我们提出了一种新的神经网络模型,用于使用矢量积神经元和维度变换进行音乐信号处理。 这里,输入首先从实际值映射到三维矢量,然后馈入三维矢量乘积神经网络,其中输入,输出和权重都是三维值。 接下来,最终输出将映射回实数。 提出了两种维数变换方法,一种是通过上下文窗口,另一种是通过光谱着色。 用于盲唱语音分离的iKala数据集的实验结果证实了我们模型的有效性。
Introduction
近年来,深度学习在音乐信息检索(MIR)社区中变得越来越流行。 对于需要剪辑级预测或逐帧预测的MIR问题,例如类型分类,音乐分割,起始检测,和弦识别和人声/非人声检测,许多现有算法基于卷积神经网络(CNN)和 递归神经网络(RNN)。对于需要估计频谱图中每个时频(t-f)单位的音频回归问题,例如源分离[Zhang and Wang,2016],更多算法基于深度神经网络(DNN)。 这是因为对于这样的问题,输入和输出都是相同大小的矩阵,因此神经网络不能涉及可能降低空间分辨率的操作。针对此类问题的现有DNN模型通常将每个t-f单元视为实际值,并将其作为网络的输入[Huang et al。,2014,Roma et al。,2016]。 我们要在本文中讨论的问题是,我们是否可以通过应用一些转换方法来丰富每个t-f单元的信息,从而获得更好的结果。
一种广泛使用的方法来丰富每个t-f单元的信息是增加时间背景[Zhang and Wang,2016]。 例如,除了当前帧之外,我们还添加了previousk和后续k帧以组成实值矩阵并将其作为神经网络的输入。 但是通过这种方式,不同尺寸之间的相互作用无法很好地建模。为了解决这个问题,我们发现它有望考虑(2k + 1)维神经网络[Nitta,2007]。 作为第一次尝试,我们使用矢量产品神经网络(VPNN)[Nitta,1993]实现了这一点,这是一个三维神经网络,仅在文献中的简单XOR任务上进行了测试。也就是说,该工作中的k被设置为1(即仅考虑两个相邻帧)。 通过该维数变换方法将每个t-f单元投影到三维矢量。 在VPNN中,每个神经元的输入,输出,权重和偏差都是三维向量。 虽然DNN中的主要操作是矩阵乘法,但它是VPNN中的向量乘积。
本文的目标是三重的。 首先,我们使用现代优化技术[Ruder,2016]对VPNN进行翻新,并在MIR问题上进行测试,而不是简单的XOR问题。 其次,我们使用实际值和富含上下文的VPNN结构测试和比较传统的上下文丰富的DNN结构,用于盲声歌唱与单声道录音分离的特定任务,这是一种源分离问题。第三,我们将光谱着色的思想实现为将实值矩阵转换为三维向量值矩阵的另一种方法,并再次评估该方法用于盲唱语音分离。 我们的实验证实了VPNN和两种维度转换方法的有效性。
Vector Product Neural Network
在VPNN中,输入数据,权重和偏差都是三维向量。 假设存在L-中间层VPNN,第l层的每个神经元中的激活函数的输入zl i是:
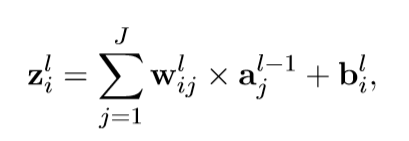
×表示矢量积,wlij表示连接J和I神经元在第L层的权重,aj 是输入信号,从神经元j在第l-1层中得到,bi是神经元i在第l层的偏置。如果x=[x1,x2,x3],y=[y1,y2,y3],向量积操作结果如下:
![]()
由于输出矢量的每个元素都接收来自所有其他维度的贡献,因此矢量积可以捕获三个维度之间的所有可能的相互作用。 这对于实值神经网络模型是不可能的。
请注意,我们需要在VPNN中的层之间计算很多矢量积。 为了减少训练时间,我们建议将矢量积重新表示为矩阵乘法,这更适合GPU加速。 假设有两个向量值矩阵P和Q.它们的向量值矩阵乘积⊗可以等效地写成:

其中p1,p2,p3是构成P的矩阵,q1,q2,q3是构成Q的矩阵。通过应用Eq。 (2),隐藏层l的输出可以定义为:

VPNN的输出Y是矢量值矩阵,可以定义为:

运算符⊗表示方程式中提到的向量值矩阵乘积。(2)。 在第l层,Al是隐藏状态,W1是权重矩阵,B1是偏置矩阵。 所有这些都是矢量值矩阵。在第一层,A0是VPNN的输入,由来自维度变换的矢量值数据组成。 函数φ是sigmoid函数。 为了获得更好的性能,现代梯度优化方法[Ruder,2016]在我们的VPNN中实现。 由于空间限制,我们只使用Adam(一种随机梯度下降的方法)报告我们的结果。
维度转换和目标函数
在本节中,我们详细阐述了维度转换的两个想法。 一种是基于添加第1节中描述的时间上下文。另一种是基于称为光谱着色的新技术,其将每个t-f单元与RGB颜色空间中的颜色相关联。 这两种想法都产生三维向量作为VPNN的输入。
Context-Windowed Transformation
为了丰富每个t-f单元的信息并改善不同维度之间的相互作用问题,我们将当前帧,前一帧和后一帧作为每个t-f单元的三维向量。 对于普通NN,输入将是三个实值矩阵。对于VPNN,输入是三维矩阵。 换句话说,第一维包括先前帧,当前帧的第二维和后续帧的第三维。 这里我们将此模型称为上下文窗口矢量产品神经网络(WVPNN)。 在将三维矩阵馈入VPNN后,我们得到三维输出,第二维是我们的预测结果。
Spectral Color Transformation
我们还可以通过使用所谓的光谱颜色变换将每个tf单元从一维值映射到三维矢量,例如使用Matlab中的热色图直接作为查找表,其中正向和反向映射是 两者均由最近邻搜索计算。 热色图与分辨率参数相关联,该参数指定色图的长度。 当n倾向于无穷大时,最近邻插值将转变为分段线性插值,我们可以通过以下分段线性函数以有限分辨率模拟热色图:
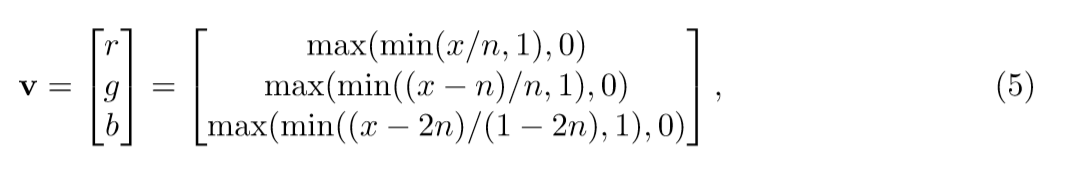
其中v代表三维矢量值矢量,r,g和b分别代表R,G和B值,x代表每个t-f单位的大小,n代表偏置RGB值产生的标量。 我们在这项工作中凭经验将n设置为0.0938。 我们称这个模型为彩色矢量产品神经网络(CVPNN)。 将RGB值输入VPNN后,我们将RGB值作为输出。 然后将每个RGB值反转映射到每个t-f单位的幅度。
Target Function and Masking
在歌声分离的训练过程中,给定预测的声谱~Z1和预测的音乐谱~Z2,连同原始源Z1和Z2,WVPNN和CVPNN的目标函数J可以定义为:

在从WVPNN和CVPNN获得输出后,我们可以获得预测的光谱y〜1和y〜2。 我们使用称为软时频掩模的时频掩蔽技术来平滑结果[Huang et al。,2015],并且输入帧的幅度谱可以通过逆STFT与原始帧转换回时域。阶段。
Experiments
通过在iKala数据集上进行歌唱分离实验来评估所提出的模型[Chan et al。,2015]。 仅发布252个歌曲剪辑作为公共场景进行评估。 由于GPU内存的限制,我们将公共集划分为63个训练片段和189个测试片段。 为减少计算,所有剪辑都被下采样到16000 Hz。 对于每个歌曲片段,我们使用STFT来产生具有1024点窗口和256点跳跃大小的幅度谱。通过盲源分离(BSS)Eval工具箱v3.0 [Vincent et]计算的性能来源于失真比(SDR),源干扰比(SIR)和源 - 伪影比(SAR)。 al。,2006]。 通过全局NSDR(GNSDR),全局SIR(GSIR)和全局SAR(GSAR)报告整体性能,这是对所有剪辑的度量的加权方式,其权重与剪辑的长度成比例。 数字越高意味着表现越好。
为了比较普通DNN和CVPNN的性能,我们构建了两个网络,每个网络由3个隐藏层和每个隐藏层中的512个神经元组成,分别用CVLNN和DNN1表示,使用Eq。 (6)作为目标函数。 普通DNN的每个t-f单元的维数为1,CVPNN的维数为3。 在[Roma et al。,2016]中使用了与此DNN1类似的网络结构。如表1所示,在GNSDR和GSIR中,CVPNN的性能优于DNN1。 由于CVPNN与DNN1相比具有三倍的NN参数(即权重和偏差的数量),为了公平比较,我们进一步构建普通DNN,其包括3个隐藏层和每个隐藏层中的1536个神经元,表示为DNN2,因此两个CVPNN 普通DNN具有相同数量的参数。表1显示CVPNN仍然表现更好。 此外,我们还构造了两个具有相同参数数量的体系结构和由3个上下文窗口大小组成的t-f单元,分别表示为WVPNN和DNN3。 它们都由3个隐藏层组成。 WVPNN中每个隐藏层的神经元数量为512,DNN为1536。 这两者的不同之处在于输入帧的组合。输入帧被构造为用于WVPNN的三维矢量值矩阵和用于DNN3的二维值矩阵。 表1中的结果表明WVPNN比普通DNN3表现更好。

Conclusion and Future Work
在本文中,我们提出了WVPNN和CVPNN用于单声道歌唱分离,使用二维变换方法。 我们还在VPNN上提出了现代梯度优化方法,以获得更好的性能。 我们的评估表明,两种提出的模型都优于传统的DNN,GNSDR增益为0.16-0.85 dB,GSIR增益为1.23-1.94 dB。 未来的工作是将这些模型扩展到CNN和RNN,并将其应用于其他MIR问题,例如类型分类和音乐分割。