第八章:集群配置
8.1集群配置
- 集群部署规划
| hadoop104 | hadoop105 | hadoop106 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryName NodeDataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
- 配置集群
(1)核心配置文件
配置core-site.xml
[zhangyong@hadoop104 hadoop]$ vi core-site.xml
在该文件中编写如下配置
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop104:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.2/data/tmp</value>
</property>
(2)HDFS配置文件
配置hadoop-env.sh
[zhangyong@hadoop104 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181
配置hdfs-site.xml
[zhangyong@hadoop104 hadoop]$ vi hdfs-site.xml
在该文件中编写如下配置
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop106:50090</value>
</property>
(3)YARN配置文件
配置yarn-env.sh
[zhangyong@hadoop104 hadoop]$ vi yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181
配置yarn-site.xml
[zhangyong@hadoop104 hadoop]$ vi yarn-site.xml
在该文件中增加如下配置
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop105</value>
</property>
(4)MapReduce配置文件
配置mapred-env.sh
[zhangyong@hadoop104 hadoop]$ vi mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181
配置mapred-site.xml
[zhangyong@hadoop104 hadoop]$ vi mapred-site.xml
在该文件中增加如下配置
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.在集群上分发配置好的Hadoop配置文件
[zhangyong@hadoop104 hadoop]$ xsync etc/
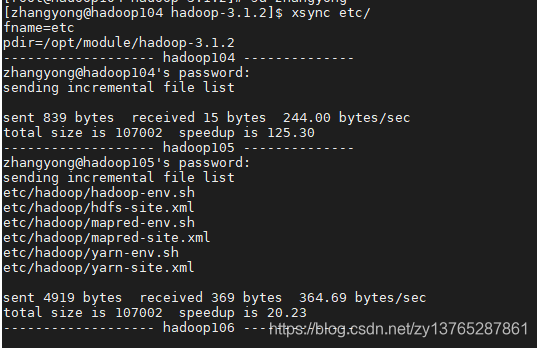
4.查看文件分发情况
[zhangyong@hadoop103 hadoop]$ cat /opt/module/hadoop-3.1.2/etc/hadoop/core-site.xml
8.2 集群单点启动
(1)如果集群是第一次启动,需要格式化NameNode
[zhangyong@hadoop104 hadoop-3.1.2]$ hdfs namenode -format
(2)在hadoop102上启动NameNode
[zhangyong@hadoop104 hadoop-3.1.2]$ hadoop-daemon.sh start namenode
[zhangyong@hadoop104 hadoop-3.1.2]$ jps
3461 NameNode
(3)在hadoop104、hadoop105以及hadoop106上分别启动DataNode
[zhangyong@hadoop104 hadoop-3.1.2]$ hadoop-daemon.sh start datanode
[zhangyong@hadoop104 hadoop-3.1.2]$ jps
3461 NameNode
3608 Jps
3561 DataNode
[zhangyong@hadoop105 hadoop-3.1.2]$ hadoop-daemon.sh start datanode
[zhangyong@hadoop105 hadoop-3.1.2]$ jps
3190 DataNode
3279 Jps
[zhangyong@hadoop106 hadoop-3.1.2]$ hadoop-daemon.sh start datanode
[zhangyong@hhadoop106 hadoop-3.1.2]$ jps
3237 Jps
3163 DataNode
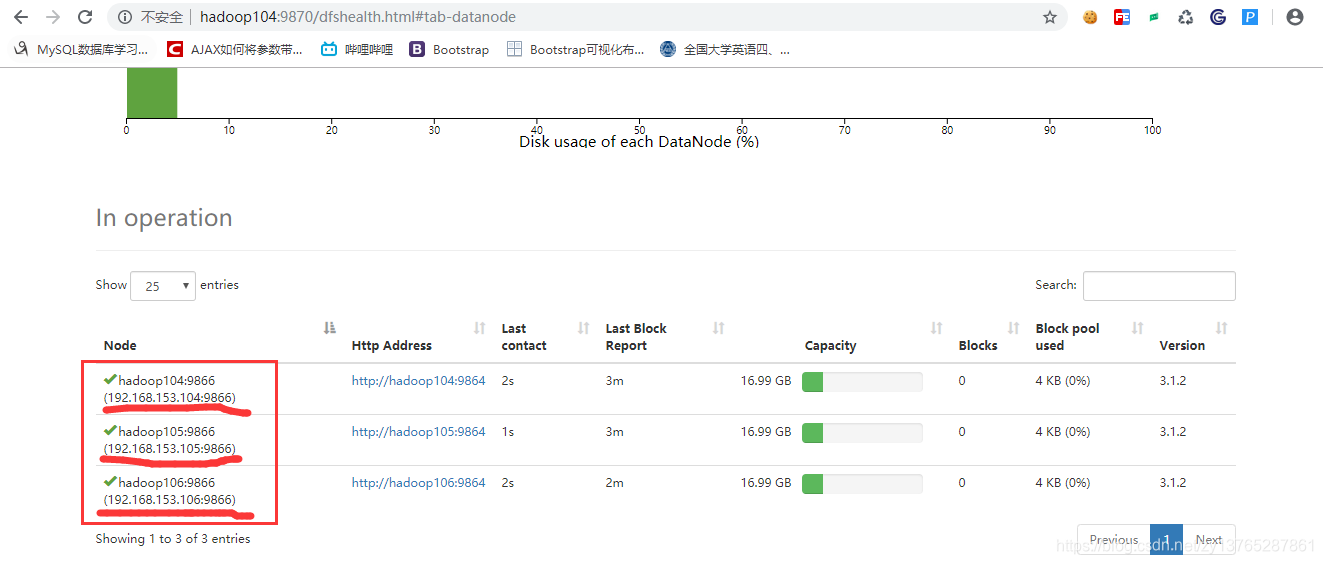
http://hadoop104:9870/dfshealth.html#tab-datanode添加链接描述
访问如下说明成功了
思考:每次都一个一个节点启动,如果节点数增加到1000个怎么办?,下一章解答
