梯度提升树
现在站在大神的角度来回顾一下梯度提升树
正则化的目标函数
给定训练集D,含有n个样本m个特征
一个含有k棵树的集成模型
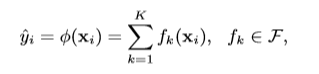
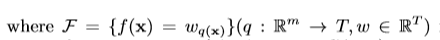
F当然就是回归决策树的空间啦。q是每棵树的结构,T是每个树的叶子数量。每棵树都有独立的树结构q以及叶子权重w。不同于决策树,每个回归树的叶子都包含了一个连续的分数,我们使用w同表示这个叶子的分数。举个例子来说,我们将使用给定树的决策规则来分类为叶子。那么最终的预测结果可以通过计算加总相对应叶子的分数来获取。
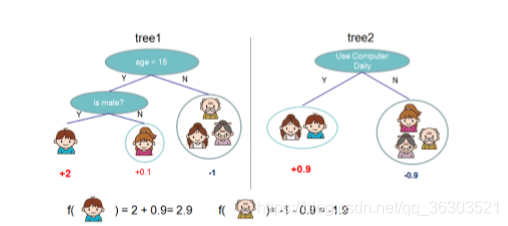
这个图在网上经常看到,但是很少人能够解释得清楚。应该这样理解,对于每个样本来说,依次放入不同的回归树中,看它最后落入哪个叶子里面。对每个的回归树中的对应叶子的分数进行加总最后得到的结果就是整个函数对应的预测。那为什么在这个图中,第一棵树是2呢,因为这个是加法模型,第一模型通常预测的分数比较大。
为了学到每个回归树模型,使用下面这个目标函数。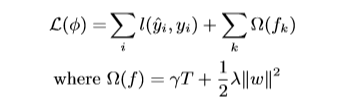
很自然,目标函数=损失函数+正则项
原文说,正则项是用来平滑最终的叶子权重的以此避免过拟合。直观上,正则化目标倾向于选择一个使用简单的具有预测性的函数的模型。RGF已经在使用一个简单的正则化技术了。本文使用的目标函数以及相对应的算法比RGF更简单以及易于并行化。当正则化参数为零,那么目标函数退化为梯度提升树。
梯度提升树
用下面的公式来表示第i个样本的第t次迭代,现在我们需要添加一个树函数来最小化下面的目标函数:
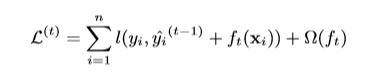
这意味着我们将选择的是我们模型优化最大的树函数。二阶近似可用于在一般情况下快速优化目标。所以将损失函数泰勒展开。
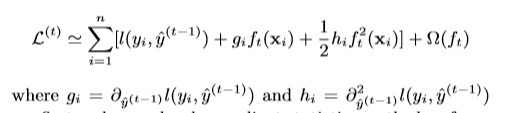
注:泰勒展开公式如下:

显然x=前面预测结构+树函数,y=损失函数
在原点处展开,那么f()=0。
把常数项去掉,因为常数项不能提供关于梯度的信息,每次求导后等于零。
定义一个集合,叶子j的样本集合。即在
所有在叶子j中的样本的集合。
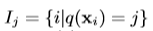 重写目标函数得
重写目标函数得
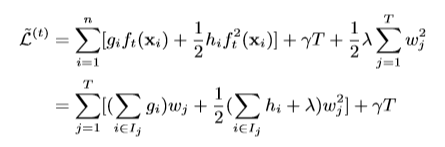
这一步是怎么来的呢?本来是按照样样本来讲故事,现在拆开树函数,对其每个叶子来计算。那么还记得上文的
带入到目标函数里面,按照叶子展开。
如何找到这个树结构暂时不说,现在可以计算叶子j的权重
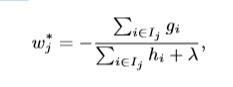
同样可以计算优化后的目标函数值
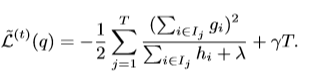
这个等式显然可以衡量某树函数结构的分数。就像决策树中的不纯率。
作者用图片来解释这个计算的过程。
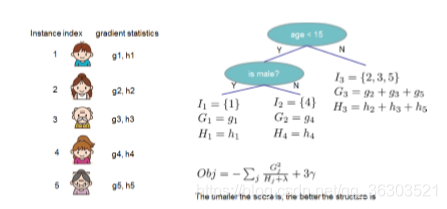
当然得分越少,树的结构越好。
当然我们不可能计算所有可能的树结构,我们需要使用一个贪心算法。给定一个叶子,然后不断加入分支到树里面。假定IL和IR是分裂后的各自包含的样本集合。I=IL+IR。
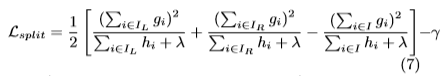
显然两个obj相减即可,注意分裂后T叶子个数+1。
shrinkage 和 列采样
除了正则化,在GBDT基础上还由采用了两个新技术,shrinkage和列采样。下面逐个介绍。
每增加一步树木后,收缩量按系数η计算新增加的权重。与随机优化中的学习率相似,shrinkage减少了每个单独的树和叶子空间对整体模型的影响。第二个就是对列进行采样(特征采样)。当然这就和随机森林一样。根据用户的反应,列采样甚至比行采样更有效地避免过拟合。当然还有一个好处是,列采样容易进行并行处理。
分裂算法
基础算法
一个关键的问题是怎么找到最好的分裂方式。
一个可能的算法就是列举所有存在特征。这个叫极度贪心算法。很多实现都支持这个算法,比如scikit learn,R。计算上需要为连续的特征列举所有可能的分割。为了有效地实现这一点,算法必须首先根据特征值对数据进行排序,并按排序顺序访问数据,以积累结构分数的梯度统计信息。这个梯度分数就是公式7咯。77777777777777777777
近似算法
极度贪心算法是很有效。但是当数据非常大的时候这个算法是不可能高效地实现。
作者总结出来了一个近似的框架。简单来说,这个算法提出应该根据特征分数分布的百分比来划分分裂点。然后将特征映射到上述划分好的桶里面。汇总统计数据,并根据汇总的分数确定所有可能中的最佳解决方案。
这个算法伪代码如下:

The global variant proposes all the candidate splits during the
initial phase of tree construction, and uses the same proposals for
split finding at all levels. The local variant re-proposes after each
split.
这个算法暂时没有搞懂。
讲完这个算法,作者说也可以用其他分箱的办法来代替百分比。百分比的优势在于分布和重复计算。
作者说近似算法可以非常靠近极度贪婪算法但是可以根据自己实际情况来选择。
加权分位数
一个关键步骤是计算候选的分裂点。通常一个特征的百分比是平均用作候选点分布。正式地,让数据集D代表每个训练样本第k个特征的值,以及二阶的梯度的统计量。
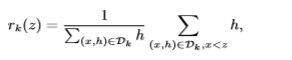
这个呢,代表样本特征k小于z的比例。我们的目标是找到一系列的分裂点,满足:
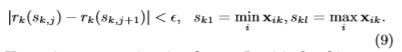
不直观地说,这个表示这里大概有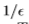
个候选点。在这里每个数据点都被hi加权。为了方便观察hi是如何代表权重的,我们可以重写目标函数。
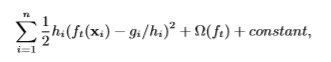
对于大型数据集,查找满足条件的候选分割是非常重要的。虽然已经有了分位数算法,但是没有针对weighted datasets的算法。所以作者提出了新的算法来搞定这个问题。
sparsity-aware Split Finding
这个功能是作者开发出来应对稀疏数据的。
注:什么叫稀疏数据,大概就是一堆零里面只有几个一。通常见于分类数据中,经过one hot encoding之后经常会形成稀疏数据。
这里有几个可能的原因导致的稀疏:
- presence of missing values in the data;
- frequent zero entries in the statistics;
- artifacts of feature engineering such as one-hot encoding.
作者说让算法感知到数据中存在稀疏情况的。为了实现这个想法,作者建议 加入一个默认的方向在每个节点中,如图所示。
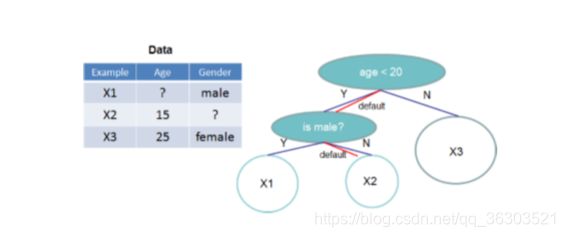
然后这个默认的方向呢是学自数据的。一个关键的改进在于只查询非零的叶子样本集合。作者也做了图表来展示这个算法的高效之处。伪代码:

那么论文的讲解就结束了。
回过头来,可能第一次读对CART树不了解,在这里再讲解一遍。
CART叫classification and regression tree
就是既可以回归又可以分类的树,也是一个二叉树。
分类和回归有什么区别呢?分类要悬着gini值作为结点分裂的依据,回归要选择最小方差做分裂依据。
sklearn 参数讲解
以回归为例讲解其参数:
max_depth: 树的最大深度,过拟合的,降方差,根据样本大小取4-6
learning_rate:学习率,一般取0.05,降偏差
n_estimators: 树的个数,和树的深度搭配使用,树深就少点,树浅就多点
objective:目标函数
booster:一般来说用gbtree
n_jobs: 并行数,一般不限制=-1
gamma:最小的损失函数减少值,如果低于这个值那么就不分裂,降过拟合的。
min_child_weigh: 叶子能够含有的最少样本数,同样是剪枝,降过拟合的。
max_delta_step: shrinkage的最大值
subsample: 行采样比例,0.8
colsample_bytree:列采样构造树的时候,0.8比较好
colsample_bylevel:每次分裂时的列采样,0.8
reg_alpha: L1正则化
reg_lambda:L2正则化
scale_pos_weight: 平衡正负样本的比例,这个可以根据自己样本需要来写。
random_state: 用来复现的
missing:missing值的代表是什么,默认np.nan
importance_type:不同类型的特征重要度分析