1、为什么需要激活函数
其作用是保证神经网络的非线性
2、什么样的函数可以做激活函数
(1)只要激活函数选择得当,神经元个数足够多,使用3层即包含一个隐含层的神经网络就可以实现对任何一个从输入向量到输出向量的连续映射函数的逼近,这个结论称为万能逼近。
这个定理对激活函数的要求是必须非常数、有界、单调递增,并且连续。
(2)神经网络的训练一般采用反向传播算法+梯度下降法。
而误差项的计算又涉及到计算激活函数的导数,因此激活函数必须是可导的。只要是几乎处处可导即可。ReLU函数在0点处就不可导。
3、什么是梯度消失问题?
反向传播算法计算误差项时每一层都要乘以本层激活函数的导数。如果激活函数导数的绝对值值小于1,多次连乘之后误差项很快会衰减到接近于0,参数的梯度值由误差项计算得到,从而导致前面层的权重梯度接近于0,参数没有得到有效更新,这称为梯度消失问题
与之相反的是梯度爆炸问题,如果激活函数导数的绝对大于1,多次乘积之后权重值会趋向于非常大的数,这称为梯度爆炸
4、什么样的函数是好的激活函数
饱和性和梯度消失问题密切相关。在反向传播过程中,误差项在每一层都要乘以激活函数导数值,一旦x的值落入饱和区间,多次乘积之后会导致梯度越来越小,从而出现梯度消失问题。
sigmoid函数的输出映射在(0,1)之间,单调连续,求导容易。但是由于其软饱和性,容易产生梯度消失,导致训练出现问题;另外它的输出并不是以0为中心的。
tanh函数的输出值以0为中心,位于(-1,+1)区间,相比sigmoid函数训练时收敛速度更快,但它还是饱和函数,存在梯度消失问题。
ReLU函数其形状为一条折线,当x<0时做截断处理。该函数在0点出不可导,如果忽略这一个点其导数为sgn。函数的导数计算很简单,而且由于在正半轴导数为1,有效的缓解了梯度消失问题。在ReLU的基础上又出现了各种新的激活函数,包括ELU、PReLU等
5、饱和性
激活函数饱和性的概念,并对各种激活函数进行了分析,给出了改进措施。如果一个激活函数满足:
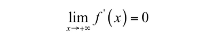
即在正半轴函数的导数趋向于0,则称该函数为右饱和。类似的如果满足:
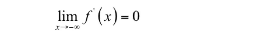
即在负半轴函数的导数趋向于0,则称该函数左饱和。如果一个激活函数既满足左饱和又满足右饱和,称之为饱和。如果存在常数c,当x>c时有:
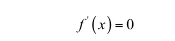
则称函数右硬饱和;当x<c时有:

则称函数左硬饱和。既满足左硬饱和又满足右硬饱和的激活函数为硬饱和函数。