机器学习算法学习札记
第一部分:概论
一、概论
1. 分类、聚类
分类和聚类是对于结果的类别是否预先设定。
Input有标签的为分类的情形,反之为聚类。
2.线性模型、树模型
根据特征使用方式分为线性模型和树模型。
将多个特征综合考虑,得到一个标签为线性模型。
而将多个特征单独考虑,每次按照一个特征分为几类,为树模型。
3.分类、回归
根据输出值是否连续,分为分类和回归。
输出为连续的为回归模型,反之为分类模型。
4.生成式模型和判别式模型
生成式模型:条件概率模型。可以根据条件概率直接得到分类、回归结果。
判别式模型:联合概率模型。需要根据联合概率计算得到分类、回归结果。
第二部分:线性模型
二、线性回归linear regression
1.函数:

注:向量一般为列向量,所以为θTX
2.求解过程:
1.似然函数求解:
可以推导结果:a-bJ(θ)(损失函数、最小二乘法)。
梯度下降求解θ。
由于存在训练数据误差和测试数据的误差(可能存在过拟合的问题)后面加上了正则化项。
然后对加上正则化项的函数进行梯度下降求解。
2.可以通过正规化求解。
y=θx
=> 左右两侧乘x转置得到方阵。
=> 左右两侧乘(x乘x转置)逆
=> 最终得到θ的函数,加上正则化项,即可计算得到θ。
注:
1.似然函数:
多个独立事件的概率函数取得最大时,该参数是最合理的估计。(比如抛硬币两次,正面连续出现两次,有理由认为正面出现的概率为1)
2.梯度下降和正规化优劣:
- GD需要特征缩放,而正规化不需要,只需要矩阵运算即可。
- 正则化运算量比较大。而GD比较快速收敛。
- 在特征维度较小时(-10000),正规方程更快;超过10000,梯度下降更快(非官方统计)。
3.梯度下降:gradient descent
1.变化最快的方向,大小表示变化的速度
2.梯度下降时,将各方向求偏导得到的(x+△x, y+△y, z+△z)即为最快方向。
3.批量batch梯度下降、随机stochastic梯度下降的区别
- batch每次计算所有的样本,而stochastic只计算一个样本。
- 若为线性回归模型,batch有全局最优。因为线性回归模型中
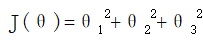 ,偏导数单调。
,偏导数单调。
4.此外,还有小批量梯度下降,取10个样本。
4.线性回归相关问题:
1.求最小损失函数(又叫代价函数cost function):梯度下降、正规方程。
2.特征缩放:
- 提高模型收敛速度:各特征量纲不同,两个特征做等高线,画的圆为椭圆,到圆心收敛速度慢。
- 提高模型精度。
3.学习率选取:过小导致收敛慢;过大导致跳过最优化点。
4.过拟合解决方法:
- PCA计算,丢弃一部分特征
- 减小θ大小,具体来说,修改线性回归中的损失函数形式。如岭回归和Lasso回归。
5.正规方程为什么必须要有个正规项哪?
正规项存在的意义:损失函数和最小二乘法函数性质一致:
y=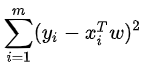
所以y必然是正值,要求其最小值,在其后增加个原点的圆形、球型,找切点即可求出最值。
三、逻辑回归logistics regression
1.函数:
逻辑回归的假设函数形式如下:
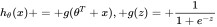
所以:
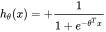
其中x是我们的输入,θ为我们要求取的参数。
概率函数: 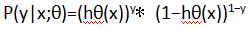
2.求解过程:
求解函数的最大似然估计,得到损失函数为
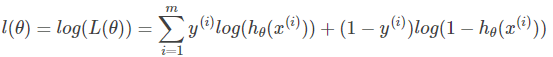
使用梯度下降(见线性回归模型)求解,即得到参数值。
四、朴素贝叶斯
- 函数:
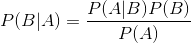
- Naive Bayes比较简单,只需要根据训练数据计算出各条件概率,然后对各个类别计算概率,取其中最大的概率的类别为最终类别即可。
第三部分:树模型
五、ID3、C4.5、CART
1.概念:决策树模型,通过树分叉进行分类。
2.示例讲解最好理解:
1.现在有一组样本,包括特征:年龄、身高、体重等。
2.首先根据年龄,给定一系列年龄作为分类节点,对年龄树进行分类。计算分类后和分类前的信息增益(或者基尼系数)差值。选取使得差值最大的特征及特征条件下的分类节点作为当前分类特征和分类节点。
3.反复上述过程,直到使用完所有特征,得到最终树模型。
3.ID3根据信息增益进行分类、C4.5根据信息增益率进行分类、CART根据基尼系数进行分类。
4.其他:
-
信息增益:根据香侬定理获得熵计算方程。
-
基尼系数:从分类结果中每组随机选择两个样本,计算其不同的概率。
5.CART:分类回归树的分裂规则:
- 对于分类树,目标变量为离散变量(样本的y),使用基尼系数做分裂规则

- 对回归树,目标变量为连续变量(样本的y),使用最小方差作为分裂规则。
六、Gradient Boosting Decision Tree:梯度提升决策树
1.bagging和boosting定义
-
将分类或回归的算法通过一定方式组合起来。将弱分类器组装成为强分类器。
-
bagging:bootstrap aggregating套袋法(经典模型:随机森林)
从原始数据集抽取训练样本,每次抽取n个数据形成一组训练样本,共抽取k次,形成k个训练样本,样本相互独立。
每个训练样本形成一个模型,k个训练样本获得k个模型。
分类问题,通过投票的方式获得最后结果;回归问题,计算结果均值获得结果。
-
boosting:
将弱分类器组装成为强分类器,在PAC(概率近似正确)学习框架下,一定可以获得强分类器。
-
两者区别
bagging分类器并行,相互之前没有太大联系;
而boosting分类器之间串行,分类器训练错误样本会以较大权重加入到后续分类器的训练数据中。
2.工作原理描述
-
bagging/boosting/stacking的逻辑可行性(继承学习)
- bagging:多个子模型并行计算,最终进行投票:子模型近似从总体中抽样,所以相互独立。期望符合总体期望;方差根据数学计算可知,随着多棵子树的投票会变小,因此效果变好。
- boosting:是弱分类器作为基模型,偏差大、方差小。由于各个子模型存在先后关系,存在绝对相关性,因此,随着迭代的进行,均值会逐渐趋于总体均值;(方差不可避免的变大)总体效果是较好的。
-
上面讲的是boosting过程,然后下面介绍gradient
-
我们知道线性回归中的损失函数进行优化的过程中,存在梯度下降(gradient descent)的现象。两处的梯度概念相同。
-
要使用GBDT,我们必须要有总体模型,对于每个子模型,对应的分布/损失函数都比较简单。而总体的模型并不是简单的累加各个子模型就可以了。因为子模型存在先后顺序,结合每次都有大量的抽样过程,计算复杂度过高。
-
研究者进行了大量的计算,发现总体模型=上个总体模型(还没有将上一步的错误样本 传递到下一迭代中时)+下一模型*逆向梯度。大量简化了计算。其中有几个问题
-
引入任意的损失函数:
损失函数定义为泛函
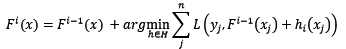
-
任意损失函数的最优化问题:通过逆向梯度计算
-
无法对测试样本计算逆向梯度。
通过将基模型拟合逆向梯度,这样只输入x即可计算逆向梯度。
-
-
-
通过上述既可以进行GBDT的计算。
-
备注:
-
常见损失函数
- ls:sklearn中gradient tree boosting的默认的回归损失函数。最小均方差
- deviance:sklearn中gradient tree boosting的默认的分类损失函数。逻辑回归
- exponential:指数损失函数
-
梯度下降技巧:步长小、步数多。(步子大,容易跳过最优解)
-
七、ADABOOST:adaptive boosting自适应增强
1.ADABOOST和GBDT区别:
Adaboost使用错分数据点进行优化;
GBDT使用负梯度进行优化(不断缩小残差,效率较高,快速收敛)
2.过程详述
- 符号及含义
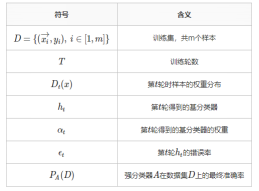
- 每一轮会计算准确率,准确率达到100%或者达到一定阈值,跳出。
- 每轮会出现错分样本:每个错分样本会标记:分到哪个类;第几轮;样本号等。从而得到第t轮ht的错误率。
- 下一轮中提高权重Dt(x),即求取该轮数据权重分布。
- 每层分类器在最终的分类器所占权重α。α代表该层分类器在最终分类器所占权重。
- 最终得到Adaboost所对应的优化函数:
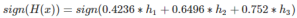
3.简述
- 首先是boost:提升,通过将上一轮的结果串行的加入到下一轮结果进行层层优化。
- 其次是gradient:类似与梯度上升算法,求偏导得到优化方向。(当然adaboost里并没有gradient)
- 其次是错分样本点:每次的错分数据点以一定权重加入下一层分类器。
- 关于第三点中的权重问题,根据复杂的数学计算得到。Dt(x)
- 最终的分类器就是整个模型的分类器,由之前各层分类器以一定权重累加,具体权重算法计算很复杂。α
八、XGBOOST
- 概念:eXtreme Gradient Boosting,由华盛顿大学的陈天奇博士在kaggle的希格斯子信号识别竞赛中使用。效率、准确度较高。
- 还是boost,见ADABOOST第一点
- 类似与GBDT,因为都存在G和B。不同点在于对于损失函数处理方式不同。此处的损失函数是二阶导数的泰勒展开式加上正则项(避免过拟合)。
- 最终目标函数为:
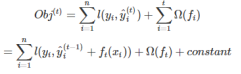
同样使用梯度下降等方法即可求值。
第四部分:词向量
九、WORD EMBEDDING
1.无监督或有监督的预训练:
-
word2vec和auto-encoder
-
特点:不需要大量的人工标记样本就可以得到质量还不错的embedding向量。(由于缺少任务向导-人工标注,可能效果并非特别好)可以结合预训练的embedding向量后,少量人工标注去fine-tune整个模型。
2. 端对端(end to end)的有监督训练:
结构复杂、准确
3. 此处简单介绍两种模型:word2vec和Auto-Encoder(AE)
十、word2vec
1. 其中有两个模型:
- skip-gram模型(为此处主要讲解的模型):由词(input)推断上下文(output)
- CBOW: Continuous Bag-of-Words由上下文(input)推断词(output)
2.参数:
- 是否采用hierarchy softmax(huffman构建编码,节省空间)
- 者负采样(也叫噪声,根据词频进行采样)
3.过程描述:
- 基于每组输入数据(input/output),对样本总体进行负采样,得到一个正例和negative个负例。(负例筛选的过程中,如果遇到正例,跳过)
- 得到一组正负例样本点,通过softmax回归,对损失函数进行优化,得到正负例对应的θ参数。得到该input首次收敛后对应的output的θ值。此处得到的应该是θ矩阵。然后计算梯度即可
- 循环1、2,通过对所有样本的所有词进行word2vec,更新所有在训练数据中出现过的词output对应input的θ。
- 通过3得到了每个词可能是什么样的词(根据上下文词,比如苏维埃更可能和union、苏联出现在一起;此时如果有其他词也和union、苏联出现在一起,就认为两个词比较相近)。
- 通过这种方式,训练所有的(input、output)词对,得到最终的所有词的可能上线文词的θ值。
4.测试:
对于输入的训练词汇,由于在训练数据已有该词和其他词的词向量,直接通过余弦相似度等方法,计算词向量的相似度,最终得到词的相似关系。
十一、Auto-Encoder:(没有看完,后续急需添加)
1. 定义:
类似word2vec的一种技术,浅层神经网络。
2. 利用技术:
类似信息增益的技术进行切分。
3. 压缩原理:
数据本身是有冗余信息的。当输入完全随机,相对独立同分布的时候,很难获得有效的压缩模型。
第五部分:主题模型
十二、LDA:隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA)
注:(过程比较复杂,公式较多,只描述大概过程)
1.LDA是主题生成模型,由三层贝叶斯模型构成。
三层贝叶斯包括:文档-主题、主题-词、前两者的联合分布。
2.对每篇文章(或者每个topic)而言,文章-主题属于多项式分布。
而多篇文章组成的多项式分布并不属于同一个多项式分布(参数不同)。由于主题是属于具体的每篇文章的,所以不能使用类似NB的策略。
多项式分布和Dirichlet分布属于共轭分布。因此多篇文档的分布可以构成一个分布:dirichlet分布。
因此,可以得到文档-主题的dirichlet分布、主题-词的dirichlet分布。因此文档和词的分布可以由前面两种dirichlet分布的联合分布获得。
3.现在我们得到了最终的一个分布公式。
由于训练样本比较大,通常情况下,我们都是选择对样本进行抽样进行优化计算过程。
抽样由马尔科夫链蒙特卡洛抽样方法,其核心是MH算法。而Gibbs sampling是该算法的特例。
吉布斯采用通过计算边缘分布,一步步的得到最终样本。
有了上述样本之后,便可以进行计算。
4.由于上述分布公式过于复杂
我们没必要求出精确的参数值(即使算出具体的参数值,也可能出现过拟合的现象。这也是贝叶斯派相对频率派的区别),也很难算出具体的值。
这里面就涉及到EM算法(期望最大值算法)。
1.E步:
我们通过计算类似似然函数的方法,求解得到一个简化的函数,Q函数(正态分布的右尾函数)。
2.M步:
通过对上述获得的Q函数进行优化,计算出最终的参数值。即可得到两个dirichlet分布的参数。
这里有个问题:为什么一定可以求解得到参数?
因为文档-主题、主题-词从事实上来讲,是有一个分类的(这也是说为什么人可以进行打标,因为我们认为谋篇文章就属于某一类、某个词以多大可能性属于某主题)
5.通过上述过程,我们计算得到最终的两个参数:θ、fai
上述的文档-主题是训练样本中辅助我们对生成主题的参数,因此θ只是在训练集中有效。最终结果我们将主题-词模型用于新样本的识别。
第六部分:其他
十三、LDA、PCA:谱分解类算法
1.PCA:主成分分析(Principal Components Analysis)
通过特征值分解(EVD)或奇异值分解(SVD)进行降维。
非监督学习算法。
2.LDA:线性判别分析(Linear Discriminant Analysis)
1.监督学习算法
2.过程:
- 通过对协方差矩阵进行特征值分解,得到新的矩阵。
- 将上面的矩阵对线性方程:y=wx+b进行投影,得到新的投影点。
- 因为是有监督,所以需要保证同类投影点的尽可能的聚集,不同类的尽可能的分散。
- 通过计算发现,其优化函数就是上面提到的Rayleigh quotient。通过计算原始样本的均值、方差即可得到最佳投影方向。
参考文献:
- 机器学习-周志华
- 徐亦达-LDA主题模型
- https://www.cnblogs.com/willnote/p/6801496.html