XGBoost介绍
在上一篇构造决策树的博客中说到,XGBoost是一种通过集成的思想提高模型准确率的算法,这种算法是基于决策树模型的。不懂的可以看下面地址,包含了决策树的介绍和构造。
https://blog.csdn.net/weixin_43172660/article/details/82995442
下面通过一个具体的例子来说明XGBoost干了一件什么样的事情。
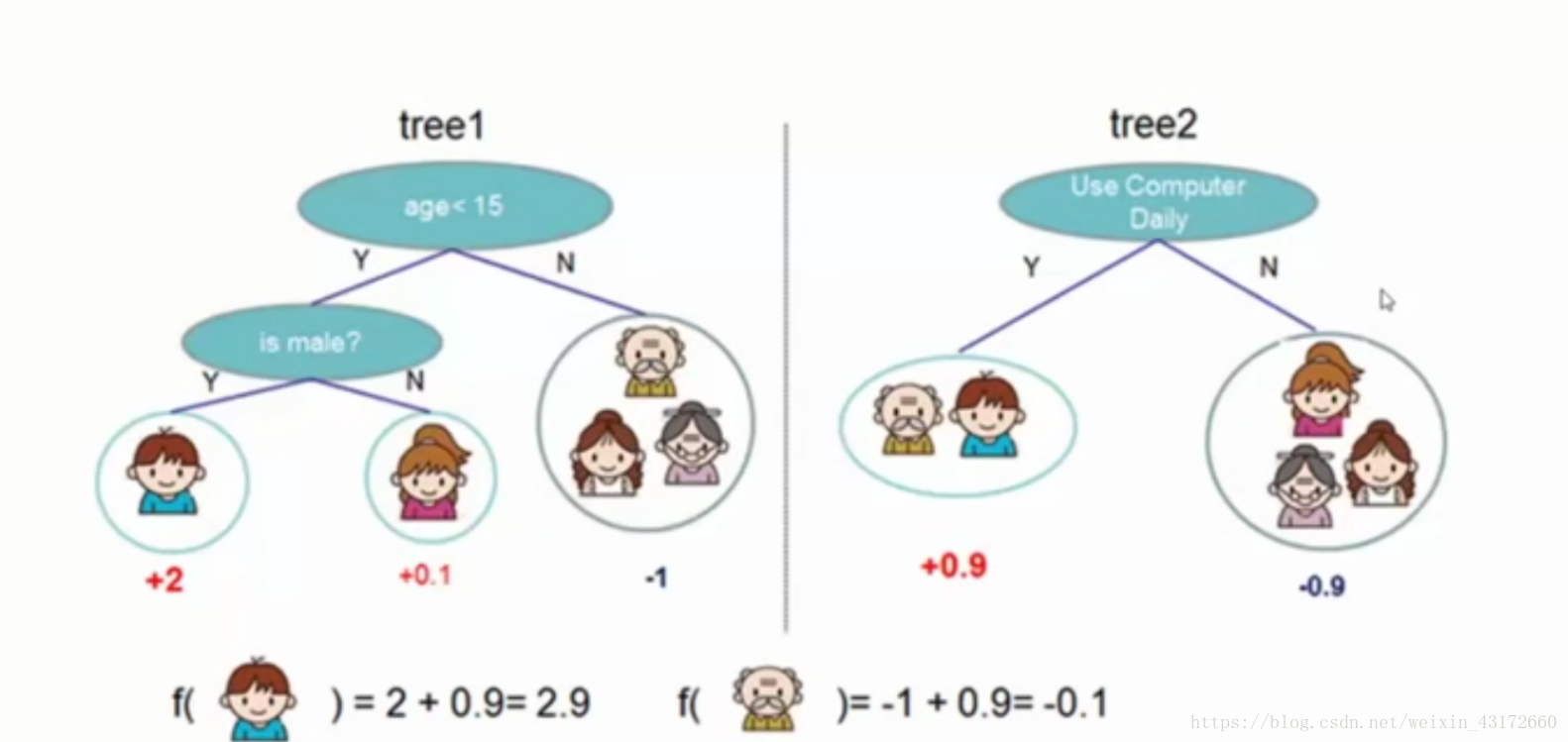
如果要判断是否打电子游戏,我们可以通过很多特征来判定,左边这颗树,通过年龄和性别来判定,最后每个叶子节点都有一个得分值(权重值),正数代表对结果有好的影响 ,负数代表对结果有负面影响 ,得分值越高越好,右边的树,通过不同的特征,最后也得到了不同的得分值(权重值)。
XGBoost说的就是,对于男孩来说,通过这两棵树,他是否打电子游戏的得分值就为2 + 0.9 =2.9,对于老人来说,他的得分值为-1 + 0.9 =-0.1 ,这就是集成的思想。
XGBoost推导
将上面集成学习方法推广到一般情况,可知其预测模型为:
其中为K树的总个数,fk表示第颗树,yi表示样本xi的预测结果。
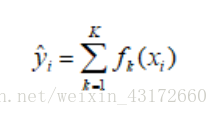
我们定义一个损失函数:
那么现在,我们就可以得到目标函数:预测值和真实值的平方项的差异(n代表一共有n个样本)。
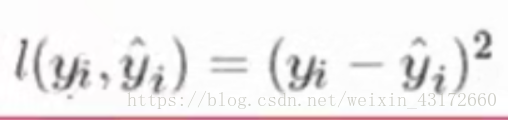
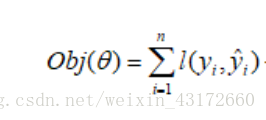
我们上面通过举一个例子,知道了XGBoost是怎样的一个工作原理,就是不断加入新的决策树,使模型越好越好,下个这个图就说明了 这个过程。(小括号的值代表一共有几棵树)
那是不是随便加入一棵树都可以呢,不是这样的,XGBoost是一种提升算法,意思是当你加入一颗新的树之后,整体表达效果要提升,那么怎样才能表示整体表达效果提高呢,我们上面得到了目标函数,所以我们要做这样一件事(XGBoost的核心):加入一棵树,使我们的目标函数下降

我们先来说另外一个事情,当我们决定要用决策树做集成算法的时候,我们要加入惩罚项。
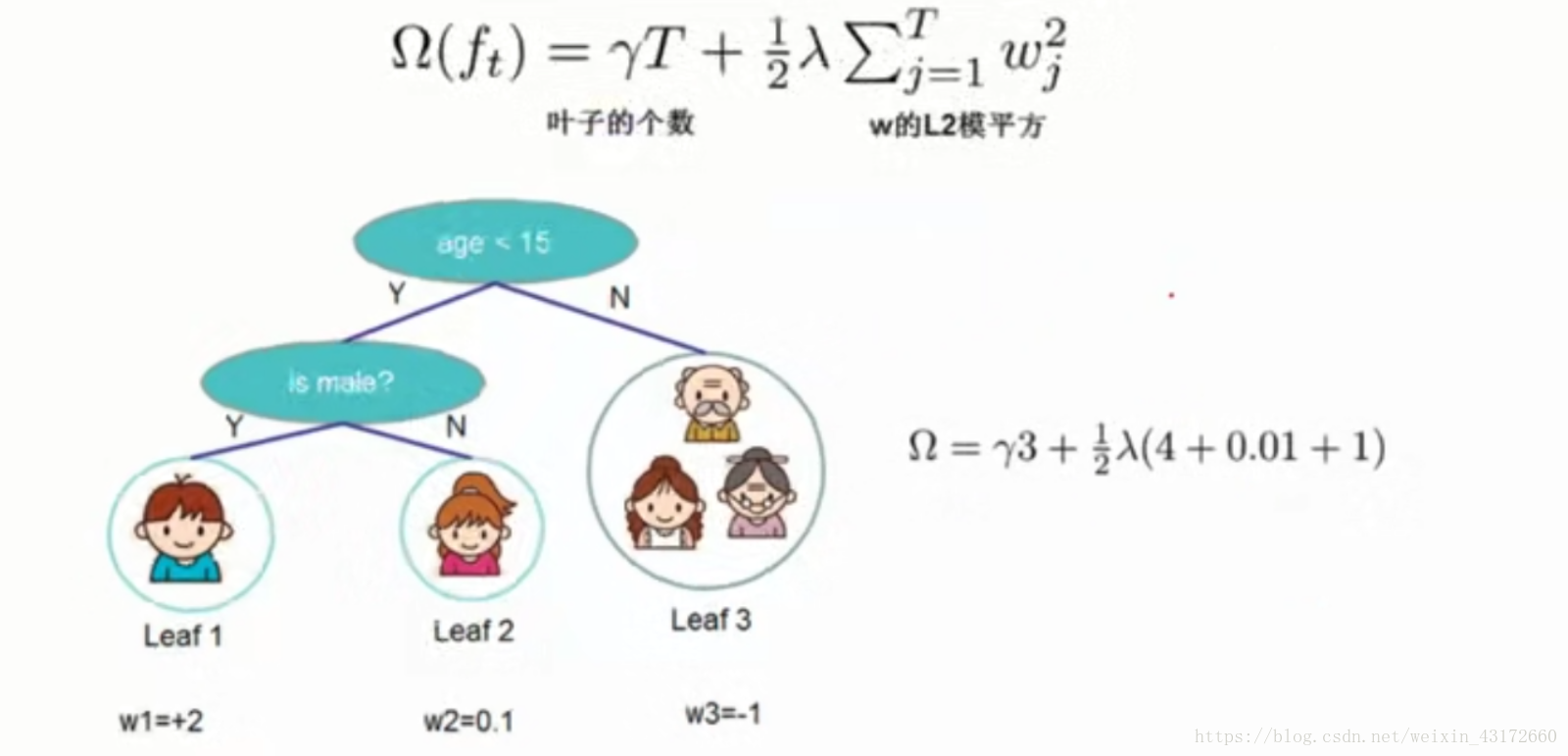
惩罚项
如下图,这个惩罚项加号左边表示当决策树的叶子过多的时候,惩罚力度越大,因为叶子节点过多,容易造成过拟合,加号右边是w的L2模平方,两个组合起来就说我们的惩罚项了。
现在,我们目标函数变成了下面这个样子,第一行的式子表示,一共加入了t颗树,一共有t个惩罚项,下面的式子则是将括号里面变成我们上面求的通式,constant是常数项,所以现在的目标就是,找出一个f(t)使得目标函数最小。
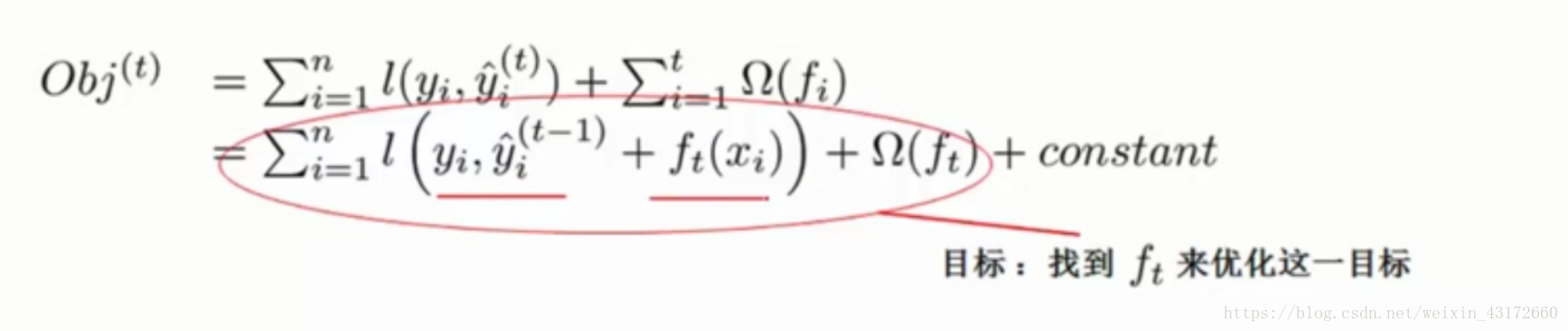
泰勒公式
我们要求解上面的目标函数,需要引入一个东西————泰勒展开公式
我们可以把目标函数l函数中的式子看成这样:
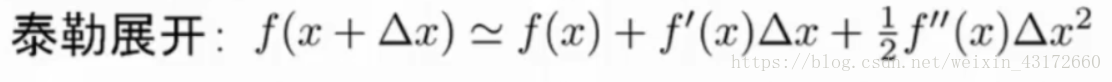
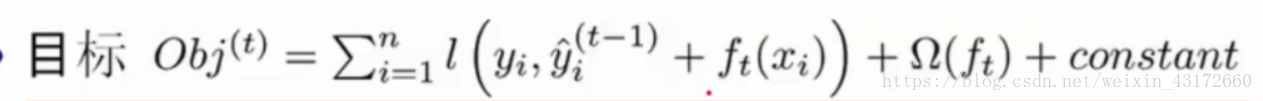
为了方便计算,我们需要定义两个东西(gi为f(x)的一阶导,hi为f(x)的二阶导):
然后根据泰勒展开公式,转化为:
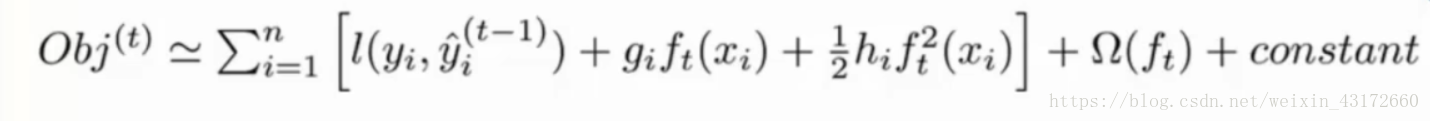
因为后面要进行求导,所以我们把常树项去掉,所以目标函数变成了:
我们需要进一步对目标函数进行化简,我们要明白一个东西,对于第t颗加入的树来说,w为叶子节点的得分值,q(x)表示样本x对应的叶子节点,T为该树的叶子节点个数。
所以,对于我们的目标函数可以进一步简化,我们之前是在样本上遍历,因为所有样本都是会落到叶子节点上,所以我们可以转化思路,换成在叶子节点上遍历。
在叶子节点上遍历的时候,T表示第t棵树的叶子节点的个数,i表示在第j个节点中的第i个样本,wj表示第j个叶子节点的得分值。
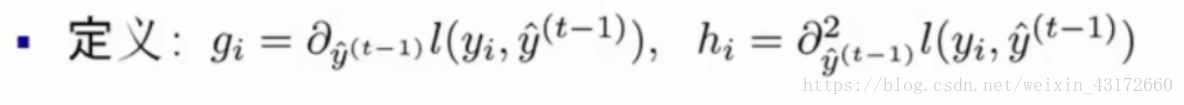
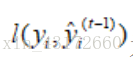
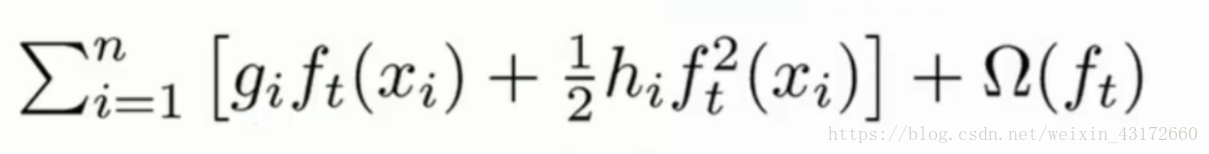
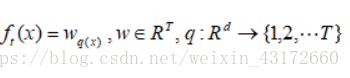

接下来,为了简洁一点,我们继续定义两个东西,Gj和Hj:
现在,目标函数变成了:
前面说过,我们要求的是目标函数的最小值,所以,现在我们需要在目标函数对w求导,让其等于0,
可以求得得分值w:
可能有人说这个G和H怎么求,因为g和h是导数,我们只要定义了损失函数,就能求得G和H的值。
再把w代回原函数,可以得到:
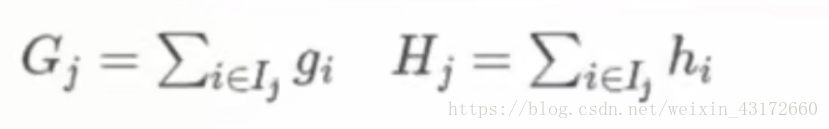
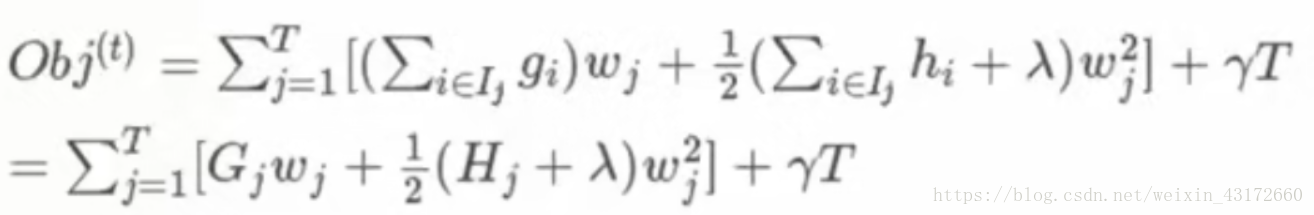
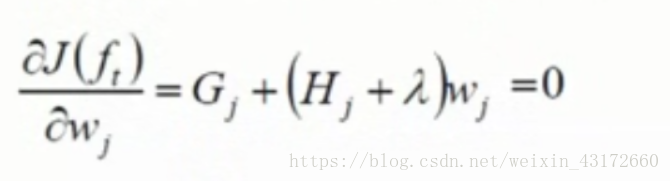
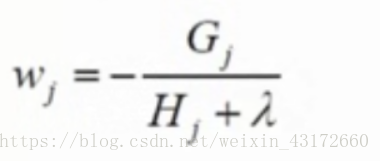
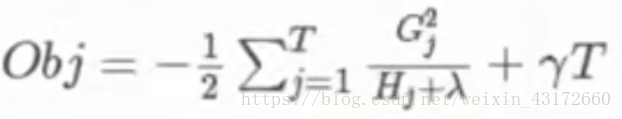
XGBoost怎么切割决策树
结构分数
推过XGBoost的求导,我们可以计算出Obj,代表了当我们指定一个树的结构的时候,我们在目标上面最多减少多少,我们可以把它叫做结构分数,我们可以认为这个类似于Gini系数一样,可以对树结构进行打分的函数。
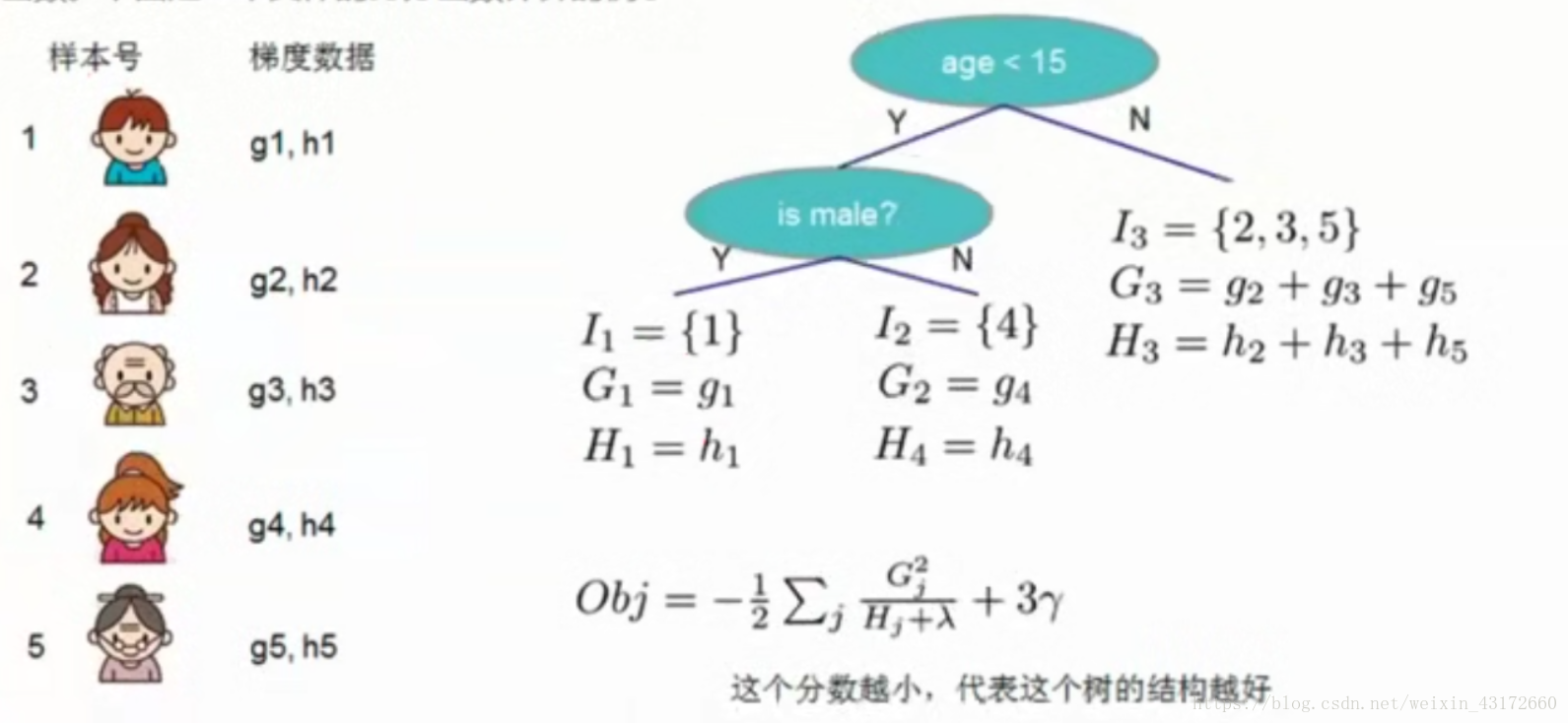
下面具一个具体打分的例子如图,
叶子节点I1有1个样本,I2有1个样本,I3有3个样本。
对于I1节点来说,G1=g1,H1=h1,
对于I2节点来说,G2=g4,H2=h4,
对于l3节点来说,G3=g2+g3+g5,H3=h2+h3+h5,
我们可以求出目标函数Obj,这个分数越小,代表这个树的结构越好。
那么问题来了,我们怎么切割决策呢,我们之前在决策树,是通过看信息增益,切哪里信息增益大的就往哪里切,在XGBoost,我们可以自己构造一个系数,来决定怎么切 。
上面就是我们系数的表达式,讲的是通过切割之后,算左右子树的分数之和,减去不分割之前的分数,我们需要枚举所有的分割可能,举Gain值最小的那个分割办法,用这种方法将我们的树构造完成。

总结
XGBoost是一种高效的算法,可用于提升模型的准确性,将XGBoost的学习分为三步:
- 集成思想
- 损失函数的分析
- 新加入树的分割