硬件资源
两台服务器:
master 128g;slave 64g
场景为测试环境,用root用户
1.修改主机名
hostnamectl set-hostname master
hostnamectl set-hostname slave
重新连接
2.修改/etc/hosts
[root@master ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.61.165 master
192.168.61.163 slave3.SSH免密登录
ssh-keygen -t rsa
cp /root/.ssh/id_rsa.pub authorized_keys
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave
cat /root/.ssh/id_rsa.pub >>/root/.ssh/authorized_keys4.安装JDK
4.1 卸载系统自带JDK
[root@master ~]# rpm -qa|grep java
java-1.8.0-openjdk-headless-1.8.0.131-3.b12.el7_3.x86_64
javamail-1.4.6-8.el7.noarch
python-javapackages-3.4.1-11.el7.noarch
tzdata-java-2017b-1.el7.noarch
pki-base-java-10.3.3-18.el7_3.noarch
java-1.7.0-openjdk-headless-1.7.0.141-2.6.10.1.el7_3.x86_64
libguestfs-java-1.32.7-3.el7.centos.2.x86_64
javapackages-tools-3.4.1-11.el7.noarch
nuxwdog-client-java-1.0.3-5.el7.x86_64
javassist-3.16.1-10.el7.noarch
java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64rpm -e --nodeps java-1.8.0-openjdk-1.8.0.131-3.b12.el7_3.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.131-3.b12.el7_3.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64 4.2安装配置jdk
mkdir /opt/java
cp jdk-8u171-linux-x64.tar.gz /opt/java/
tar zxf /opt/java/jdk-8u171-linux-x64.tar.gz
rm -f /opt/java/jdk-8u171-linux-x64.tar.gz
scp -rp /opt/java/jdk1.8.0_171 slave:/opt/java/vi /etc/profile
export JAVA_HOME=/opt/java/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=/opt/hadoop/hadoop-2.9.0/bin:$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
验证
root@master java]# source /etc/profile
root@master java]# javac
用法: javac <options> <source files>
其中, 可能的选项包括:
-g 生成所有调试信息
-g:none 不生成任何调试信息
-g:{lines,vars,source} 只生成某些调试信息
...5.安装hadoop
hadoop下载: http://mirrors.shu.edu.cn/apache/hadoop/common/
5.1创建文件夹
mkdir -p /root/hadoop
mkdir -p /root/hadoop/tmp
mkdir -p /root/hadoop/var
mkdir -p /root/hadoop/dfs
mkdir -p /root/hadoop/dfs/name
mkdir -p /root/hadoop/dfs/data 5.2解压
/opt/hadoop
tar zxvf hadoop-2.9.0.tar.gz
rm -f hadoop-2.9.0.tar.gz 5.3 修改配置文件
/opt/hadoop/hadoop-2.9.0/etc/hadoop/
扫描二维码关注公众号,回复:
553808 查看本文章

5.3.1 修改hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}改为
export JAVA_HOME=/opt/java/jdk1.8.0_171将 export HADOOP_CONF_DIR=${HADOOP_DEV_HOME}/etc/hadoop
export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.9.0/etc/hadoop增加一行:
export HADOOP_HOME=/opt/hadoop/hadoop-2.9.0/bin5.3.2 修改slaves文件
将slaves里面的localhost删除,添加slave
5.3.3 修改core-site.xml文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>5.3.4修改hdfs-site.xml文件
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
</property>5.3.5 新建及修改mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml<property>
<name>mapred.job.tracker</name>
<value>master:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> 5.3.6 修改yarn-site.xml文件
这里先不做过多配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> 6.master分发至slave
scp -rp hadoop-2.9.0 slave:/opt/hadoop/7.启动hadoop
cd /opt/hadoop/hadoop-2.9.0/bin
./hadoop namenode –format
cd /opt/hadoop/hadoop-2.9.0/sbin
./start-all.sh [root@master sbin]# jps
13473 ResourceManager
13236 SecondaryNameNode
13764 Jps
12969 NameNode
15663 DecryptStart
[root@slave hadoop]# jps
44387 DataNode
44535 NodeManager
44767 Jps8.访问网页
systemctl stop firewalldhttp://192.168.61.165:50070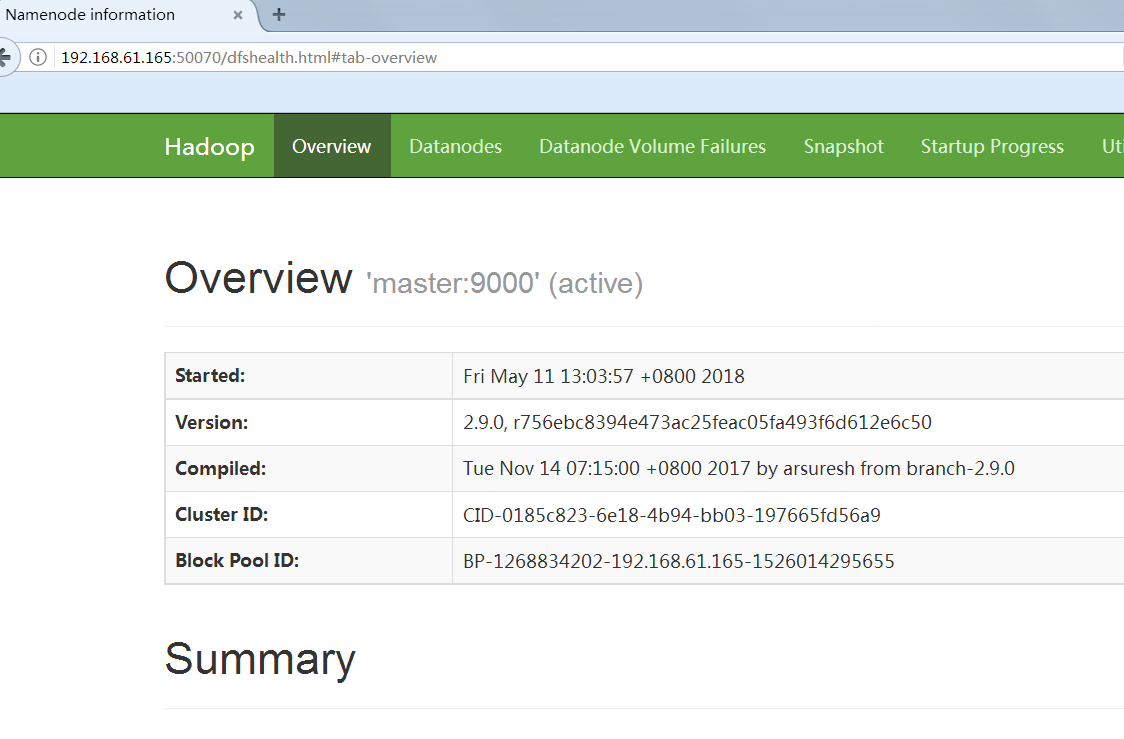
9.wordcount
[root@master sbin]# hdfs dfs -mkdir /input
[root@master sbin]# hdfs dfs -put /opt/hadoop/hadoop-2.9.0/etc/hadoop/hadoop-env.sh /input
[root@master sbin]# hdfs dfs -ls /input
Found 1 items
-rw-r--r-- 3 root supergroup 4726 2018-05-11 13:33 /input/hadoop-env.sh
[root@master sbin]# hadoop jar /opt/hadoop/hadoop-2.9.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.0.jar wordcount /input output
18/05/11 13:35:38 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.61.165:8032
18/05/11 13:35:40 INFO input.FileInputFormat: Total input files to process : 1
18/05/11 13:35:40 INFO mapreduce.JobSubmitter: number of splits:1
18/05/11 13:35:40 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/05/11 13:35:40 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1526016684737_0001
18/05/11 13:35:41 INFO impl.YarnClientImpl: Submitted application application_1526016684737_0001
18/05/11 13:35:41 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1526016684737_0001/
18/05/11 13:35:41 INFO mapreduce.Job: Running job: job_1526016684737_0001
18/05/11 13:35:43 INFO mapreduce.Job: Job job_1526016684737_0001 running in uber mode : false
18/05/11 13:35:43 INFO mapreduce.Job: map 0% reduce 0%
18/05/11 13:35:43 INFO mapreduce.Job: Job job_1526016684737_0001 failed with state FAILED due to: Application application_1526016684737_0001 failed 2 times due to Error launching appattempt_1526016684737_0001_000002. Got exception: org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container.
This token is expired. current time is 1526017552962 found 1526017542496
Note: System times on machines may be out of sync. Check system time and time zones.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateExceptionImpl(SerializedExceptionPBImpl.java:171)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.instantiateException(SerializedExceptionPBImpl.java:182)
at org.apache.hadoop.yarn.api.records.impl.pb.SerializedExceptionPBImpl.deSerialize(SerializedExceptionPBImpl.java:106)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.launch(AMLauncher.java:126)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.run(AMLauncher.java:307)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
. Failing the application.
18/05/11 13:35:43 INFO mapreduce.Job: Counters: 0从报错信息来看,是因为master和slave之间未设置时间同步
修改后执行成功:
[root@master sbin]# hdfs dfs -cat /user/root/output/part-r-00000
"" 1
"$HADOOP_CLASSPATH" 1
"$HADOOP_HEAPSIZE" 1
"AS 1
"License"); 1
# 55
### 4
#HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData 1
...