版权声明:欢迎转载,但请注明出处 https://blog.csdn.net/li528405176/article/details/82969462
机器学习:使计算机模拟或实现人类的学习行为,以获取新的知识或技能。并重新组织已有的知识结构使之不断改善自身的性能。
监督学习(supervised learning)
问题引入
根据给定的一组采集数据,预测房价。
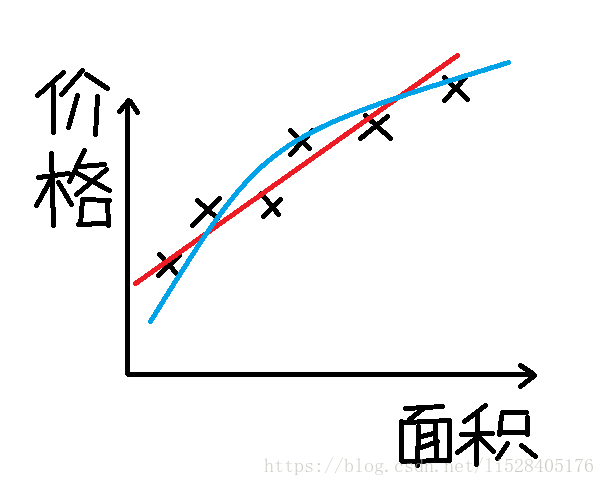
我们可以看到,问题只有单个输入变量,即单个特征。因变量为价格,可以取任意值,即连续。因此我们可以利用线性回归将给定数据拟合成一条曲线(直线或抛物线等),来解决该回归问题。然后我们就可以在这条曲线上去预测其他已知面积房屋的价格了。
对于另一类问题,例如根据医院的肿瘤诊断数据,预测肿瘤性质。
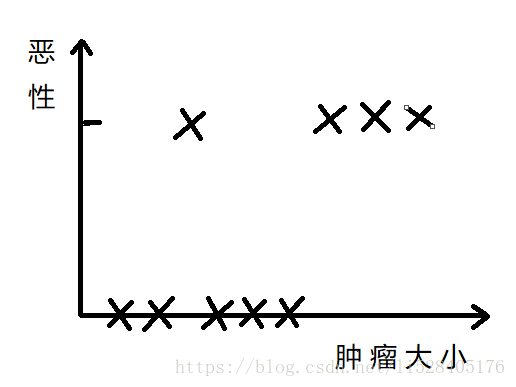
易知,因变量肿瘤性质不是恶性就是良性,即离散。对于这种分类问题,我们可以使用逻辑回归来处理。
上例仍然只有单个输入变量。但多数情况下,需要考虑多个输入变量和特征,如下例:
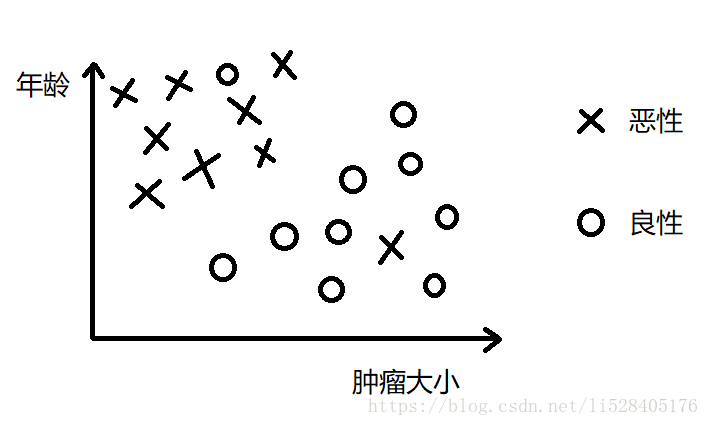
输入变量包括患者年龄和肿瘤大小,输出变量为肿瘤性质。
机器学习理论
探究为什么机器学习算法是有效的。
无监督学习
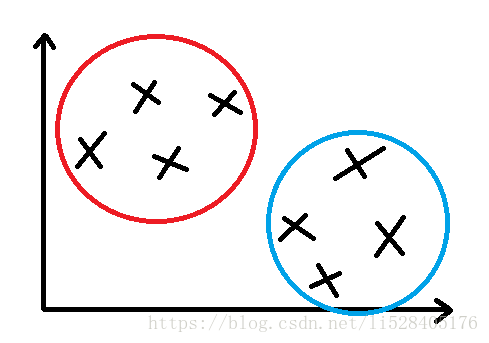
利用聚类算法,将无标签的数据进行分类。
无监督学习还可以用来解决有趣的鸡尾酒问题,在混合在一起的声音中对某一个声音进行提取。除此之外,文本处理、理解功能分级和机械数据等也可以使用这类无监督学习算法来解决。
增强学习
增强学习可以使电脑自主学习,其关键概念在于回报函数(惩罚函数)。计算机在一段时间内做出一系列决策,每次决策后通过回报函数来判断该决策是好是坏,然后改善自己的决策模型。