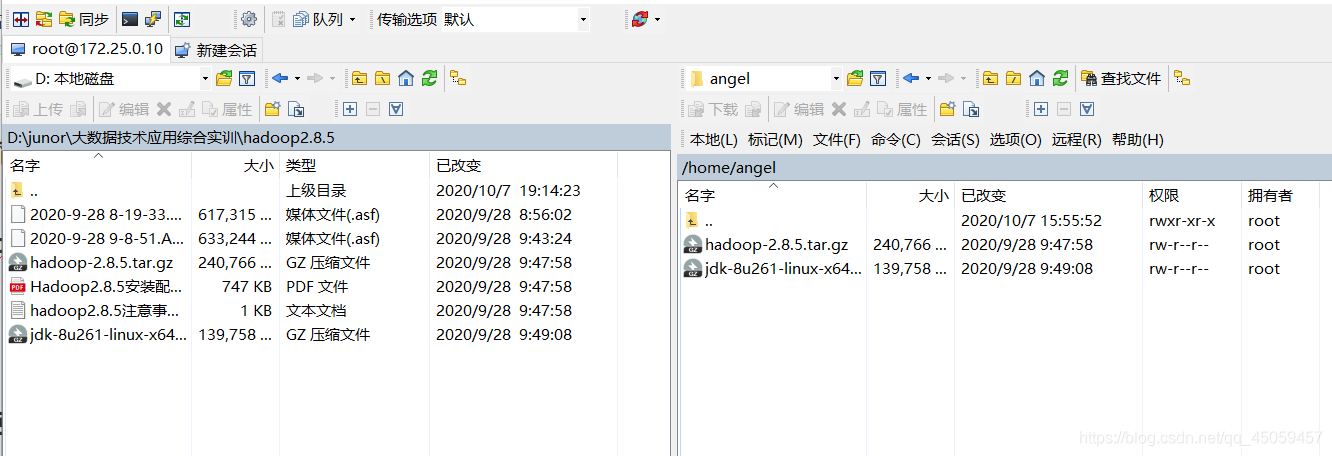
4.4.1 用winscp工具,用root用户登录
4.5 将jdk压缩包解压放在/app目录下
cd /app
tar xzvf /home/angel/jdk-8u261-linux-x64.tar.gz -C /app

5.将/app上的内容下发到从节点
scp -r /app/* angel@slave1:/app
scp -r /app/* angel@slave2:/app
6 测试
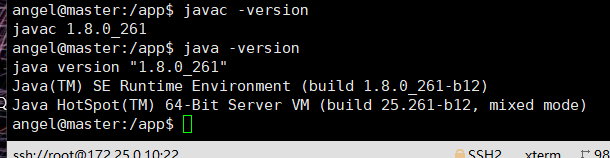
java -version
javac -version
7 Hadoop安装
7.1 上传hadoop包到angel用户下
tar xzvf /home/angel/hadoop-2.8.5.tar.gz -C /app
7.2 所有节点编辑Hadoop环境变量
vi /home/angel/.profile
添加:
export HADOOP_HOME=/app/hadoop-2.8.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop

7.3 所有节点Hadoop环境变量生效
source /home/angel/.porfile
7.4 修改Hadoop配置文件
7.4.1 hadoop-env.sh
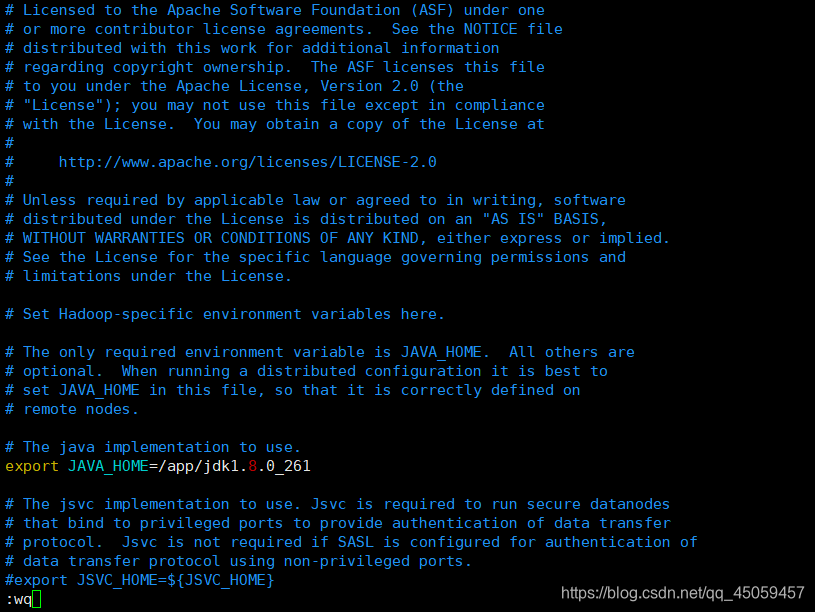
vi /app/hadoop-2.8.5/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/app/jdk1.8.0_261
7.4.2 core-site.xml
vi /app/hadoop-2.8.5/etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-2.8.5</value>
</property>
<property>
<name>hadoop.proxyuser.angel.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.angel.groups</name>
<value>*</value>
</property>

7.4.3 hdfs-site.xml
vi /app/hadoop-2.8.5/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/app/hadoop-2.8.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/app/hadoop-2.8.5/dfs/data</value>
</property>

7.4.4 mapred-site.xml
先将 mapred-site.xml.template复制命名为mapred-site.xml
cp /app/hadoop-2.8.5/etc/hadoop/mapred-site.xml.template /app/hadoop-2.8.5/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>

7.4.5 yarn-site.xml
vi /app/hadoop-2.8.5/etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
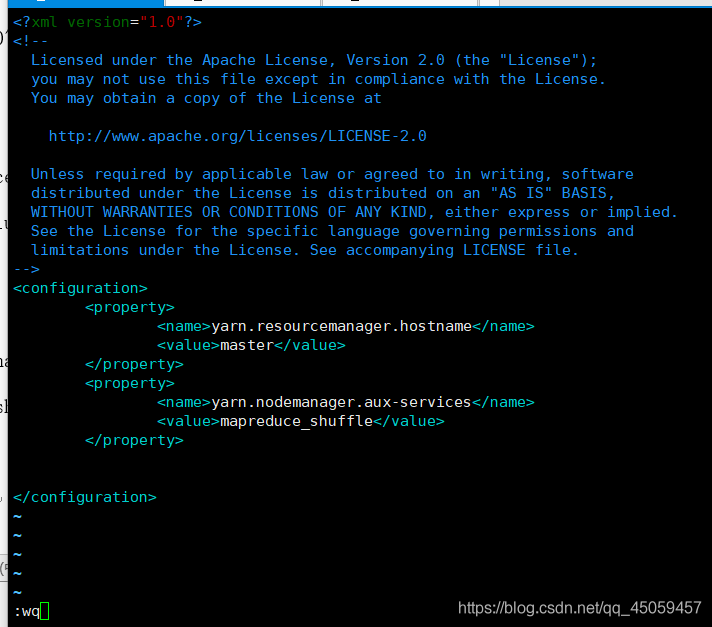
7.4.6 slaves
vi /app/hadoop-2.8.5/etc/hadoop/slaves
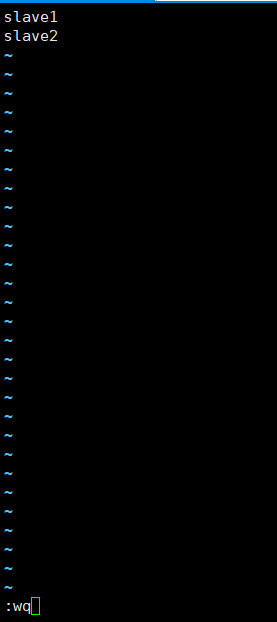
7.5 复制到从节点
scp -r /app/hadoop-2.8.5/ angel@slave1:/app
scp -r /app/hadoop-2.8.5/ angel@slave2:/app
耐心等待下发完成
8.Hadoop启动
8.1 格式化 namenode
hdfs namenode -format
8.2 启动Hadoop
start-dfs.sh
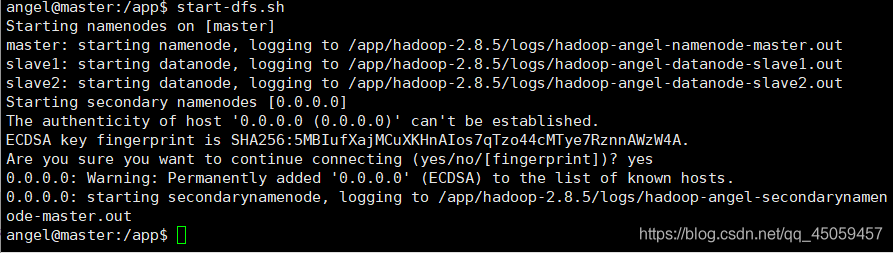
8.3 启动yarn
start-yarn.sh

8.4 启动JobHistoryServer
mr-jobhistory-daemon.sh start historyserver

8.5 查看进程
8.5.1 master节点
jps
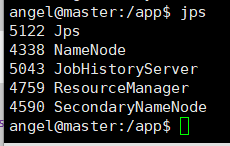
8.5.2 slave1,slave2节点
jps
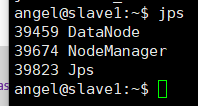
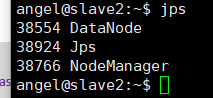

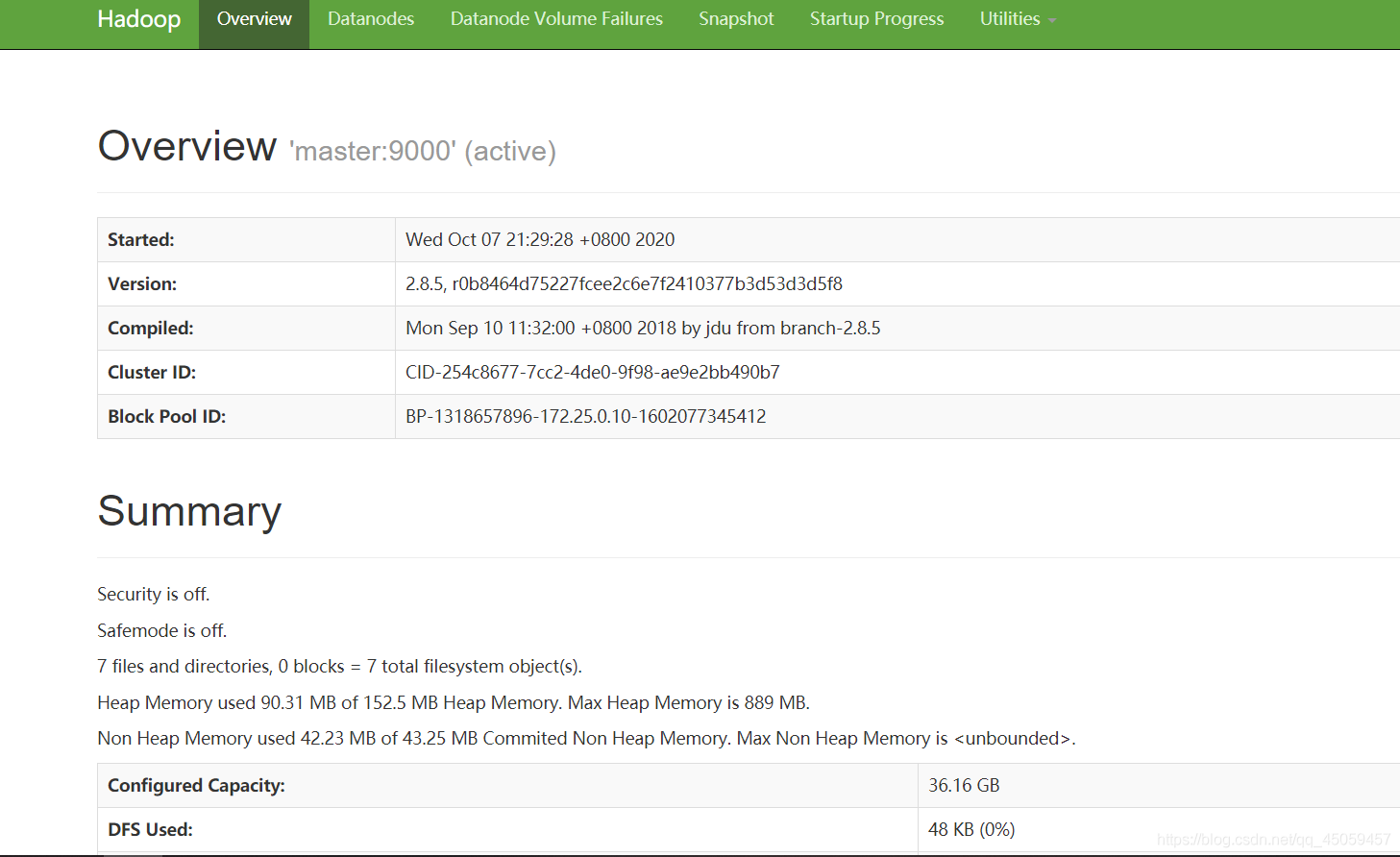
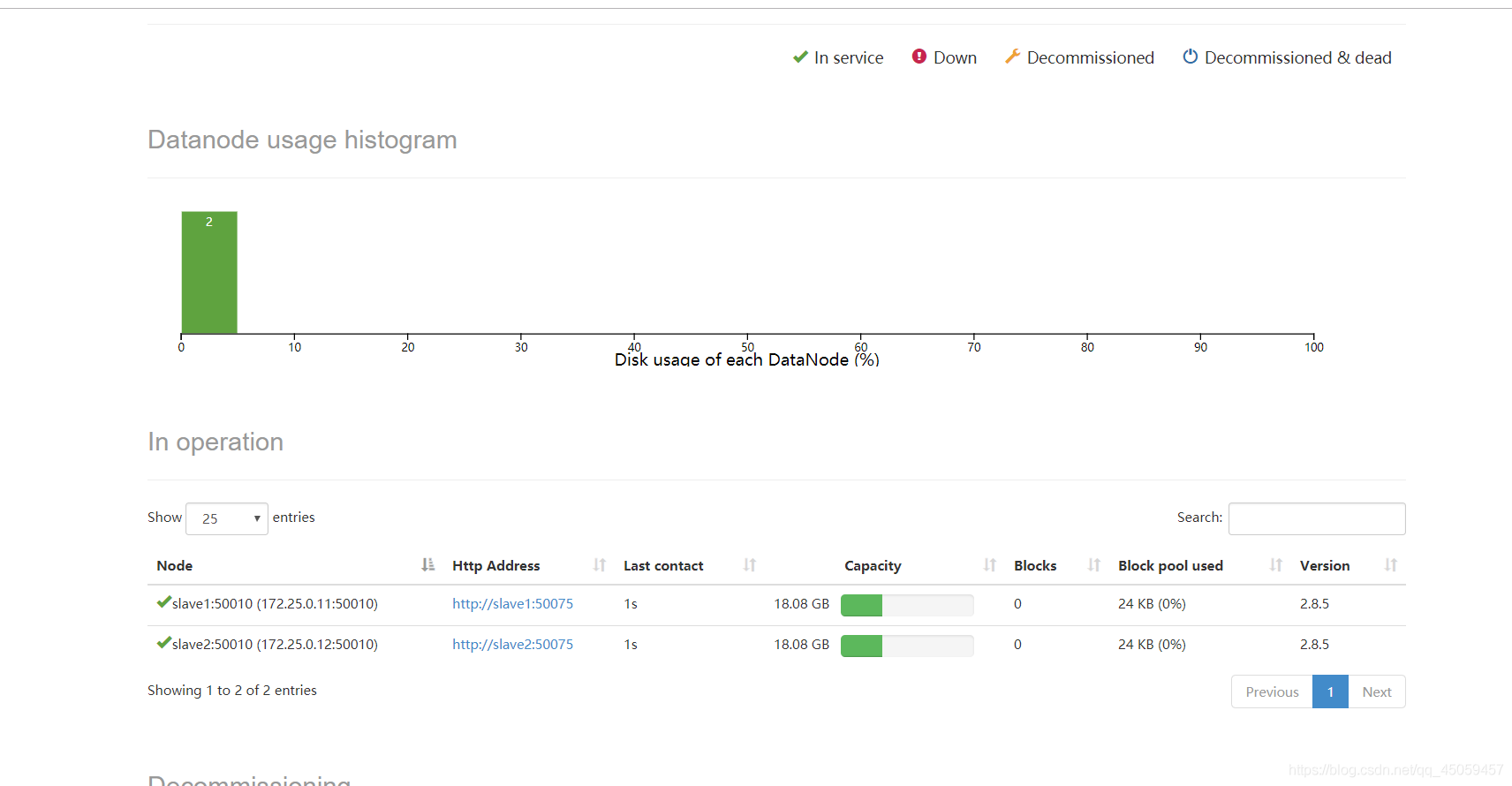
节点机有2个活的,端口号50070,8088
到此hadoop环境配置成功!