激活函数层又称为非线性映射层,作用是增加整个网络的非线性(即表达能力或抽象能力)
深度学习之所以拥有强大的表达能力,就在于激活函数的非线性
常用的激活函数有Sigmoid、tanh(x)、Relu、Relu6、Leaky Relu、参数化Relu、随机化Relu、ELU
sigmoid 函数,即著名的Logistic函数,将变量映射到(0,1)之间,
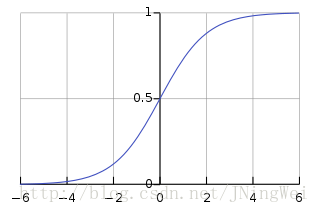
缺点:
1,输出的期望均值是0.5,不符合均值为0的理想状态
2. 受到现有的梯度下降算法所限制,在-5和+5之外的区间,梯度计算为0,容易饱和,杀死梯度,这样在反向传播的时候,就几乎没有什么权重了。
Relu函数
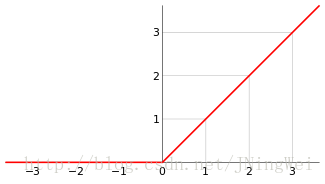
优点:
1.计算简单,不用像sigmoid需要进行指数计算
2.消灭了正半轴上的死区
3.ReLU对于随机梯度下降的收敛有巨大的加速作用,由于他的线性非饱和的公式
缺点:
relu可能会导致一些神经网络的死亡,比如很大的负梯度流经过时候,relu就不能再被其他任何数据激活,输出永远是0。
通过其他的梯度下降方法,如动量法,RMS,adam等可以优化