1.XGB的直观理解
XGB就是一堆CART树的结果的加和
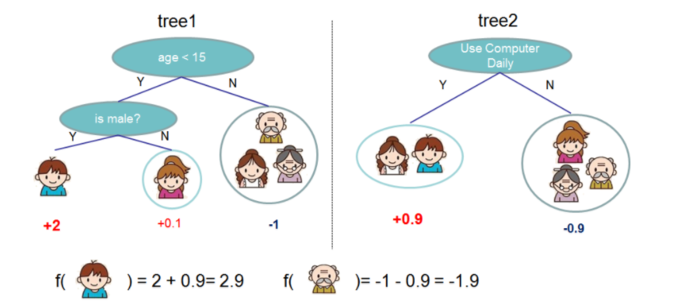
xgb就是将每棵树的预测值加到一起作为最终的预测值
- 模型表示
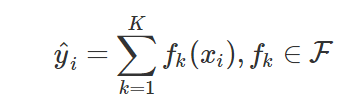
K为树的个数
F为所有可能的CART树
f为一颗具体的CART树 - 目标函数

问题来了,一棵树的正则化项是怎们表示的?先想想,后面有详解 - 改进:不再是直接优化整个目标函数,而是分步骤优化目标函数
首先优化第一棵树,完了之后再优化第二棵树,直至优化完K棵树
2.加法模型
- 分步骤优化目标函数
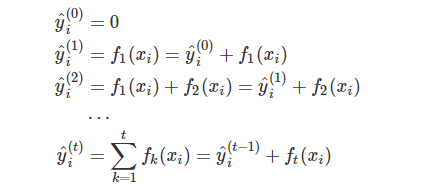
首先优化第一棵树,完了之后再优化第二棵树,直至优化完K棵树 - 第t步时,添加一个最优的CART树ft(x),在现有的t-1棵树的基础上,时的目标阿寒湖最小的那棵CART树
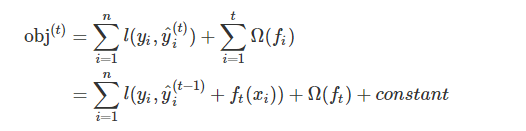
obj代表衡量一棵树好坏的目标函数 - 假如我们使用的损失函数时MSE,那么上述表达式会变成这个样子
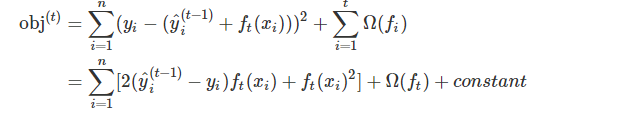
- 对于一般的损失函数,对其作泰勒二街展开
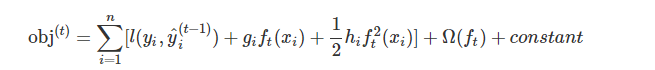
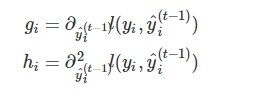
- 去掉所有的常数项,目标函数变为

3.模型正则化项
- CART树
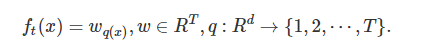
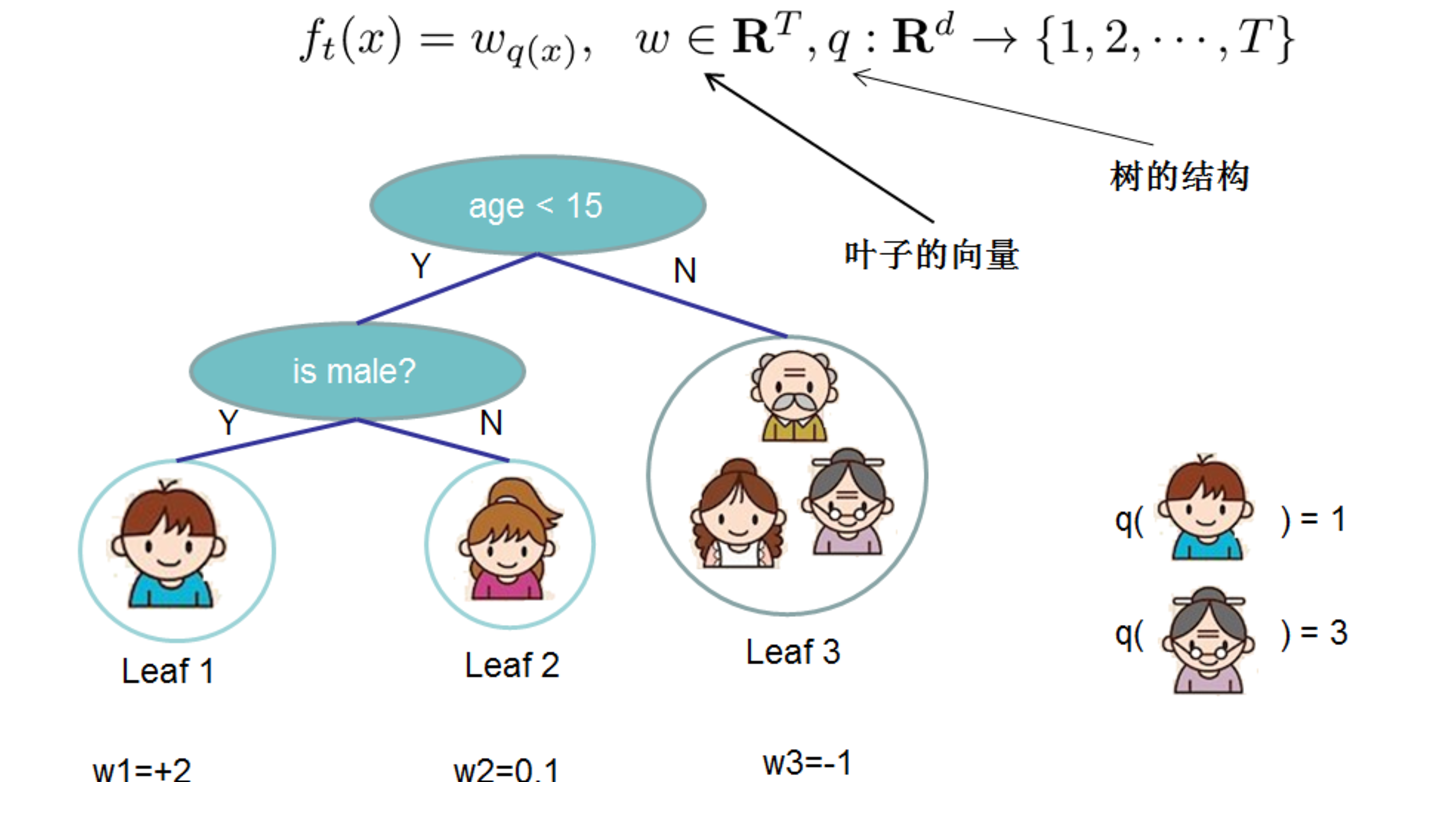
把树拆分成结构函数q(输入x,输出叶子节点的索引)和叶子权重w(输入叶子节点索引,输出叶子节点的分数).
结构函数q是把输入映射到叶子的索引号上去,而w给点了每个索引号对应的叶子分数 - 正则化项

γ越大,表示越希望获得结构简单的树,因为此时对较多叶子节点的树的惩罚越大。λ越大也是越希望获得结构简单的树。
4. 最终的目标函数
- 对上式变形

Ij代表什么?代表每个叶子节点上的样本集合Ij = {i|q(xi)=ji} - 令,Gj,Hj
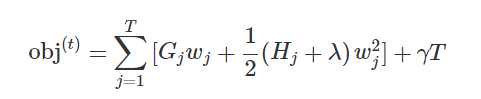
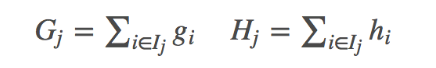
Gj为每个叶子节点里面的一阶梯度的和,Hj为每个叶子节点的二阶梯度和 - 可知,上式为二次项函数,可以求导获得最优的w*和obj*
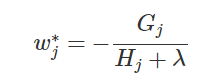

- wj*的解释。假设这个叶子节点上的样本只有一个时,wj*变为

wj*的最佳值为负的梯度诚意一个权重系数,类似于SGD中的学习率。hj越大,这个系数越小,也就是学习率越小。 - obj也可以叫做结构分数,衡量树的结构好坏
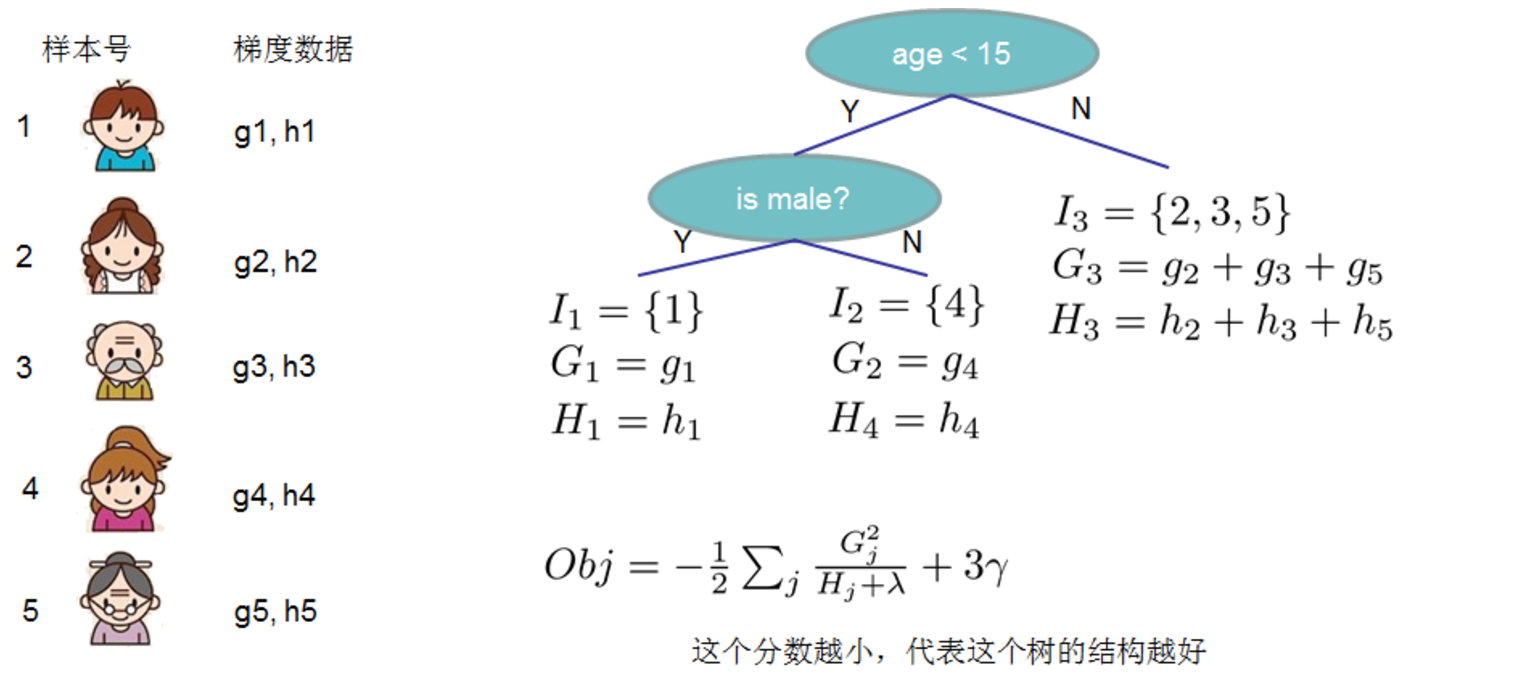
5. 如何寻找出一个最优结构
- 枚举所有不同树结构的贪心法
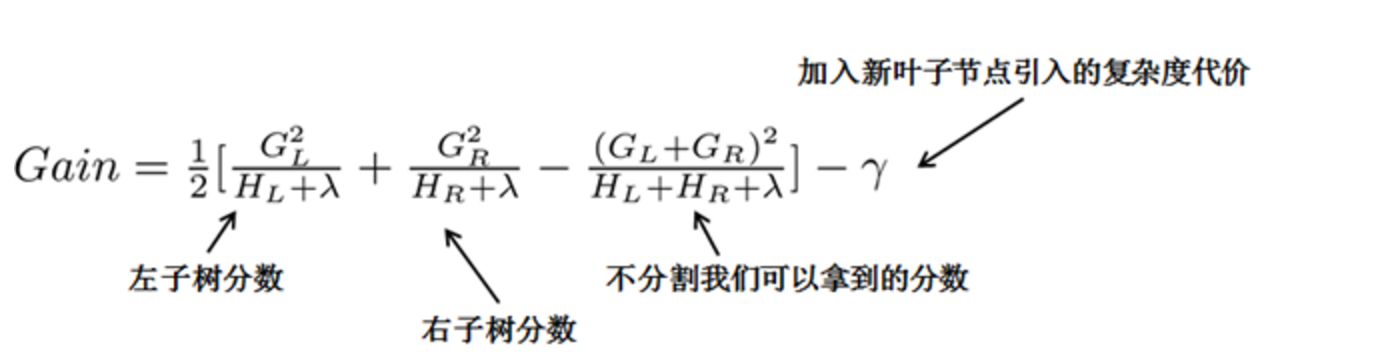
利用这个打分函数来寻找出一个最优结构的树,加入到我们的模型中,再重复这样的操作。
常用的方法是贪心法,每一次尝试去对已有的叶子加入一个分割。对于一个具体的分割方案,计算增益 - 划分点查找算法
- 贪心算法

- 近似算法

- 贪心算法
6. 应用实例——加入自定义的目标函数和评估函数
#!/usr/bin/python
import numpy as np
import xgboost as xgb
###
# 定制损失函数
print ('开始运行示例,使用自定义的目标函数')
dtrain = xgb.DMatrix('../data/agaricus.txt.train')
dtest = xgb.DMatrix('../data/agaricus.txt.test')
param = {'max_depth': 2, 'eta': 1, 'silent': 1}
watchlist = [(dtest, 'eval'), (dtrain, 'train')]
num_round = 2
# 用户定义目标函数,给出预测,返回梯度和二阶梯度
def logregobj(preds, dtrain):
labels = dtrain.get_label()
preds = 1.0 / (1.0 + np.exp(-preds))
grad = preds - labels
hess = preds * (1.0-preds)
return grad, hess
# 用户定义的评估函数,返回一个对指标名称和结果
# 当你做定制的损失函数,默认的预测价值可能使评价指标不正常工作,所以要自定义评估函数
def evalerror(preds, dtrain):
labels = dtrain.get_label()
return 'error', float(sum(labels != (preds > 0.0))) / len(labels)
# 训练定制的目标
bst = xgb.train(param, dtrain, num_round, watchlist, logregobj, evalerror)7. 参数的含义
7.1 通用参数
- booster
- gbtree基于树模型的提升算法(default)
- gblinear基于线性模型的提升算法
- silent
是否输出详细信息,默认为0 - nthread线程数,默认最大
7.2 Tree Booster参数
- eta (default=0.3):学习率的shrinkage参数
避免步长过大。把eta设置的小一些,可以使得后面的学习更加仔细 - min_child_weight:每个叶子节点的h的和至少为多少 -- default=1
假设 h 在 0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100 个样本。
这个参数的值越小,越容易过拟合 - max_depth :每棵树的最大深度 -- default=6
树越深,越容易过拟合 - gamma:在树的叶子节点上进一步分割时所需的最小的损失降。
gamma越大,算法越保守 - subsample:样本随机采样 -- default=1
越小的值,时的算法越保守,防止过拟合。过小的话,会导致欠拟合 - colsample:列采样,对每棵树的生成用的特征进行类采样 -- default==1
借鉴了RandomForest中的属性采样。(0.5,1) - lambda 控制模型复杂度的权重值的L2正则化项参数 -- default = 1
,参数越大,模型越简单,越不容易过拟合 - alpha控制模型复杂度的权重值的L1正则化项参数 -- default = 0
,参数越大,模型越简单,越不容易过拟合 - scale_pos_weight 如果取大于0的话,在类别样本不平衡的情况下,有助于快速收敛
- tree_method 可选择{'auto','exact','approx'}
exact贪心算法适用于小数据集
approx近似算法适用于大数据集
7.3 学习任务参数
- objective [ default=reg:linear ]定义最小化损失函数类型
- 最常用的值有:
- binary:logistic 二分类的逻辑回归,返回预测的概率(不是类别)。
- multi:softmax 使用softmax的多分类器,返回预测的类别(不是概率)。
在这种情况下,你还需要多设一个参数:num_class(类别数目)。 - multi:softprob 和multi:softmax参数一样,但是返回的是每个数据属于各个类别的概率。
- 最常用的值有:
- seed 随机种子 -- default=0
- eval_matric对于有效数据的度量方法
- 回归
- rmse -- default
- mae
- 分类
- logloss负对数似然函数值
- error 二分类错误率(阈值为0.5)
- merror 多分类错误率
- mlogloss 多分类logloss损失函数
- auc曲线下面积
- 回归
8. GBDT与XGBoost的区别
- 正则化项:定义了树的复杂度
正则化项中包含了树的叶子节点个数,每个叶子节点的分数的L2的平方和,代替了剪枝 - 目标函数通过二阶泰勒展开做近似。
XGB中同时用了一阶导数和二阶导数。
GBDT中只用了一阶导数的信息。
XGB支持自定义目标函数,只要一阶和二阶可导