Coursera: Introduction to Data Science in Python Week3
Merging
合并表的操作类似于SQL中的表连接,就是把两张表格按照某一列的值进行匹配然后进行列的拼接,连接之后,表格会变胖(列数会增加)。
# 首先导入包和基本数据
import pandas as pd
staff_df = pd.DataFrame([{'Name': 'Kelly', 'Role': 'Director of HR'},
{'Name': 'Sally', 'Role': 'Course liasion'},
{'Name': 'James', 'Role': 'Grader'}])
staff_df = staff_df.set_index('Name')
student_df = pd.DataFrame([{'Name': 'James', 'School': 'Business'},
{'Name': 'Mike', 'School': 'Law'},
{'Name': 'Sally', 'School': 'Engineering'}])
student_df = student_df.set_index('Name')
pd.merge(staff_df, student_df, how='outer', left_index=True, right_index=True)
# 第一种调用是从pd.merge()进行模块调用
# 传递的参数中,前面两个是数据框的名称,how = ‘outer’/'inner'/'left'/'right'分别表示连接的方式 default 为‘inner’
# left_index = True表示按照指定左边表格的index为外键。
# 如果不传入left_index = True,需要传入left_on = columnName来指定用来连接的外键
# right_index = True是同样的道理
# 如果不传入righr_index = True,需要传入right_on = columnName来指定用来连接的外键
# 指定的外键在两张表中有相同的名字那么可以只用 on = columnName来传递指定连接的外键
另外一种调用模式是通过DataFrame.merge()这个时候只需要传递一个DataFrame作为所谓的right dataframe,其他参数与上面描述的类似。
Tricks
method chain
# 首先还是导入包
import pandas as pd
df = pd.read_csv('census.csv')
df
技术员们都推荐是用下面这种模式写代码:
# 可读性强 优美的代码风格 使用 dot+method
(df.where(df['SUMLEV']==50)
.dropna()
.set_index(['STNAME','CTYNAME'])
.rename(columns={'ESTIMATESBASE2010': 'Estimates Base 2010'}))
# 务必注意一定要加上最外层的括号。
而不是下面这种:
# 初级玩家的代码风格 比如我
df = df[df['SUMLEV']==50]
df.set_index(['STNAME','CTYNAME'], inplace=True)
df.rename(columns={'ESTIMATESBASE2010': 'Estimates Base 2010'})
apply
有时候会遇到对行进行迭代的计算时计算方式比较复杂或者涉及到多列,参考Week 2作业的第6、7题。这个时候用apply这个方法会方便很多。
import numpy as np
def min_max(row):
data = row[['POPESTIMATE2010',
'POPESTIMATE2011',
'POPESTIMATE2012',
'POPESTIMATE2013',
'POPESTIMATE2014',
'POPESTIMATE2015']]
row['max'] = np.max(data)
row['min'] = np.min(data)
return row
df.apply(min_max, axis=1)
这里DataFrame.apply(min_max,axis = 1)让DataFrame中每一行(axis = 1)都执行min_max函数。
Group by
DataFrame.groupby('columnName')按照columnName对数据框的observation进行分组,可以搭配size(), agg()等函数搭配使用,详见另一篇博客。在这里,老师补充了另外两种用法,
df = df.set_index('STNAME')
def fun(item): # 注意这里是item[0]
if item[0]<'M':
return 0
if item[0]<'Q':
return 1
return 2
for group, frame in df.groupby(fun):
print('There are ' + str(len(frame)) + ' records in group ' + str(group) + ' for processing.')
直接把函数名传入groupby()中,这会得到按照对index的不同函数结果进行分组。
直接传入level = 0,直接对index进行分组
Scales
Scales说的是数据类型。这个数据类型不同于我们说的变量类型。这个数据类型是由数据本身的含义和性质所决定的。
- Ratio scale 表示绝对的尺度,比如身高,0kg就是0kg,10kg - 0kg = 20kg - 10kg
- Interval scale 表示相对尺度,比如温度,没有绝对的0度?,但是10度 - 0度 = 20度 - 10度
这个老师讲的例子可能不太好。换一个,就拿坐标轴上的点来说,原点的位置始终是相对的概念,我们可以认为设定一个原点。Interval scale和Ratio scale的区别在于Interval scale没有一个绝对的起点。 - Ordinal scale 排序数据,表示分类但是有优先级,比如白金会员,黄金会员和普通会员
- Nominal scale 分类数据,表示分类没有优先级,比如体育项目
Pivot_table
类比Excel中的pivot table:
pivot_table(values = , index = , columns = , aggfunc = )
index表示row的分类,columns表示column的分类,aggfunc就是对值进行分类计算的方程了。
df.dropna().pivot_table(values='(kW)', index='YEAR', columns='Make', aggfunc=np.mean)
# 注意这里的方程名称不需要用单引号
Datetime
讲了Pandas包中间的几个时间类别。
Timestamp
import pandas as pd
pd.Timestamp('9/1/2016 10:05AM')
# 返回一个Datetime类型
返回结果:
Timestamp('2016-09-01 10:05:00')
Period
pd.Period('1/2016'), pd.Period('3/5/2016')
返回Period类型:
(Period('2016-01', 'M'), Period('2016-03-05', 'D'))
Period类型有一个frequence的属性。这个属性可以在声明的时候指定:
pd.Period('3/5/2016',freq = 'M')。
as index
Datetime和Period都可以当成DataFrame的Index。当index是Datetime或者是Period的时候,对我们的索引非常有帮助。
dates = pd.date_range('10-01-2016', periods=9, freq='2W-SUN')
df = pd.DataFrame({'Count 1': 100 + np.random.randint(-5, 10, 9).cumsum(),
'Count 2': 120 + np.random.randint(-5, 10, 9)}, index=dates)
# 使用pd.date_range() 快速生成一个数据序列 periods为9 freq为每隔两周的周日
df.resample('M').mean()
# 可以得到按照每月自动分组计算的的均值
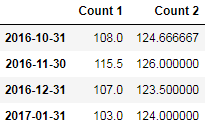
df['2017'] # 按照年度索引会得到对应年份的结果
df['2016-12'] # 按照月度索引会得到对应月份内的结果
df.asfreq('W', method='ffill') #改变频率重新填充结果