为什么是pandas
numpy能够帮我们处理处理数值型数据,但是这还不够
很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等
numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据
数据类型
- Series 一维,带标签数组
- DataFrame 二维,Series容器
理解带标签的数组和Series容器的含义
series
通过数组创建,并指定Index
t = pd.Series(np.arange(10), index=list(string.ascii_uppercase[0:10]))
t
Out[12]:
A 0
B 1
C 2
D 3
E 4
F 5
G 6
H 7
I 8
J 9
dtype: int32Series 数据只有一列,这是和DataFrame很大的一点不同
通过字典创建
a = {string.ascii_uppercase[i]:i for i in range(10)}
a
Out[15]:
{'A': 0,
'B': 1,
'C': 2,
'D': 3,
'E': 4,
'F': 5,
'G': 6,
'H': 7,
'I': 8,
'J': 9}
pd.Series(a)
Out[16]:
A 0
B 1
C 2
D 3
E 4
F 5
G 6
H 7
I 8
J 9
dtype: int64
上述利用字典推导式
a
Out[26]:
{'A': 0,
'B': 1,
'C': 2,
'D': 3,
'E': 4,
'F': 5,
'G': 6,
'H': 7,
'I': 8,
'J': 9}
pd.Series(a, index=list(string.ascii_uppercase[5:15]))
Out[27]:
F 5.0
G 6.0
H 7.0
I 8.0
J 9.0
K NaN
L NaN
M NaN
N NaN
O NaN
dtype: float64
- 我们发现有NaN的时候,原来的5变成5.0, pandas自动帮我们做了类型转换
- 重新指定索引的时候,如果能对应上就取值,对应不上就是None,很好理解,别人有10种水果,要了苹果有苹果,要了菠萝没菠萝那就是NaN了
series的切片和索引
切片:传入start end 步长即可或者传入开始index到结束index(不能加步长)
索引:索引一个值直接传入序号或者index,索引多个值就需要传入index或序号的列表
series的两种转换方法
s
Out[193]:
a 1.0
b 3.0
c 8.0
Name: A, dtype: float64
s.to_dict()
Out[194]: {'a': 1.0, 'b': 3.0, 'c': 8.0}
s.tolist()
Out[195]: [1.0, 3.0, 8.0]
Series 迭代,计数,布尔索引,排序
b
Out[31]:
A 0
B 1
C 2
D 3
E 4
F 5
G 6
H 7
I 8
J 9
dtype: int64
b.count()
Out[32]: 10
for i in b:
print(i)
0
1
2
3
4
5
6
7
8
9b
Out[47]:
A NaN
B 1.0
C 2.0
D -1.0
E 4.0
F 5.0
G 6.0
H 7.0
I 8.0
J 9.0
dtype: float64
b.sort_values(ascending=False)
Out[48]:
J 9.0
I 8.0
H 7.0
G 6.0
F 5.0
E 4.0
C 2.0
B 1.0
D -1.0
A NaN
dtype: float64b
Out[60]:
A 0.0
B 1.0
C 2.0
D NaN
E 4.0
F 5.0
G 6.0
H 7.0
I 8.0
J 9.0
dtype: float64
pd.isna(b)
Out[61]:
A False
B False
C False
D True
E False
F False
G False
H False
I False
J False
dtype: bool
b[pd.notna(b)]
Out[62]:
A 0.0
B 1.0
C 2.0
E 4.0
F 5.0
G 6.0
H 7.0
I 8.0
J 9.0
dtype: float64
b[b>4]
Out[63]:
F 5.0
G 6.0
H 7.0
I 8.0
J 9.0
dtype: float64
DataFrame
读取外部数据
- read_csv()
- pd.read_sql(sql_sentence,connection)
创建DataFrame数据
普通方式
t = pd.DataFrame(np.arange(12).reshape((3,4)), index=list('abc'), columns=list('ABCD'))
t
Out[66]:
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
通过字典创建
d1 = {'name':['lily', 'jack'], 'age': 23}
t1 = pd.DataFrame(d1)
t1
Out[74]:
name age
0 lily 23
1 jack 23
# 通过下面这种方式创建时,arrays must all be same length,否则会报错
d2 = {'name':['lily', 'jack'], 'age': [23,12]}
t2 = pd.DataFrame(d2)
t2
Out[77]:
name age
0 lily 23
1 jack 12通过列表的方式创建
l1 = [{'name':'jack', 'age':12}, {'name':'tuple'}]
t3 = pd.DataFrame(l1)
t3
Out[84]:
age name
0 12.0 jack
1 NaN tuple
l2 = [{'name':'jack', 'age':12}, {'name':'tuple', 'nation':'china'}]
t4 = pd.DataFrame(l2)
t4
Out[87]:
age name nation
0 12.0 jack NaN
1 NaN tuple china
列表中的每个字典表示一个数据,利用这种方式可以读取mongdb的查询出来的数据内容
基本属性
- ndim
- shape
- values
- index
- columns
- dtypes
整体情况
- head(3)
- tail(3)
- info()
- describe()
排序
df.sort_values(by="Count_AnimalName",ascending=False)
by可以接列表表示按照多列进行排序
取行或列
选择列
t
Out[131]:
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
t['A']
Out[132]:
a 0
b 4
c 8
Name: A, dtype: int32t['A']直接中括号这种形式表示取columns
选择行
t[1:3]
Out[133]:
A B C D
b 4 5 6 7
c 8 9 10 11
但是不能直接t[1]这样会报错,因为语法会把1当做columns. 为了解决这种情况才出现了loc和iloc
loc和iloc
- df.loc 通过标签索引行数据
df.iloc 通过位置获取行数据
取值规则就和nump取通用值的规则类似[,]t Out[134]: A B C D a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 t.loc['a','A'] Out[135]: 0 t.loc['a',['A','C']] Out[136]: A 0 C 2 Name: a, dtype: int32 t.loc[['a','b'],['A','C']] Out[137]: A C a 0 2 b 4 6 t Out[141]: A B C D a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 t.iloc[1:3,2] = 100 t Out[143]: A B C D a 0 1 2 3 b 4 5 100 7 c 8 9 100 11
布尔索引
矩阵布尔索引
t[t>10]
Out[152]:
A B C D
a NaN NaN NaN NaN
b NaN NaN 100.0 NaN
c NaN NaN 100.0 11.0
t>10
Out[153]:
A B C D
a False False False False
b False False True False
c False False True True
t
Out[154]:
A B C D
a 0 1 2 3
b 4 5 100 7
c 8 9 100 11
向量布尔索引
t
Out[155]:
A B C D
a 0 1 2 3
b 4 5 100 7
c 8 9 100 11
t[t.B>5]
Out[156]:
A B C D
c 8 9 100 11多个条件的情况
- 不同条件必须用括号括起来
- & 且 | 或
利用布尔索引赋值
t
Out[172]:
A B C D
a 0.0 1 2 3
b NaN 5 100 7
c 8.0 9 100 11
t[t==0] = None
t
Out[174]:
A B C D
a NaN 1 2 3
b NaN 5 100 7
c 8.0 9 100 11
pandas字符串方法

缺失值的处理
处理方式1:删除NaN所在的行列dropna (axis=0, how='any', inplace=False)
处理方式2:填充数据,t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0) df["A"] = df["A"].fillna(df["A"].mean())
判断是否是nan, t.isna(),t.notna()
数据合并
join:默认情况下他是把行索引相同的数据合并到一起,例如t1.join(t2) t1在前面显示全,t2没有的补nan
merge: 和数据库的连接类似,参数有on, left_on, right_on. how
无论是join还是merge,最终的结果都是t1和t2的columns都会显示,例如t1有2个columns,t2有3个columns, 最终合并的结果就是5个columns, 这是合并最明显的特征
字符串离散化
有这样一组数据,其中有一个字段是genre,代表电影分类,而且一个电影可能有好几个分类,以,分隔,现在要统计每个分类的电影数。
思路:
- 要统计每个分类,首先需要知道有多少分类
- 常规思路是循环每个分类,再循环所有数据,然后进行比较判断,两层循环这样的效率就低了,这时候就能看出pandas的强大了
重新构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1
df = pd.read_csv(file_path) print(df["Genre"].head(3)) #统计分类的列表 temp_list = df["Genre"].str.split(",").tolist() #[[],[],[]] genre_list = list(set([i for j in temp_list for i in j])) #构造全为0的数组 zeros_df = pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list) # print(zeros_df) #给每个电影出现分类的位置赋值1 for i in genre_list: zeros_df[i][df["Genre"].str.contains(i)] = 1 #统计每个分类的电影的数量和 genre_count = zeros_df.sum(axis=0) print(genre_count)
上述思路很重要,利用pandas的比较操作和布尔索引的结合有效避免了我们自己用for循环的低效
分组和聚合
DataFrame的分组
在pandas中类似的分组的操作我们有很简单的方式来完成
df.groupby(by="columns_name")
t
Out[219]:
A B C D
a 5.5 1 2 3
b 3.0 5 100 7
c 8.0 9 100 11
g = t.groupby(by='C')
g.count()
Out[221]:
A B D
C
2 1 1 1
100 2 2 2
type(g.count())
Out[222]: pandas.core.frame.DataFrame
for i, j in g:
print(i)
print(j)
2
A B C D
a 5.5 1 2 3
100
A B C D
b 3.0 5 100 7
c 8.0 9 100 11DataFrame分组之后调用聚合方法之后还是DataFrame
DataFrameGroupBy对象有很多经过优化的方法:

多条件分组
t
Out[267]:
A B C D
a 5.5 1 2 3
b 3.0 5 100 7
c 8.0 2 100 11
t.groupby(by='C')['A']
Out[268]: <pandas.core.groupby.groupby.SeriesGroupBy object at 0x00000000076F77F0>
t.groupby(by='C')
Out[269]: <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x00000000078D1630>
t.groupby(by='C')['A'].sum()
Out[270]:
C
2 5.5
100 11.0
Name: A, dtype: float64
t.groupby(by='C').sum()['A']
Out[271]:
C
2 5.5
100 11.0
Name: A, dtype: float64
t['A'].groupby(by=t['C']).sum()
Out[272]:
C
2 5.5
100 11.0
Name: A, dtype: float64- 多条件分组,分组条件用列表
- 区分条件是字符串还是需要加df[]
获取分组之后的某一部分数据:
df.groupby(by=["Country","State/Province"])["Country"].count()
对某几列数据进行分组:
df["Country"].groupby(by=[df["Country"],df["State/Province"]]).count() 我们发现我们取了df["Country"] 是series类型,竟然还能对没有的字段"State/Province"进行分组,如果是单纯的
series类型这样肯定不行,通过DataFrame取到的series是可以的 - 由于只选择了一列数据,所以结果是一个Series类型, 如果我想返回一个DataFrame类型呢?用双括号取代原来的单括号即可
t1 = df[["Country"]].groupby(by=[df["Country"],df["State/Province"]]).count() 或者
t2 = df.groupby(by=["Country","State/Province"])[["Country"]].count()
t
Out[273]:
A B C D
a 5.5 1 2 3
b 3.0 5 100 7
c 8.0 2 100 11
t.groupby(by='C').sum()
Out[274]:
A B D
C
2 5.5 1 3
100 11.0 7 18
t.groupby(by='C').sum()['A']
Out[275]:
C
2 5.5
100 11.0
Name: A, dtype: float64
t.groupby(by='C').sum()[['A']]
Out[276]:
A
C
2 5.5
100 11.0Series的分组
s
Out[226]:
0 a
1 c
2 a
3 d
4 c
dtype: object
sg = s.groupby(s.values)
sg.count()
Out[228]:
a 2
c 2
d 1
dtype: int64
type(sg.count())
Out[230]: pandas.core.series.Series
for i, j in sg:
print(i)
print(j)
a
0 a
2 a
dtype: object
c
1 c
4 c
dtype: object
d
3 d
dtype: object
series分组之后调用聚合方法之后还是series
索引操作和复合索引
简单的索引操作:
- 获取index:df.index
- 指定index :df.index = ['x','y']
- 重新设置index : df.reindex(list("abcedf"))
- 指定某一列作为index :df.set_index("Country",drop=False)
- 返回index的唯一值:df.set_index("Country").index.unique()
注意几点:
- df.index = ['x','y'] 中 ['x','y'] 的长度需要和原先的df.index长度一致
- reindex 和 用
=对索引重新赋值不一样, df.reindex(list("abcedf")) 是去df中取index为a b c d e f 的记录,取不到就是nan, set_index 会覆盖原来的索引
series的复合索引

那么问题来了:我只想取索引h对应值怎么办?
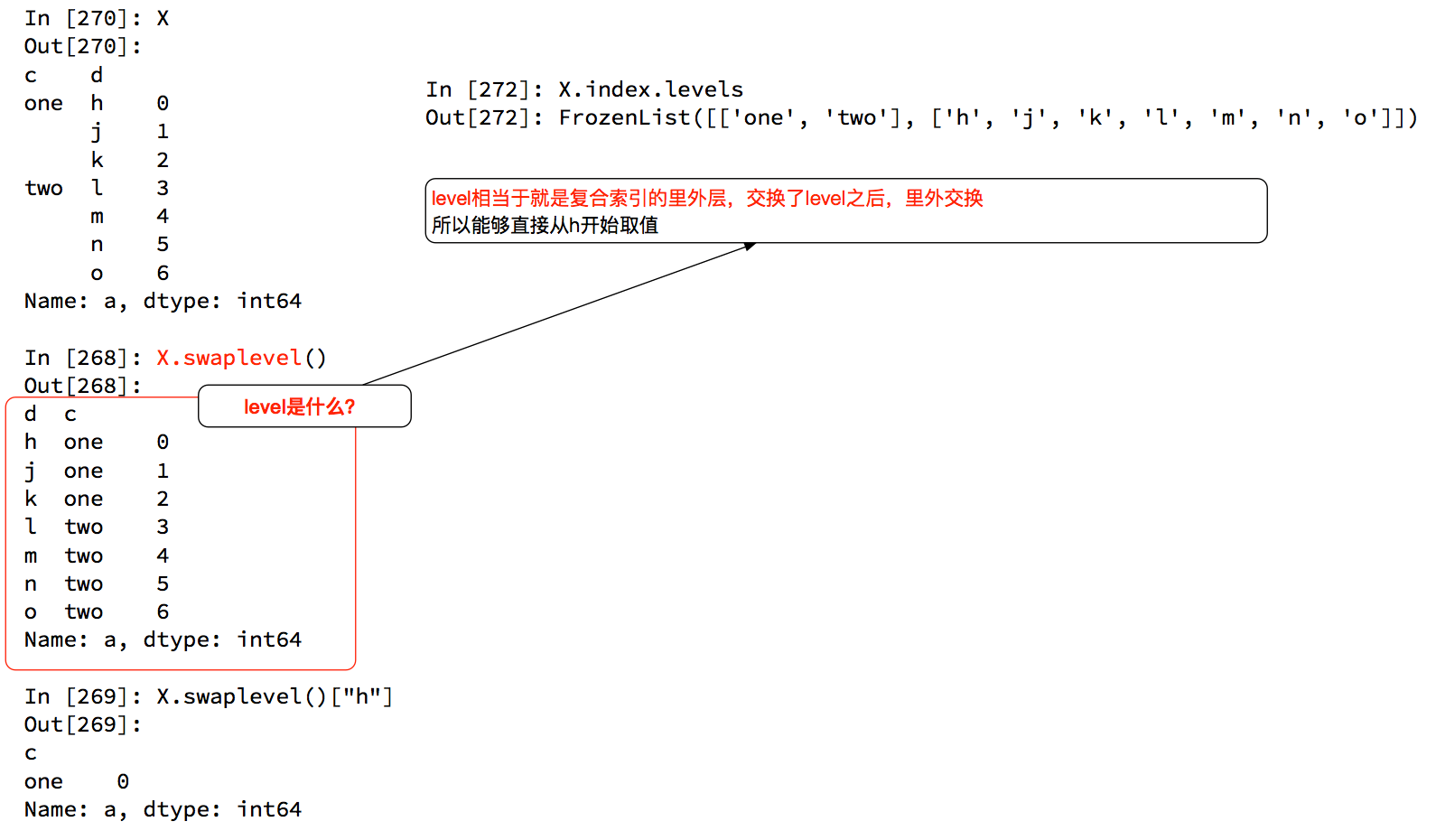
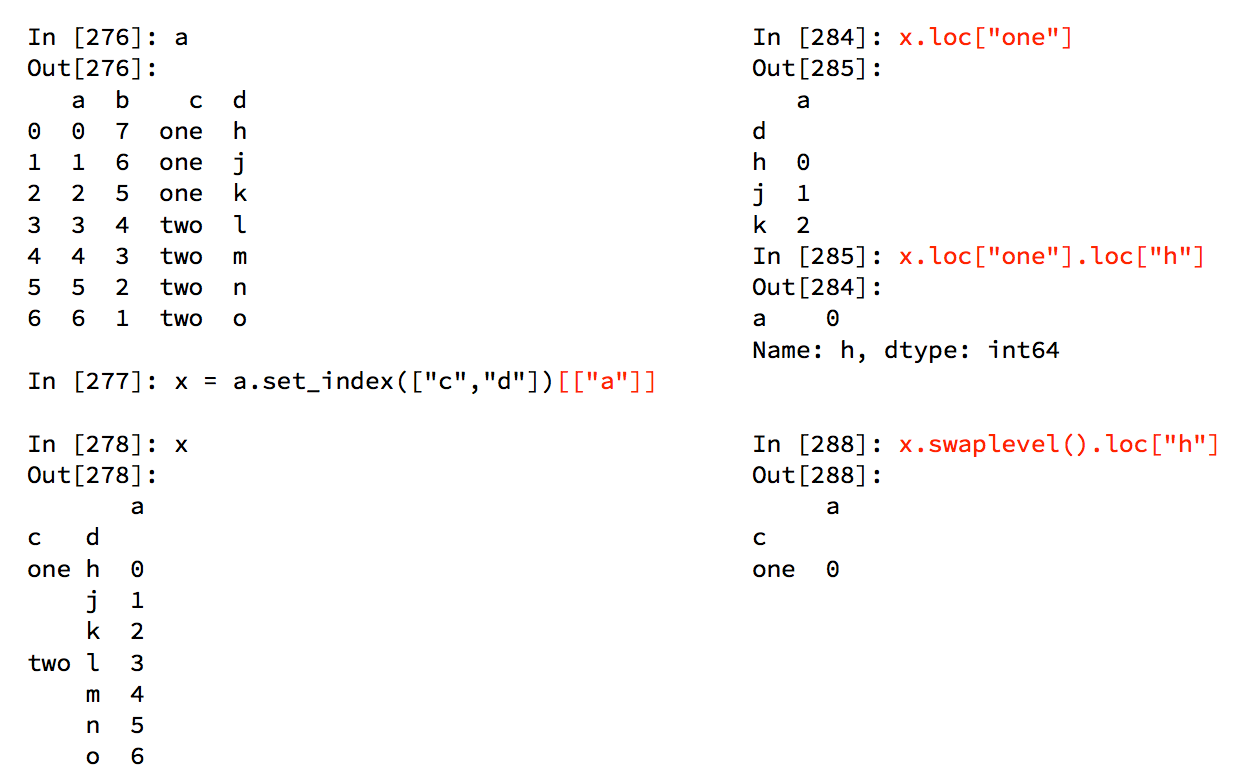
DataFrame的复合索引
时间序列
生成一段时间范围
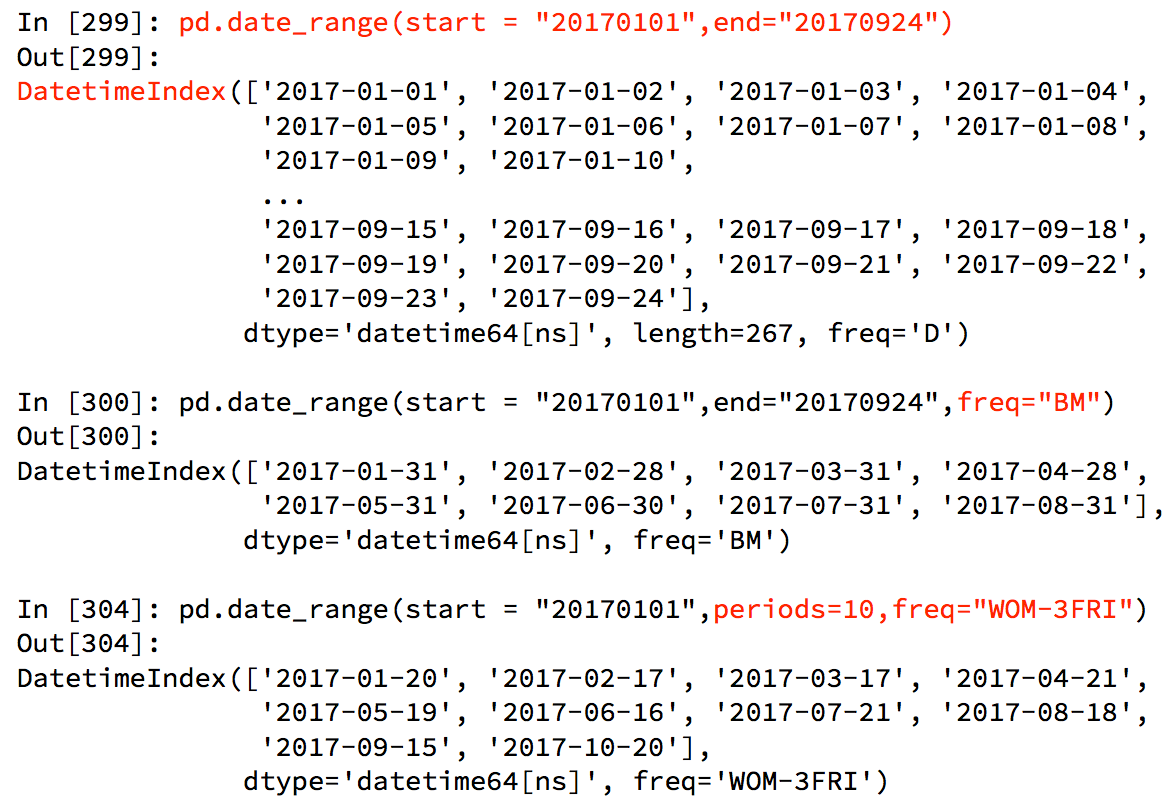
pd.date_range(start=None, end=None, periods=None, freq='D')
start和end以及freq配合能够生成start和end范围内以频率freq的一组时间索引
start和periods以及freq配合能够生成从start开始的频率为freq的periods个时间索引
一般来说,我们不会把end和periods两个参数放在一起用
关于频率的更多缩写

在DataFrame中使用时间序列
我们可以看到上述用date_range生成的数据类型是DatetimeIndex,一种索引类型,所以有关日期的操作我们可以把时间字符串转化为时间序列并set_index为索引再进行相关操作
df["timeStamp"] = pd.to_datetime(df["timeStamp"],format="")
format参数大部分情况下可以不用写,但是对于pandas无法格式化的时间字符串,我们可以使用该参数,比如包含中文
重采样
重采样:指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样,低频率转化为高频率为升采样
pandas提供了一个resample的方法来帮助我们实现频率转化, 重采样做的事情本质上就是对时间的分组
重采样参考文档:https://www.jianshu.com/p/061771f0afa9