Coursera: Introduction to Data Science in Python Week 2
主要介绍pandas中的两个数据类型Series,DataFrame以及它们的生成,索引,删除和缺失值的处理。Series和DataFrame是pandas中两个最重要的核心数据类型。
Series
Series 指的是数据序列。可以理解成为比较像字典的一个结构。Series有两个部分:索引和值。这可以对应到字典中的键值和值。不同的是Series中的值具有相同的数据类型,而且不要求索引值是唯一的。
生成
一般有列表生成和字典生成这两种方法来生成Series对象,所用到的方法是Pandas包中的pandas.Series。
- 列表生成
animals = ['Tiger', 'Bear', 'Moose']
pd.Series(animals)
下图是输出结果:

生成的对象为Series,因为列表中的元素为字符串,其属性dtype的值为object。
numbers = [1, 2, 3]
pd.Series(numbers)
下图是输出结果:
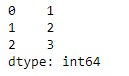
列表中的元素为整数,Series中dtype属性值为int64。在没有指定index的情况下,index默认为自然数序列:从0开始到数组的长度减1。输出结果中最左端的数值序列就是默认的index。
- 字典生成
可以在pd.Series(Dict)直接加进字典值。
sports = {'Archery': 'Bhutan',
'Golf': 'Scotland',
'Sumo': 'Japan',
'Taekwondo': 'South Korea'}
s = pd.Series(sports)
s
输出的结果如图:

这里会把字典中的键值当做是对应的索引值。
- index指定
我们可以在pd.Series()方法中指定index。
在使用列表生成时:
s = pd.Series(['Tiger', 'Bear', 'Moose'], index=['India', 'America', 'Canada'])
s
这样创建出来Series的结果中,index和值是按顺序对应的:

在使用字典生成时候:
sports = {'Archery': 'Bhutan',
'Golf': 'Scotland',
'Sumo': 'Japan',
'Taekwondo': 'South Korea'}
s = pd.Series(sports, index=['Golf', 'Sumo', 'Hockey'])
s
这里涉及到匹配的问题,当index的值和字典中的键值匹配时,字典中的值才会在Series中,如‘
Scotland’和‘Japan’;当index中出现字典中没有的键值时,显示NaN。比如,‘Hockey’对应的值为NaN:

尽管,Series值序列要求是同一个类型,但是index不一定是同一个类型,也不要求index唯一。
s = pd.Series([1, 2, 3])
s.loc['Animal'] = 'Bears'
s
代码运行结果如下:

索引定位
联系所学到的SQL的知识和算法知识,索引的存在就是为了快速搜索。
Series.iloc[]
之所以是[]而不是(),.iloc是Series的一个属性,而它本身支持[]这种运算。下面的.loc[]也是同样的道理。[]中填入的元素可以是:单个整数,整数列表,整数slicing,boolean值 ect。
Series.loc[]
和.iloc[]不同这里的.loc[]需要填入的是index值。
Series[]
直接通过index进行索引
sports = {'Archery': 'Bhutan',
'Golf': 'Scotland',
'Sumo': 'Japan',
'Taekwondo': 'South Korea'}
s = pd.Series(sports)
s.iloc[3],s.loc['Golf'],s[3], s['Golf']
这里返回的结果是:
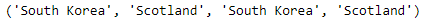
Series.append()
append()方法可以向Series()末端增加元素。这个方法的inplace = False,不对原来的Series进行修改而是返回一个增长Series的结果,在具体操作时候需要注意。
original_sports = pd.Series({'Archery': 'Bhutan',
'Golf': 'Scotland',
'Sumo': 'Japan',
'Taekwondo': 'South Korea'})
cricket_loving_countries = pd.Series(['Australia',
'Barbados',
'Pakistan',
'England'],
index=['Cricket',
'Cricket',
'Cricket',
'Cricket'])
all_countries = original_sports.append(cricket_loving_countries)
Tip about sum and increment
在这一部分,穿插讲解了numpy中的np.sum()方法对数值型序列可以进行求和操作,求和速度比循环求和的速度要快。
另外,一个建议是broadcasting,cost+=2,这个操作相当于是cost = cost + 2。但是前者的运行速度比较快。
DataFrame
生成
- 列表生成
import pandas as pd
purchase_1 = pd.Series({'Name': 'Chris',
'Item Purchased': 'Dog Food',
'Cost': 22.50})
purchase_2 = pd.Series({'Name': 'Kevyn',
'Item Purchased': 'Kitty Litter',
'Cost': 2.50})
purchase_3 = pd.Series({'Name': 'Vinod',
'Item Purchased': 'Bird Seed',
'Cost': 5.00})
df = pd.DataFrame([purchase_1, purchase_2, purchase_3], index=['Store 1', 'Store 1', 'Store 2'])
df.head()
这里的列表元素每一个将成为DataFrame的observation。如图,
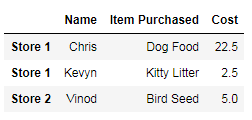
- Pandas.read_csv()
df = pd.read_csv('olympics.csv', index_col = 0, skiprows=1)
# indexl_col = 0 选择第一列数据作为index, skiprows = 1 跳过第一行数据直接读取第二行数据
df.head()
运行结果如下:

课件中有一段对列名称进行变更的操作:
for col in df.columns:
if col[:2]=='01':
df.rename(columns={col:'Gold' + col[4:]}, inplace=True)
if col[:2]=='02':
df.rename(columns={col:'Silver' + col[4:]}, inplace=True)
if col[:2]=='03':
df.rename(columns={col:'Bronze' + col[4:]}, inplace=True)
if col[:1]=='№':
df.rename(columns={col:'#' + col[1:]}, inplace=True)
df.head()
DataFrame.rename()是对数据框名称进行修改的方法,给定columns修改的一个mapping可以对columns的名称进行修改,默认inplace = True;如果需要inplace的修改的话设定inplace = False。
修改后的结果如图,

索引定位
索引定位和Series相似,但是DataFrame多了一个列字段的维度。所以除了行索引之外也可以进行列索引。列索引有两种形式:DataFrame[‘ColumnsName’]和DataFrame.ColunmsName,这可以索引到单列的结果。多列索引的形式是DataFrame[ [‘ColumnsName1’, …, ‘ColumnsName2’] ]。
比如,
df['Gold']
df.Gold
# 前两行代码得到相同的结果
df[['Gold','Gold.1']]
结合之前所描述的iloc[]和loc[]。索引的形式非常丰富:
df.loc['Store 1', 'Cost']
df.loc['Store 1']['Cost']
df.loc[:,['Name', 'Cost']]
对索引操作
直接移步
需要补充的一点是DataFrame.set_index(columnNames)columnsNames可以是多个column name的列表。也就是说DataFrame可以设定multiple index。
条件查询
支持布尔查询,这一点和R,MATLAB很相似。df[boolean expr]结果会返回boolean expr记录对应为True的所有记录。
only_gold = df[df['Gold'] > 0]
only_gold.head()
运行结果如下,

缺失值丢弃和填充
DataFrame.dropna()
只要DataFrame的记录中出现有NA的值,那么返回结果会删掉这一条记录。
DataFrame.dropna(method = 'ffill')
按照列序列前一个记录值进行缺失值填充。
删除操作
记录删除
DataFrame.drop([integers])可以删除对应的记录(记住从Python计数是从0开始的),inplace参数默认为False。
列删除
del DataFrame[columnNames] 这是永久删除的操作。