吴恩达ML课程课后总结,以供复习、总结、温故知新,也欢迎诸位评论讨论分享,一起探讨一起进步:
上一篇:机器学习(5)--算法优化方法(学习曲线,误差分析)及特类分析(偏斜类问题召回率与查准率)https://blog.csdn.net/qq_36187544/article/details/88316728
下一篇:
支持向量机svm,广泛应用于工业界学术界,比逻辑回归,神经网络更加清晰明了,SVM会尽量找到全局最优,而神经网络可能会收敛到局部最优,SVM相对更加快,但是SVM不能处理大规模数据样本,速度将很慢。所以如果遇见特征数量大,但数据较少,向量机就较为合适
从逻辑回归到SVM,将损失函数改变为下图蓝线的内容,将得到更加简单易计算的函数(其实SVM思想和逻辑回归完全不一样,与逻辑回归对比,只是为了容易理解记忆)

下面是SVM的假设函数,与逻辑回归假设函数基本一致,C基本等价于1/λ,在逻辑回归中λ较大,在min计算时会惩罚正则化项的值,在SVM中,C较小,也等价于惩罚正则化项。C称为惩罚因子

在当前假设函数下,cost(θx)中θx的取值只能取大于1或小于-1(为了引出大间距)

svm被称作大间距分类器。C不是很大时能得到良好的边界,与逻辑回归类比。支持向量机的间距,具有鲁棒性(聚类结果不应受到模型中存在的数据扰动、噪声及离群点的太大影响。)


SVM数学原理:
内积:若v是一个向量,则vTv得到一个数值,称为内积,内积又等于投影距离×二范数
SVM的决策边界如下,相比之前的假设函数少了一大坨,因为那一大坨相当于一个常数。这个决策边界就相当于θ的范数(而且是二范数)的平方的1/2:
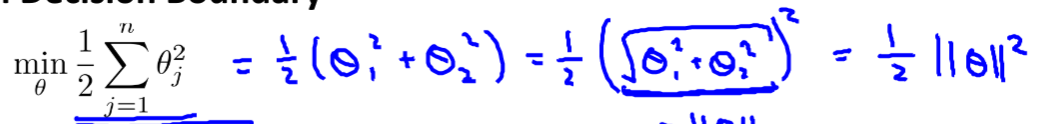
下图中绿色为决策边界,蓝色为参数向量。参数向量为什么与决策边界垂直?因为在θ0=0的简化情况下θx=0,即两向量垂直。
每个点到参数向量的投影距离P与二范数的乘积大于等于1或小于等于-1(内积计算),当p很小,则要求θ二范数很大,则很难的到最小化的目标函数。由于垂直导致svm总会找到最大的值保证θ最小,从而得到大间隔。

核函数:
若采用多项式作为核函数,多项式难以确定,这里提出常用的核函数:高斯核函数,除此之外还有多项式核函数,字符串核函数,卡方核函数,直方相交核函数等
e的...次方为高斯核函数如下图,x为不确定点,l1为某点,可发现,当l1与x接近时,相当于e的0次方等于1,当x与l1距离较远时相当于0,于是就做出了区分
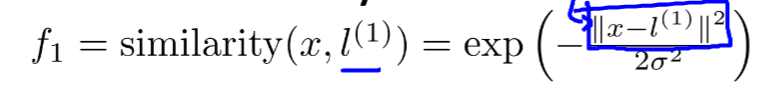
参数越大越平滑,参数的取用需要斟酌,σ^2越大,越平滑,高偏差低方差,小则高方差低偏差:

其实吴恩达老师在这一节中没有详细的解释相关的算法,只提出了SVM及理解,说如果采用SVM调用库函数就行了。看了下其他资料,SVM的目标是让θ二范数平方最小,然后归纳成数学问题,常用的算法有SMO,提出了拉格朗日对偶巴拉巴拉,涉及的数学知识较深,部分属于数值分析,这个就交给数学大牛吧,如果要使用SVM,调用函数库就行了,当然,别忘了特征缩放。