一、什么是Pandas?
pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法,是python的一个数据分析包。
Pandas模块具有高性能、高效率和高水平,使之成为数据分析最有效的库。
二、Pandas的数据结构
pandas的数据结构中,常用的有Series和DataFrame两种
1、Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近。Series如今能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
Series与List的区别是:List中的元素可以是不同的数据类型,而Series中则只允许存储有相同的数据类型,这样是为了更有效地的使用内存,提高运算效率。
2、Time- Series:以时间为索引的Series。
3、DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。
4、Panel :三维的数组,可以理解为DataFrame的容器。
三、Pandas的IO功能
Pandas的IO功能十分强大,可以兼容许多文本文件,例如:csv、xml、HTML、xls、xlsx等
1、导入数据集的语法为:
pd.read_excel(filename) #导入Excel格式文件中的数据
pd.read_excel(filename) #导入Excel格式文件中的数据
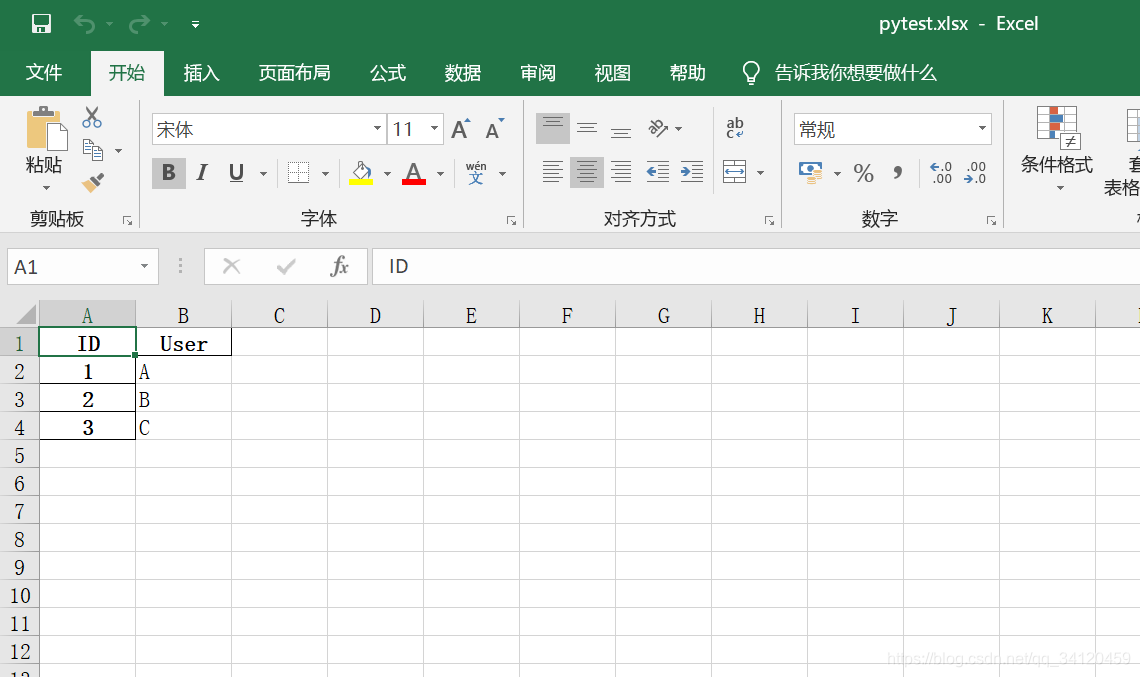
2、创建Excel表
import pandas as pd #导入pandas模块,命名为pd
a = pd.DataFrame({'ID':[1, 2, 3],'User':['A', 'B', 'C']}) #创建ID列和User列
a = a.set_index('ID') #以ID为索引
print(a)
a.to_excel('D:\pandas\pytest.xlsx') #新建pytest.xlsx文件,将以上信息保持到该文件中
print('成功啦!')
运行结果:

3、查看数据框
data.info() #查看数据框(Data Frame)的索引、数据类型及内存信息
- pytest.xlsx文件中的内容为:
- 查看数据框代码如下:
import pandas as pd
data = pd.read_excel('D:\pandas\pytest.xlsx')
data.info()
- 代码执行结果:

4、查看数据框行与列:
data.shape #查看数据框的行数和列数
import pandas as pd
data = pd.read_excel('D:\pandas\pytest.xlsx')
print(data.shape)
#运行结果:(3, 2)
5、查看数据前n行、中间某几行或后n行:
data.head(n) #查看数据框的前n行
data.tail(n) #查看数据框的后n行
data.iloc[a:b,c:d] #查看第a+1行到b行,c+1列到d列的数据
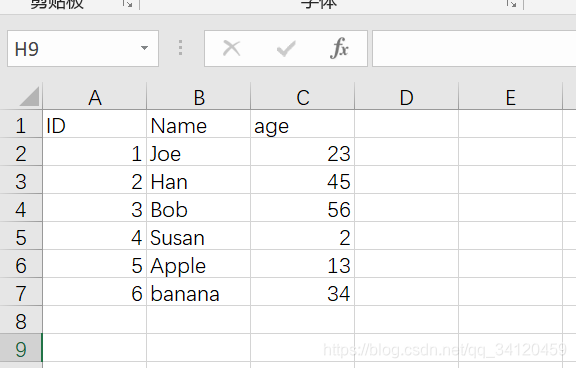
- D:\pandas\pytest2.xlsx 文件内容如下:
import pandas as pd
data = pd.read_excel('D:\pandas\pytest2.xlsx')
print(data)
print("前2行的数据为:")
print(data.head(2))
print("后1行的数据为:")
print(data.tail(1))
print("2、3行与2、3列交叉的数据为:")
print(data.iloc[1:3, 1:3])
- 运行结果:

四、数据选取与清洗:
1、查看某一列的数据
data[col] #以数组Series的形式返回选取的列
- 查看某一列的数据
import pandas as pd
data = pd.read_excel('D:\pandas\pytest2.xlsx')
print("查看Name列的数据")
print(data['Name'])

- 查看某几列的数据(将想要查看的列名放在一个列表中)
import pandas as pd
data = pd.read_excel('D:\pandas\pytest2.xlsx')
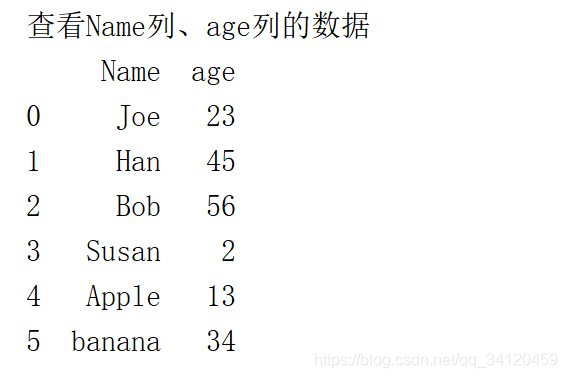
print("查看Name列、age列的数据")
print(data[['Name', 'age']])
2、数据中非空值的处理
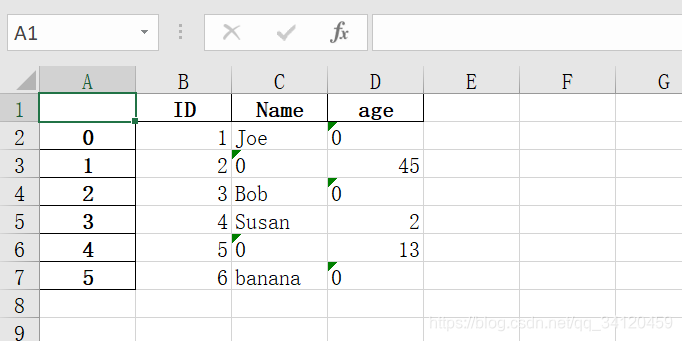
- pytest3.xlsx文件中的内容为:
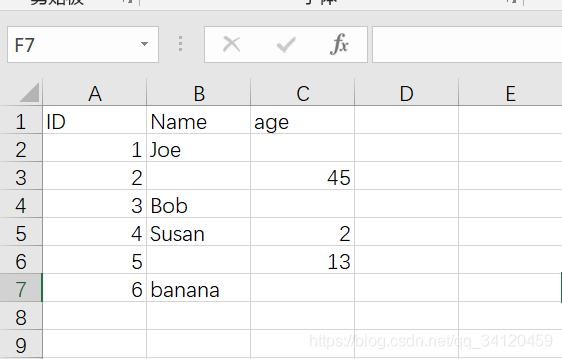
- 查看数据中的空值
data.isnull() #检查数据中空值出现的情况,并返回一个布尔值(True或False组成的列)
import pandas as pd
data = pd.read_excel('D:\pandas\pytest3.xlsx')
print(data.isnull())

- 查看数据框中的非空值
data.notnull() #查看数据框中的非空值
import pandas as pd
data = pd.read_excel('D:\pandas\pytest3.xlsx')
print(data.notnull())

- 移除数据框中的非空值
data.dropna(axis = 1) #移除数据框中包含空值的列
import pandas as pd
data = pd.read_excel('D:\pandas\pytest3.xlsx')
print(data.dropna())

- 替换数据框中的非空值
data.fillna(x) #将数据框中的所有空值替换为x
import pandas as pd
data = pd.read_excel('D:\pandas\pytest3.xlsx')
print(data.fillna('变身'))

3、数据框中值的替换
- pytest4.xlsx文件的内容如下:
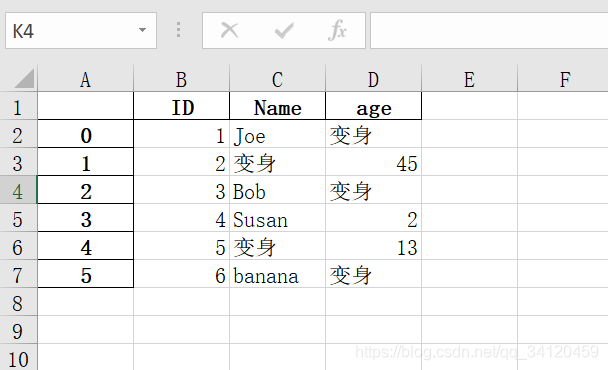
- 替换值
import pandas as pd
data = pd.read_excel('D:\pandas\pytest4.xlsx')
data2 = data.replace('变身', '0')
data2.to_excel('D:\pandas\pytest4.xlsx')
print('ok')
#运行结果:ok
- 代码运行后excel表格数据变为: