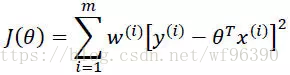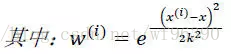什么是机器学习
作为机器学习领域的先驱,Arthur Samuel在 IBM Journal of Research and Development期刊上发表了一篇名为《Some Studies in Machine Learning Using the Game of Checkers》的论文中,将机器学习非正式定义为:”在不直接针对问题进行编程的情况下,赋予计算机学习能力的一个研究领域。”
Tom Mitchell在他的《Machine Learning(中文版:计算机科学丛书:机器学习 )》一书的序言开场白中给出了一个定义:
“机器学习这门学科所关注的问题是:计算机程序如何随着经验积累自动提高性能。”
“对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么我们称这个计算机程序在从经验E学习。”
他没有告诉机器应该怎么下棋,机器可以自己不断学习如何下棋,因此把这一过程带入到定义中,我们知道:
E:机器不断下棋的经历 T:下棋 P:下棋的胜率
机器学习分类
1.监督学习(Supervised Learning)
有标准答案(有标签)
-
regression 回归问题(连续) 例:房价变化
-
classification 分类问题(离散) 例:字符识别
2.非监督学习(Unsupervised Learning)
没有标准答案(无标签)
-
K-means聚类
-
PCA
3.强化学习/反馈学习(Reinforcement Learning)
你在训练一只狗,每次狗做了一些你满意的事情,你就说一声“Good boy” 然后奖励它。每次狗做了something bad 你就说 "bad dog ",渐渐的,狗学会了做正确的事情来获取奖励。
强化学习与其他机器学习不同之处为:
- 没有教师信号,也没有label。只有reward,其实reward就相当于label。
- 反馈有延时,不是能立即返回。
- 相当于输入数据是序列数据。
- agent执行的动作会影响之后的数据。
常用的字母表示
m => training examples 训练数据数目
x => input variables/features 输入变量
y => output/target variable
(x, y) => training example
theta => parameters
training set
|
learning algorithm
|
input -> h(hypothesis) -> output
一元线性回归
回归分析(Regression Analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
举个例子:可以根据房子的平米数来估算房价
一元线性方程公式:hθ(x) = θ0 + θ1x,可以用作拟合函数
如何求解拟合函数可以使用最小二乘法,所谓最小二乘,其实也可以叫做最小平方和。就是让目标对象和拟合对象的误差最小。即通过最小化误差的平方和,使得拟合对象无限接近目标对象,这就是最小二乘的核心思想。所以把拟合值和实际值的差求平方和,可以得到损失函数,最小化损失函数可以得到
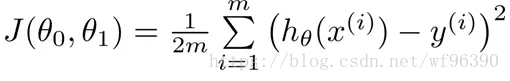
求解方法
方法一:梯度下降
步长选择:步长过小—收敛太慢 步长过大—无法收敛
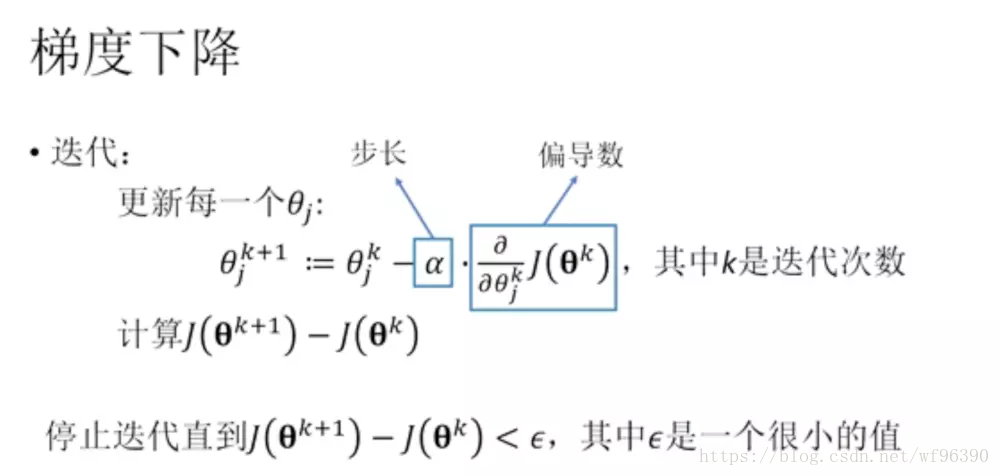
批量梯度下降(Batch gradient descent )
全局最优,数据量太大无法计算

随机梯度下降(Stochastic gradient descent)
适合于低精度的任务

方法二:正规方程组
两种方法比较:

欠拟合和过拟合
首先我们来看一个线性回归的问题,在下面的例子中,我们选取不同维度的特征来对我们的数据进行拟合。
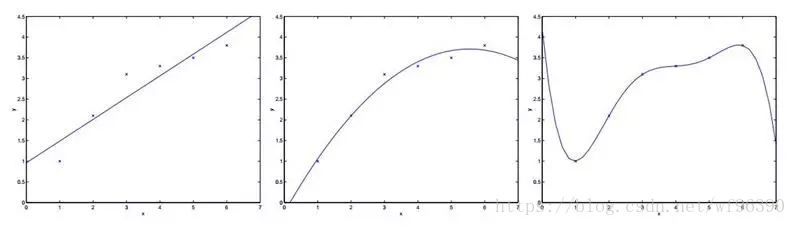
对于上面三个图像做如下解释:
选取一个特征x,y = θ0 + θ1x 来拟合数据,可以看出来拟合情况并不是很好,有些数据误差还是比较大。
针对第一个,我们增加了额外的特征 x2, y = θ0 + θ1x + θ2x2 ,这时我们可以看出情况就好了很多。
这个时候可能有疑问,是不是特征选取的越多越好,维度越高越好呢?所以针对这个疑问,如最右边图,我们用5揭多项式使得数据点都在同一条曲线上,为
。此时它对于训练集来说做到了很好的拟合效果,但是,我们不认为它是一个好的假设,因为它不能够做到更好的预测。
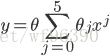
针对上面的分析,我们认为第二个是一个很好的假设,而第一个图我们称之为欠拟合(underfitting),而最右边的情况我们称之为过拟合(overfitting)
局部加权线性回归
对于线性回归算法,一旦拟合出适合训练数据的参数θi’s,保存这些参数θi’s,对于之后的预测,不需要再使用原始训练数据集,所以是参数学习算法。
对于局部加权线性回归算法,每次进行预测都需要全部的训练数据(每次进行的预测得到不同的参数θi’s),没有固定的参数θi’s,所以是非参数算法。
对于上述公式的理解是这样的:x为某个预测点,x^((i))为样本点,样本点距离预测点越近,贡献的误差越大(权值越大),越远则贡献的误差越小(权值越小)。关于预测点的选取,在我的代码中取的是样本点。其中k是带宽参数,控制w(钟形函数)的宽窄程度,类似于高斯函数的标准差。