环境说明
示例环境 |
|||||
主机名 |
IP |
角色 |
系统版本 |
数据目录 |
Hadoop版本 |
master |
192.168.174.200 |
nameNode |
CentOS Linux release 7.4.1708 (Core)
|
2.8.0 |
|
slave1 |
192.168.129.201 |
dataNode |
CentOS Linux release 7.4.1708 (Core) |
2.8.0 |
|
准备工作
JDK安装
确认本机安装的JDK版本为1.7以上,建议为1.8.
查看本机安装JDK
rpm -e --nodeps 'rpm -qa | grep java'
如:安装过其他版本的JDK,移除原JDK
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.131-11.b12.el7.x86_64 rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.141-2.6.10.5.el7.x86_64 rpm -e --nodeps java-1.7.0-openjdk-1.7.0.141-2.6.10.5.el7.x86_64 rpm -e --nodeps java-1.8.0-openjdk-1.8.0.131-11.b12.el7.x86_64
下载JDK
curl -O http://download.oracle.com/otn-pub/java/jdk/8u161-b12/2f38c3b165be4555a1fa6e98c45e0808/jdk-8u161-linux-x64.tar.gz?AuthParam=1520556529_7efdd22074a16eff52be3c1e15843903
解压
tar -zxvf jdk-8u161-linux-x64.tar.gz
配置环境变量
gedit ~/.bashrc
或
vim ~/.bashrc
配置添加如下图:

立即生效
source ~/.bashrc
修改本机信息
修改主机名(分别在两台虚拟机修改为:master、slave1、..):
vi /etc/hostname增加IP与主机映射:
vi /etc/hosts #增加以下内容: 192.168.174.200 master 192.168.174.201 slave1
SSH免密码登录
打开终端执行如下命令进行检验rpm -qa | grep ssh如果返回的结果如下图所示,包含了 SSH client 跟 SSH server,则不需要再安装。

若需要安装,则可以通过 yum 进行安装(安装过程中会让你输入 [y/N],输入 y 即可):
yum install openssh-clients yum install openssh-server
设置免登录
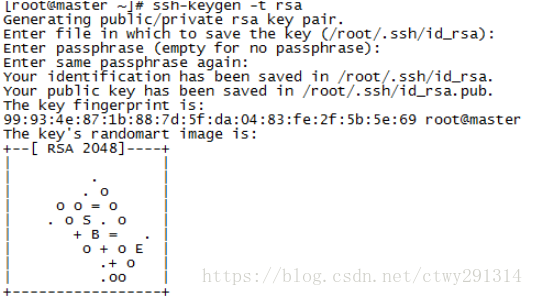
主节点 ssh localhost 查看用户主目录.ssh文件夹下 cd .ssh/ ssh-keygen -t rsa#连续回车,系统自动生成图形公钥 #将生成的公钥id_rsa.pub 内容追加到authorized_keys cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys 从节点 ssh localhost 查看用户主目录.ssh文件夹下 cd .ssh/ ssh-keygen -t rsa#连续回车,系统自动生成图形公钥 #将从节点的id_rsa.pub复制到主节点并改名为id_rsa.pub.s1 scp id_rsa.pub master:/root/.ssh/id_rsa.pub.s1 主节点 #将从节点的id_rsa.pub.s1公钥追加到主节点的authorized_keys中 cat id_rsa.pub.s1 >> authorized_keys #将生成的包含从节点的秘钥的authorized_keys 复制到从节点的.ssh目录下 scp authorized_keys slave1:/root/.ssh/
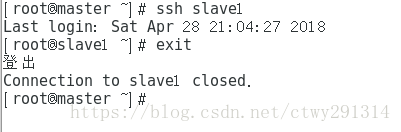
验证ssh的免密码登录:
在master中输入:ssh slave1是否需要密码,如果不需要,则ssh免密码配置成功。
安装ZooKeeper
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
解压
tar -zxvf zookeeper-3.4.10.tar.gz
移动文件夹
mv zookeeper-3.4.10 /usr/local/haddop
修改配置
cd /usr/local/hadoop/zookeeper-3.4.10/conf mv zoo_sample.cfg zoo.cfg vim zoo.cfg
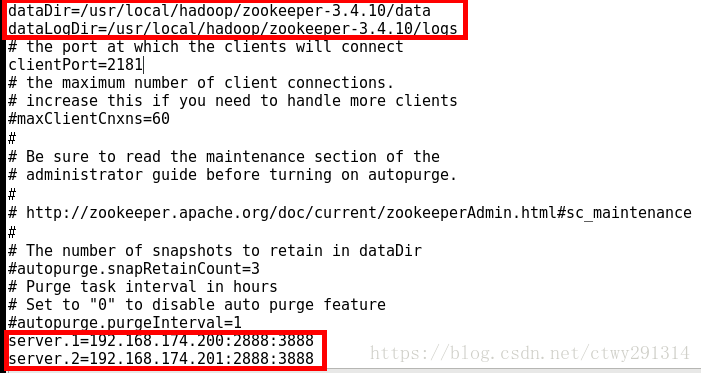
复制到从机
scp zookeeper-3.4.10 slave1:/usr/local/hadoop/根据dataDir进行X的配置(主从机均执行)
cd /usr/local/hadoop/zookeeper-3.4.10 mkdir data cd data vim myid #之后会产生一个新文件,直接在里面写 X 即可 #比如我配置的三个server,myid里面写的X就是server.X=ip:2888:3888 中ip所对应的X server.1=192.168.174.200:2888:3888【192.168.174.200服务器上面的myid填写1】 server.2=192.168.174.201:2888:3888【192.168.174.201服务器上面的myid填写2】
启动(主从均执行)
cd /usr/local/hadoop/zookeeper-3.4.10/bin zkServer.sh start
检查状态
zkServer.sh status
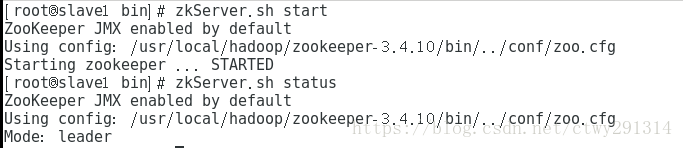
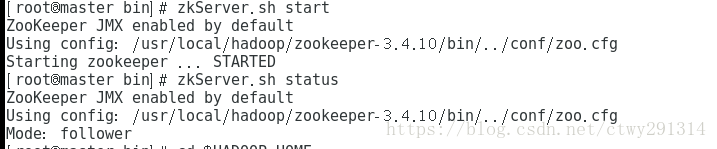
Hadoop安装及配置
下载
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
解压
tar -zxvf hadoop-2.8.0.tar.gz
移动文件夹
mv hadoop-2.8.0 /usr/local/haddop
配置环境变量
参照上节JDK安装配置环境变量
修改配置文件
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/core-site.xml文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
修改hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/data/hadoop/hdfs/snn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:/data/hadoop/hdfs/snn</value>
</property>
<property>
<name>fs.datanode.data.dir</name>
<value>file:/data/hadoop/hdfs/dn</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
新建并且修改mapred-site.xml
在该版本中,有一个名为mapred-site.xml.template的文件,复制该文件,然后改名为mapred-site.xml,命令是:
cp /usr/local/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
修改slaves文件
修改/usr/local/hadoop/hadoop-2.8.0/etc/hadoop/slaves文件,将里面的localhost删除,添加如下内容:
slave1
修改yarn-site.xml文件
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/yarn-site.xml文件,
在<configuration>节点内加入配置(注意了,内存根据机器配置越大越好,我这里只配2个G是因为机器不行):<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8090</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>file:/data/hadoop/yarn/nm</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> <discription>每个节点可用内存,单位MB,默认8182MB</discription> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
说明:yarn.nodemanager.vmem-check-enabled这个的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉。
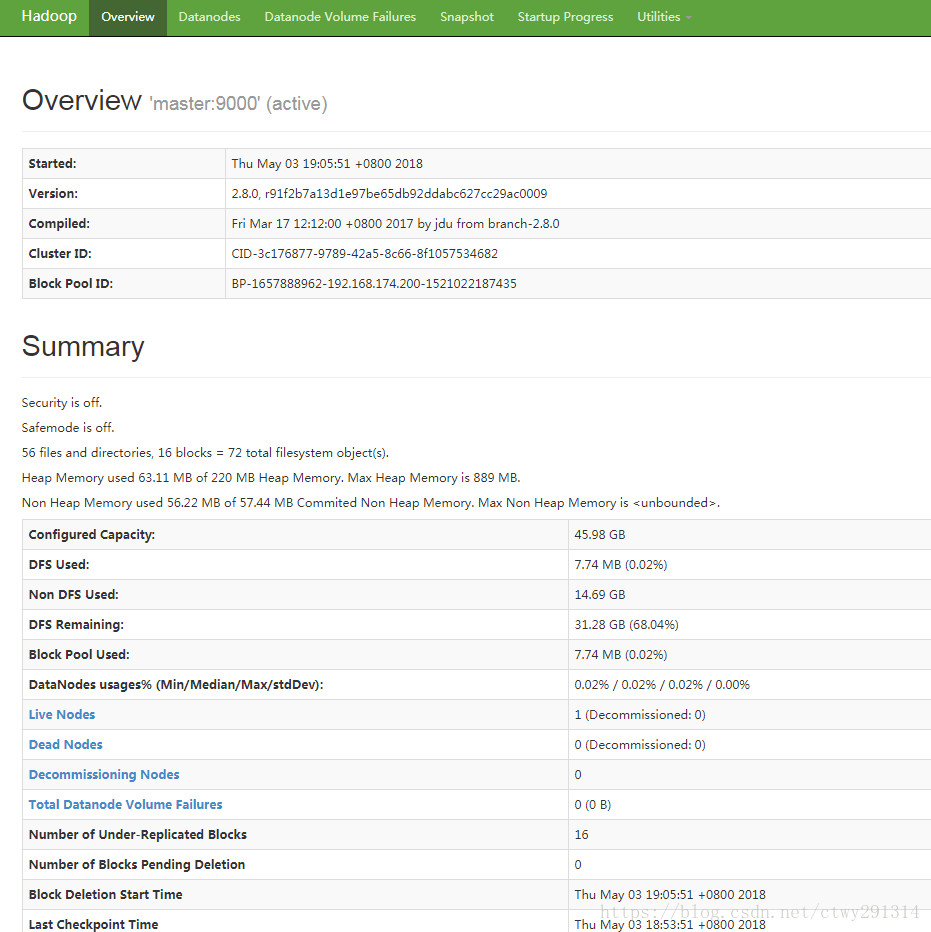
启动hadoop
在namenode上执行初始化
因为master是slave1是datanode,所以只需要对master进行初始化操作,也就是对hdfs进行格式化cd /user/local/hadoop/hadoop-2.8.0/bin
执行初始化脚本,也就是执行命令:
./hadoop namenode -format
关闭防火墙,CentOS7下,命令:
systemctl stop firewalld.service
启动Hadoop集群
sbin/start-all.sh
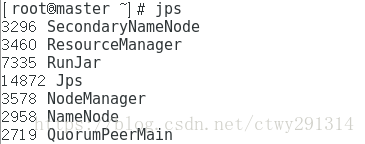
启动后,master上进程和slave进程列表