一、超参数寻优技巧
- 对于超参数选择不要采用网格搜索,而是采用随机搜索。
- 使用(log scale)对数尺度搜索而不要用线性尺度搜索
- 先大范围再缩小范围(coarse to fine)
(1)学习率α

(2)beta
1/(1-beta)前多少项的平均
beta越接近1越敏感,对数尺度搜索对接近1的搜索精度越大
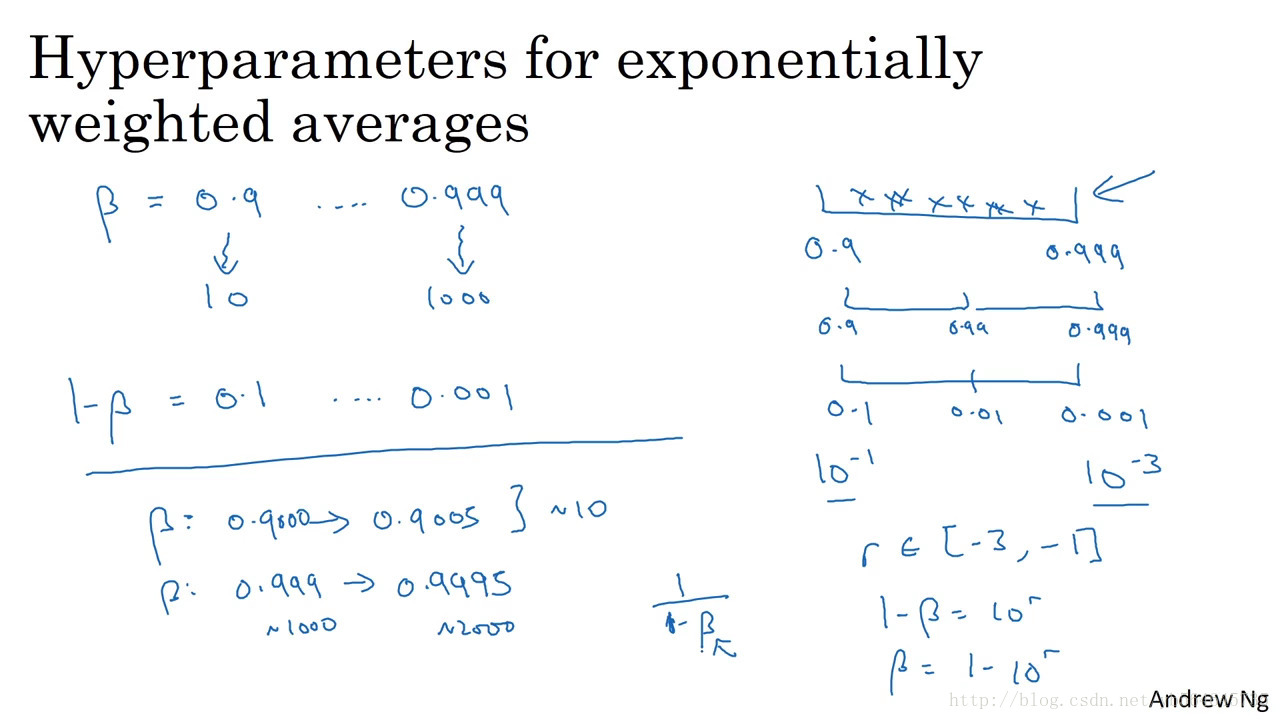
二、batch normalization
对每一个隐藏层都进行分布调整,将均值与方差当做参数进行学习,得到适合每一层的分布。

- Batch norm可以减少神经网络后一层与前一层的耦合,即后层适应前面变化的能力减弱了。
- 可以起到轻微regularization的作用。因为使用mini-batch的时候,隐藏层单元的方差和均值都有噪声,使网络不会太依赖某一层。可以与dropout共同使用。
前向子程序
def batchnorm_forward(x, gamma, beta, bn_param):
"""
Forward pass for batch normalization.
During training the sample mean and (uncorrected) sample variance are
computed from minibatch statistics and used to normalize the incoming data.
During training we also keep an exponentially decaying running mean of the
mean and variance of each feature, and these averages are used to normalize
data at test-time.
At each timestep we update the running averages for mean and variance using
an exponential decay based on the momentum parameter:
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
Note that the batch normalization paper suggests a different test-time
behavior: they compute sample mean and variance for each feature using a
large number of training images rather than using a running average. For
this implementation we have chosen to use running averages instead since
they do not require an additional estimation step; the torch7
implementation of batch normalization also uses running averages.
Input:
- x: Data of shape (N, D)
- gamma: Scale parameter of shape (D,)
- beta: Shift paremeter of shape (D,)
- bn_param: Dictionary with the following keys:
- mode: 'train' or 'test'; required
- eps: Constant for numeric stability
- momentum: Constant for running mean / variance.
- running_mean: Array of shape (D,) giving running mean of features
- running_var Array of shape (D,) giving running variance of features
Returns a tuple of:
- out: of shape (N, D)
- cache: A tuple of values needed in the backward pass
"""
mode = bn_param['mode']
eps = bn_param.get('eps', 1e-5)
momentum = bn_param.get('momentum', 0.9)
N, D = x.shape
running_mean = bn_param.get('running_mean', np.zeros(D, dtype=x.dtype))
running_var = bn_param.get('running_var', np.zeros(D, dtype=x.dtype))
out, cache = None, None
if mode == 'train':
###########################################################
# TODO: Implement the training-time forward pass for batch norm. #
# Use minibatch statistics to compute the mean and variance, use #
# these statistics to normalize the incoming data, and scale and #
# shift the normalized data using gamma and beta. #
# #
# You should store the output in the variable out. Any intermediates #
# that you need for the backward pass should be stored in the cache #
# variable. #
# #
# You should also use your computed sample mean and variance together #
# with the momentum variable to update the running mean and running #
# variance, storing your result in the running_mean and running_var #
# variables. #
#########################################################
sample_mean = np.mean(x, axis=0)
sample_var = np.var(x, axis=0)
x_norm = (x - sample_mean)/np.sqrt(sample_var + eps)
out = gamma*x_norm + beta
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
cache = (x_norm, gamma, sample_mean, sample_var, eps, x)
#########################################################
# END OF YOUR CODE #
#########################################################
elif mode == 'test':
#########################################################
# TODO: Implement the test-time forward pass for batch normalization. #
# Use the running mean and variance to normalize the incoming data, #
# then scale and shift the normalized data using gamma and beta. #
# Store the result in the out variable. #
#########################################################
x_norm = (x - running_mean)/np.sqrt(running_var + eps)
out = gamma*x_norm + beta
#########################################################
END OF YOUR CODE #########################################################
else:
raise ValueError('Invalid forward batchnorm mode "%s"' % mode)
# Store the updated running means back into bn_param
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return out, cache反向子程序
def batchnorm_backward(dout, cache):
"""
Backward pass for batch normalization.
For this implementation, you should write out a computation graph for
batch normalization on paper and propagate gradients backward through
intermediate nodes.
Inputs:
- dout: Upstream derivatives, of shape (N, D)
- cache: Variable of intermediates from batchnorm_forward.
Returns a tuple of:
- dx: Gradient with respect to inputs x, of shape (N, D)
- dgamma: Gradient with respect to scale parameter gamma, of shape (D,)
- dbeta: Gradient with respect to shift parameter beta, of shape (D,)
"""
dx, dgamma, dbeta = None, None, None
###########################################################################
# TODO: Implement the backward pass for batch normalization. Store the #
# results in the dx, dgamma, and dbeta variables. #
###########################################################################
N = dout.shape[0]
x_norm, gamma, sample_mean, sample_var, eps, x = cache
dx_norm = dout*gamma
dgamma = np.sum(dout*x_norm, axis=0)
dbeta = np.sum(dout, axis=0)
dsample_var = np.sum((x-sample_mean)*(-1/2)*((sample_var+eps)**(-3/2))*dx_norm, axis=0)
dsample_mean = np.sum(-dx_norm/np.sqrt(sample_var+eps), axis=0)
dsample_mean += dsample_var*(-2/N)*np.sum(x-sample_mean, axis=0)
dx = dx_norm/np.sqrt(sample_var+eps)
dx += dsample_var*(2/N)*(x-sample_mean)
dx += dsample_mean/N
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx, dgamma, dbeta