特征工程又包含了Data PreProcessing(数据预处理)、Feature Extraction(特征提取)、Feature Selection(特征选择)和Feature construction(特征构造)等子问题,而数据预处理又包括了数据清洗和特征预处理等子问题
假设一个数据集有多个特征,如果数据不进行归一化,在量纲(尺度)不同的情况下,会导致不能正确衡量样本中维度的重要程度,比如有个两个特征,一个是用年作为计算单位,一个特征是用天作为计算单位,但实际上用天计算的那个特征数值会大得多,如果没有进行归一化,会导致该特征站主导作用,会与实际不符。
归一化方法:
一般来说,常用的数据归一化有两种:
最值归一化(normalization): 把所有数据映射到0-1之间。最值归一化的使用范围是特征的分布具有明显边界的(分数0~100分、灰度0~255),受outlier的影响比较大
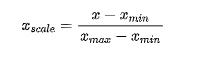
结果: 所有列的数据,都缩放到 0到1之间,且最大值是1,最小值是0
这个变换 保留了 这列中每个数 到最小值的差距的比例,
量纲大的给缩小了,量纲小的给扩大了 全都在0到1之间, 量纲严格相等
均值方差归一化(standardization): 把所有数据归一到均值为0方差为1的分布中。适用于数据中没有明显的边界,有可能存在极端数据值的情况(也称为标准化)
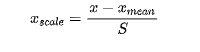
结果: 所有列的数据 均值为0 方差为1
这个变换,保留了每列原本的分布, 保留了每个数 距离均值的差距比例
所有数在 均值 为中心周围分布, 并且方差为1
对于不同列 最大值与最小值之间的差距 不一定是多少,
量纲大的列被缩小 量纲小的列被放大, 量纲不严格相等,只是比原来更接近 而且很接近了。
归一化和标准化的区别:归一化是将样本的特征值转换到同一量纲下把数据映射到[0,1]或者[-1, 1]区间内,仅由变量的极值决定,因区间放缩法是归一化的一种。标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,转换为标准正态分布,和整体样本分布相关,每个样本点都能对标准化产生影响。它们的相同点在于都能取消由于量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。
无量纲:我的理解就是通过某种方法能去掉实际过程中的单位,从而简化计算。
现实中,用归一化更多, 因为需要严格要求数据在0到1之间且量纲相等。
比如现在在深度学习中 cnn中的分类任务,都使用梯度下降BP反向传播算法更新参数,
在梯度下降中是为了逼近最优解,如果不同维度特征的量纲差距大,在超空间中,会形成超椭球的形状
梯度下降过程会反复震荡,如下:

当量纲完全一致,样本分布在空间是超正圆,梯度下降才最高效,如图:

归一化和标准化
相同点:
它们的相同点在于都能取消由于量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。
不同点:
目的不同,归一化是为了消除纲量压缩到[0,1]区间;
标准化只是调整特征整体的分布;
归一化与最大,最小值有关;
标准化与均值,标准差有关;
归一化输出在[0,1]之间;
标准化无限制。
2 但是不尽然! 有的时候真的需要使用标准化, 归一化效果不好。
比如 就预测零件是否合格的问题,
往往合格的零件,长度和半径 都在样本均值附近 才最好 才是合格的。
长度过短或者过长都不合格, 半径太大太小也都不合格。
我们需要保留样本距离均值的差距比例,
如果使用归一化,
我们只考虑样本到最小值的距离比例,最小值估计应该是个残次品,
我们丢失了最想要的 均值 周围的分布情况。
均值左侧的被缩放程度小, 均值右侧被缩放程度大!
3 总结一下:
有的人说,一般只用 标准化! 这个保留了样本原来的分布!!
有的人说, 一般只用 归一化! 这个梯度下降收敛效果好!!
如果样本噪声不大,污染不严重,对输出结果范围有要求,数据不存在异常值和极端值,用归一化 采用归一化比较好, 量纲缩放到严格相同, 计算距离的时候带来的影响是等价的。
如果 均值的信息是有意义的, 建议不实用归一化,实用标准化。 量纲不同但很接近, 不要丢失核心关键!!
归一化与标准化的应用场景
在分类、聚类算法中,需要使用距离来度量相似性的时候(如SVM、KNN)、或者使用PCA技术进行降维的时候,标准化(Z-score standardization)表现更好;
在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。
比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围;
基于树的方法不需要进行特征的归一化。
例如随机森林,bagging与boosting等方法。
如果是基于参数的模型或者基于距离的模型,因为需要对参数或者距离进行计算,都需要进行归一化。
一般来说,建议优先使用标准化。对于输出有要求时再尝试别的方法,如归一化或者更加复杂的方法。很多方法都可以将输出范围调整到[0, 1],如果我们对于数据的分布有假设的话,更加有效的方法是使用相对应的概率密度函数来转换。
数值型特征特征分箱(数据离散化)
将连续型特征转换成离散型特征
数据离散化的好处:
1.离散特征的增加或减少很容易,易于模型的快速迭代
2.稀疏向量内积乘法运算速度快,计算结果方便方便储存,容易扩展
3.离散化后的特征对异常数据有很强的鲁棒性(鲁棒性意味着不应受模型中存在的数据扰动、噪声以及离群点的太大影响)
4.对于线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于模型引入了非线性,能够提升模型表达能力,加大拟合;
5.离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
6.特征离散化后,模型会更稳定
7.特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险;(在离散化之前,如果某个特征权重较大,模型会很依赖这个特征,这个特征微小的变化会导致模型结果产生很大变化,也就是泛化能力差,容易过拟合,如离散化这个特征,一个权重变成多个权重,则影响力弱化,降低了过拟合的风险)
8.可以将缺失作为独立的一类带入模型
9.将所有变量变换到相似的尺度上
无监督分箱:
(1)自定义分箱:根据业务经验来设定划分区间
(2)等距分箱:按照相同宽度将数据分成几等份。
缺点是受到异常值也就是极值的影响比较大
(3)等频分箱
将数据分成几等份,每等份数据里面的个数是一样的。
区间的边界值要经过选择,使得每个区间包含大致相等的实例数量。比如说 N=10 ,每个区间应该包含大约10%的实例。
缺点:对于分布不均匀的样本,可能导致某个箱子的间距过大
(4)聚类分箱
定义
基于k均值聚类的分箱:k均值聚类法将观测值聚为k类,但在聚类过程中需要保证分箱的有序性:第一个分箱中所有观测值都要小于第二个分箱中的观测值,第二个分箱中所有观测值都要小于第三个分箱中的观测值,等等。
实现步骤
Step 0:
对预处理后的数据进行归一化处理;
Step 1:
将归一化处理过的数据,应用k-means聚类算法,划分为多个区间:
采用等距法设定k-means聚类算法的初始中心,得到聚类中心;
Step 2:
在得到聚类中心后将相邻的聚类中心的中点作为分类的划分点,将各个对象加入到距离最近的类中,从而将数据划分为多个区间;
Step 3:
重新计算每个聚类中心,然后重新划分数据,直到每个聚类中心不再变化,得到最终的聚类结果。
实现代码
from sklearn.cluster import KMeans
kmodel=KMeans(n_clusters=k) #k为聚成几类
kmodel.fit(data.reshape(len(data),1))) #训练模型
c=pd.DataFrame(kmodel.cluster_centers_) #求聚类中心
c=c.sort_values(by=’列索引’) #排序
w=pd.rolling_mean(c,2).iloc[1:] #用滑动窗口求均值的方法求相邻两项求中点,作为边界点
w=[0] +list(w[0] + [ data.max() ] #把首末边界点加上
d3= pd.cut(data,w,labels=range(k)) #cut函数
2.有监督分箱法
(1)KS-best分箱
Best-KS分箱的算法执行过程是一个逐步拆分的过程:
将特征值值进行从小到大的排序。
计算出KS最大的那个值,即为切点,记为D。然后把数据切分成两部分。
重复步骤2,进行递归,D左右的数据进一步切割。直到KS的箱体数达到我们的预设阈值即可。
缺点只能分两箱
2)卡方分箱法(可分多个箱子):
自底向上的(即基于合并的)数据离散化方法。它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。
基本思想
对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
实现步骤
Step 0:
预先定义一个卡方的阈值;
Step 1:
初始化;
根据要离散的属性对实例进行排序,每个实例属于一个区间;
Step 2:
合并区间;
计算每一对相邻区间的卡方值;
将卡方值最小的一对区间合并;
Aij:第i区间第j类的实例的数量;Eij:Aij的期望频率(=(Ni*Cj)/N),N是总样本数,Ni是第i组的样本数,Cj是第j类样本在全体中的比例;
阈值的意义
类别和属性独立时,有90%的可能性,计算得到的卡方值会小于4.6。大于阈值4.6的卡方值就说明属性和类不是相互独立的,不能合并。如果阈值选的大,区间合并就会进行很多次,离散后的区间数量少、区间大。
注意
ChiMerge算法推荐使用0.90、0.95、0.99置信度,最大区间数取10到15之间;
也可以不考虑卡方阈值,此时可以考虑最小区间数或者最大区间数。
指定区间数量的上限和下限,最多几个区间,最少几个区间;
对于类别型变量,需要分箱时需要按照某种方式进行排序。
特征预处理是数据预处理过程的重要步骤,是对数据的一个的标准的处理,几乎所有的数据处理过程都会涉及该步骤。
我们对特征进行分箱后,需要对分箱后的每组(箱)进行woe编码和IV值的计算,通过IV值进行变量筛选后,然后才能放进模型训练。
分箱后需要进行特征编码,如:
LabelEncode、OneHotEncode或LabelBinarizer等。
