目录
一、功能定位
1、什么是pandas?
pandas,python+data+analysis的组合缩写,是python中基于numpy和matplotlib的第三方数据分析库,与后两者共同构成了python数据分析的基础工具包,享有数分三剑客之名。
2、pandas用来作什么?
pandas主要用于数据处理与分析,支持包括数据读写、数值计算、数据处理、数据分析和数据可视化全套流程操作。
二、数据结构
pandas的核心数据结构是一维的series和二维的dataframe。
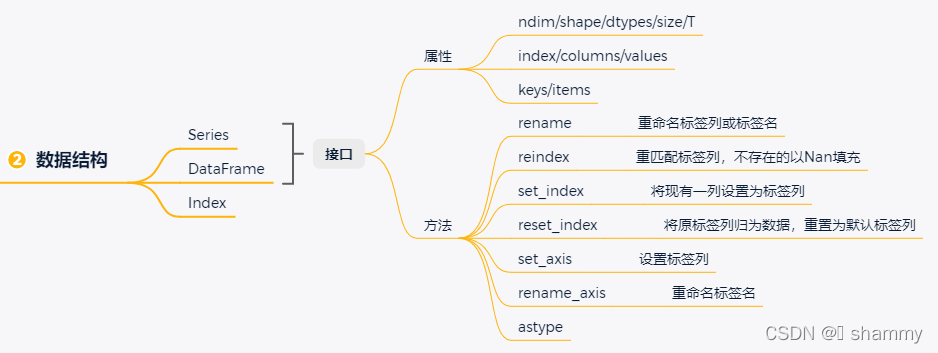
1、dataframe
2、索引操作
2.1 Series索引
import pandas as pd
ser_obj = pd.Series(range(1,6), index = ['a','b', 'c', 'd', 'e'])
print(ser_obj.head())
print('*'*10,'行索引','*'*10)
print(ser_obj['b'])
print(ser_obj[3])
print('*'*10,'切片索引','*'*10)#注意,按索引名切片操作时,是包含终止索引的。
print(ser_obj[1:3])
print(ser_obj['b':'d'])
print('*'*10,'不连续索引','*'*10)
print(ser_obj[[0, 2, 4]])
print(ser_obj[['a', 'e']])
print('*'*10,'布尔索引','*'*10)
ser_bool = ser_obj > 2
print(ser_bool)
print(ser_obj[ser_bool])
print(ser_obj[ser_obj > 2])

2.2 DataFrame索引
import pandas as pd
import numpy as np
df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'])
print(df_obj.head())
print('*'*10,'列索引','*'*10)
print(df_obj['a']) # 返回Series类型
print('*'*10,'不连续索引','*'*10)
print(df_obj[['a','c']])
print('*'*10,'高级索引:标签、位置和混合','*'*10)
print('*'*10,'标签索引 loc','*'*10)#第一个参数索引行,第二个参数是列
print(df_obj.loc[0:2, 'a'])
print('*'*10,'iloc 位置索引','*'*10)
print(df_obj.iloc[0:2, 0]) # 注意和df_obj.loc[0:2, 'a']的区别
print('*'*10,'ix 标签与位置混合索引','*'*10)
print(df_obj.ix[0:2, 0])

三、数据读写
- 文本文件,主要包括csv和txt两种等,相应接口为read_csv()和to_csv(),分别用于读写数据
- Excel文件,包括xls和xlsx两种格式均得到支持,底层是调用了xlwt和xlrd进行excel文件操作,相应接口为read_excel()和to_excel()
- SQL文件,支持大部分主流关系型数据库,例如MySQL,需要相应的数据库模块支持,相应接口为read_sql()和to_sql()
四、数据访问
五、数据处理
1、apply 和 applymap
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(5,4) - 1)
print(df)
print('*'*10,'1.1 使用apply应用行或列数据','*'*10)
print(df.apply(lambda x : x.max()))#注意指定轴的方向,默认axis=0,方向是列
print(df.apply(lambda x : x.max(), axis=1))
print('*'*10,' 1.2 通过applymap将函数应用到每个数据上','*'*10)
# 使用applymap应用到每个数据
f2 = lambda x : '%.2f' % x
print(df.applymap(f2))

2、排序
import pandas as pd
import numpy as np
s4 = pd.Series(range(10, 15), index = np.random.randint(5, size=5))
print(s4)
print('*'*10,'2.1 索引排序','*'*10)
print(s4.sort_index())#排序默认使用升序排序,ascending=False 为降序排序
df4 = pd.DataFrame(np.random.randn(3, 5),
index=np.random.randint(3, size=3),
columns=np.random.randint(5, size=5))
print(df4)
print('*'*10,'2.2 按值排序','*'*10)
df4_vsort = df4.sort_values(by=0, ascending=False)#根据某个唯一的列名进行排序,如果有其他相同列名则报错。
print(df4_vsort)

3、缺失值处理
import pandas as pd
import numpy as np
df_data = pd.DataFrame([np.random.randn(3), [1., 2., np.nan],
[np.nan, 4., np.nan], [1., 2., 3.]])
print(df_data.head())
print('*'*10,'3.1 判断是否存在缺失值:isnull()','*'*10)
print(df_data.isnull())
print('*'*10,'3.2 丢弃缺失数据:dropna()','*'*10)
print(df_data.dropna()) # 默认是按行
print(df_data.dropna(axis=1)) # axis=1是按列
print('*'*10,'3.3 填充缺失数据:fillna()','*'*10)
print(df_data.fillna(-100.))

4、重复值处理
df.duplicated(subset=None, keep='first') # 指定列数据重复项判断;
# 返回:指定列重复行boolean Series
df.drop_duplicates(subset=None, keep='first', # 删除重复数据
inplace=False) # 返回:副本或替代
参数:
subset=None:列标签或标签序列,可选# 只考虑某些列来识别重复项;默认使用所有列
keep='first':{
'first','last',False}
# - first:将第一次出现重复值标记为True
# - last:将最后一次出现重复值标记为True
# - False:将所有重复项标记为True
5、异常值处理
- 删除,drop
接受参数在特定轴线执行删除一条或多条记录,可通过axis参数设置是按行删除还是按列删除 - 替换,replace
非常强大的功能,对series或dataframe中每个元素执行按条件替换操作,还可开启正则表达式功能
6、合并与拼接
6.1 concat :沿着一条轴,将多个对象堆叠到一起
6.1.1 语法
pd.concat()只是单纯的把两个表拼接在一起,参数axis是关键,它用于指定是行还是列,axis默认是0,按行。
concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
参数介绍:
objs:需要连接的对象集合,一般是列表或字典;
axis:连接轴向(0或1);
join:参数为‘outer’或‘inner’;
join_axes=[]:指定自定义的索引;
keys=[]:创建层次化索引;
ignore_index=True:重建索引
6.1.2 实例
import pandas as pd
import numpy as np
dic1 = {
'code' :['xh001','xh002','xh003','xh004'],
'name': ['张三', '李四', '王二麻子', '小淘气'],
'age': [37, 30, 50, 16],
'gender': ['男', '男', '男', '女']}
dic2 = {
'code' :['xh005'],'name': ['刘洋'], 'age': [10], 'gender': ['男']}
df1 = pd.DataFrame(dic1)
df2 = pd.DataFrame(dic2)
print('*'*20,'df1:','*'*10)
print(df1)
print('*'*20,'df2:','*'*10)
print(df2)
print('*'*20,'concat([df1,df2]):','*'*10)
print(pd.concat([df1,df2],ignore_index=True))

6.1.3 参考资料
Python_DataFrame_concat
6.2 merge:通过键拼接列
6.2.1 语法
类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来。
merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
参数介绍:
left和right:两个不同的DataFrame;
how:连接方式,有inner、left、right、outer,默认为inner;
on:指的是用于连接的列索引名称,必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键;
left_on:左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有用;
right_on:右侧DataFrame中用于连接键的列名;
left_index:使用左侧DataFrame中的行索引作为连接键;
right_index:使用右侧DataFrame中的行索引作为连接键;
sort:默认为True,将合并的数据进行排序,设置为False可以提高性能;
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(’_x’, ‘_y’);
copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能;
indicator:显示合并数据中数据的来源情况。
6.2.2 实例
import pandas as pd
import numpy as np
dic1 = {
'code' :['xh001','xh002','xh003','xh004'],
'name': ['张三', '李四', '王二麻子', '小淘气'],
'age': [37, 30, 50, 16],
'gender': ['男', '男', '男', '女']}
dic2 = {
'code' :['xh004'],'math': 100, 'chinese': 90, 'english': 92}
df1 = pd.DataFrame(dic1)
df2 = pd.DataFrame(dic2)
print('*'*20,'df1:','*'*10)
print(df1)
print('*'*20,'df2:','*'*10)
print(df2)
print('*'*20,'merge(df1,df2):','*'*10)
print(pd.merge(df1,df2, on='code', how='left'))

6.2.3 参考资料
6.3 join:主要用于索引上的合并
6.3.1 语法
DataFrame.join(other, on=None, how=’left’, lsuffix=”, rsuffix=”, sort=False)
参数介绍:其参数的意义与merge方法中的参数意义基本一样。
6.3.2 实例
import pandas as pd
import numpy as np
dic1 = {
'code' :['xh001','xh002','xh003','xh004'],
'name': ['张三', '李四', '王二麻子', '小淘气'],
'age': [37, 30, 50, 16],
'gender': ['男', '男', '男', '女']}
dic2 = {
'code' :['xh004'],'math': [100], 'chinese': [90], 'english': [92]}
df1 = pd.DataFrame(dic1)
df2 = pd.DataFrame(dic2)
print('*'*20,'df1:','*'*10)
print(df1)
print('*'*20,'df2:','*'*10)
print(df2)
print('*'*20,'df1.join(df2):','*'*10)
print(df1.join(df2.set_index('code'),on='code',how='left'))
print('注意这里的:set_index。 \
DataFrame.join(other)总是使用other的索引去连接DataFrame,因此我们可以把指定的列设置为other的索引,然后用on去指定DataFrame的连接列,这样可以让连接结果的索引和DataFrame一致。否则可能出现报错的情况。')

6.3.3 参考资料
6.4 append:追加
6.4.1 语法
用法类似于concat。
dataframe.append(other,ignore_index=False,verify_integrity=False,sort=None)
6.4.2 实例
import pandas as pd
import numpy as np
dic1 = {
'code' :['xh001','xh002','xh003','xh004'],
'name': ['张三', '李四', '王二麻子', '小淘气'],
'age': [37, 30, 50, 16],
'gender': ['男', '男', '男', '女']}
dic2 = {
'code' :['xh005'],'name': ['刘洋'], 'age': [10], 'gender': ['男']}
df1 = pd.DataFrame(dic1)
df2 = pd.DataFrame(dic2)
print('*'*20,'df1:','*'*10)
print(df1)
print('*'*20,'df2:','*'*10)
print(df2)
print('*'*20,'df1.append(df2):','*'*10)
print(df1.append(df2,ignore_index=True))

6.4.3 参考资料