什么是激活函数?
激活函数(Activation functions)对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。它们将非线性特性引入到我们的网络中。如下图所示,在神经元中,输入通过加权求和后,还被作用了一个函数,这个函数就是激活函数。
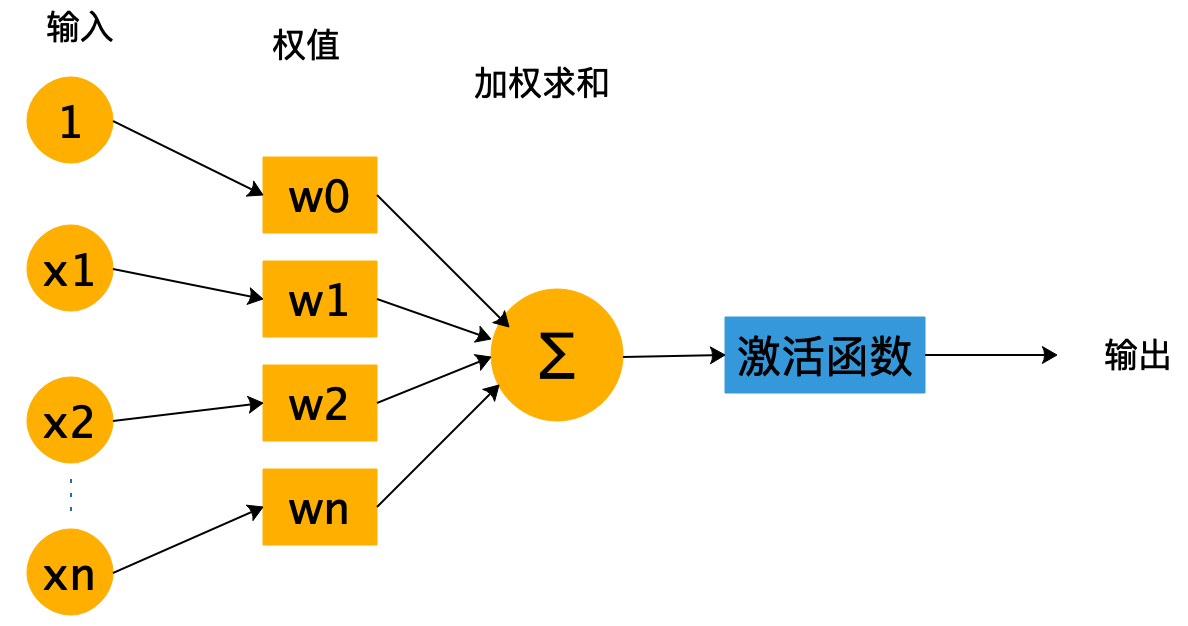
引入激活函数是为了增加神经网络模型的非线性。没有激活函数的每层都相当于矩阵相乘。就算叠加了若干层之后,本质还是矩阵一直在相乘。
Sigmoid函数
函数表达式: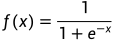
函数图像:
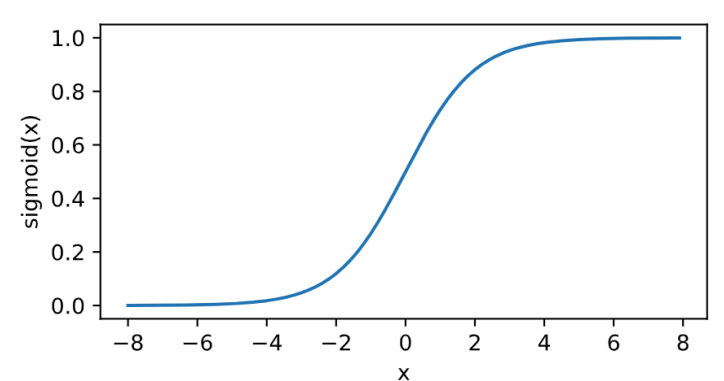
Sigmoid激活函数也叫做Logistic函数,因为它是线性回归转换为Logistic(逻辑回归)的核心函数。Sigmoid函数优良的特性能够把x∈ R的输出压缩到x ∈ (0, 1)区间。常用于将预测概率作为输出的模型,特别是二分类。
数值压缩到(0,1)之间的意义:
1. 概率分布:根据概率公理化定义知道,概率的取值范围在[0, 1]之间,Sigmoid函数的(0, 1)区间的输出和概率分布的取值范围[0, 1]契合。因此可以利用Sigmoid函数将输出转译为概率值的输出。这也是Logistic(逻辑回归)使用Sigmoid函数的原因之一;
2. 信号强度:一般可以将0~1理解成某种信号的强度。由于RNN循环神经网络只能够解决短期依赖的问题,不能够解决长期依赖的问题,因此提出了LSTM、GRU,这些网络相比于RNN最大的特点就是加入了门控制,通过门来控制是否允许记忆通过,而Sigmoid函数还能够代表门控值(Gate)的强度,当Sigmoid输出1的时候代表当前门控全部开放(允许全部记忆通过),当Sigmoid输出0的时候代表门控关闭(不允许任何记忆通过)。
优点:
函数图像平滑,避免了跳跃的输出值;
函数是可微的,这意味着函数图像上任意一点可导;
缺点:
Sigmoid激活函数在其大部分定义域内都会趋于一个饱和的定值。当x取绝对值很大的正值的时候,Sigmoid激活函数会饱和到一个高值(无限趋近于1);当x取绝对值很大的负值的时候,Sigmoid激活函数会饱和到一个低值(无限趋近于0)
sigmoid函数在变量取绝对值非常大的正值或负值时会出现饱和现象,意味着函数会变得很平,对输入的微小改变会变得不敏感。在反向传播过程中,梯度可能非常小,接近于0,此时权重基本不会更新,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
sigmoid函数的输出不是0均值的,会导致其后层神经元的输入是非0均值的信号,这会对梯度产生影响,降低权重更新的效率。
计算复杂度高,因为sigmoid函数是指数形式。
Tanh函数
函数表达式: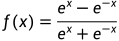
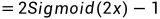
函数图像:

Tanh激活函数(hyperbolic tangent, 双曲正切),通过函数表达式可以看出,tanh可由sigmoid激活函数平移缩放得到。tanh函数将输出值映射到(-1, 1)区间,有点类似于幅度增大的sigmoid激活函数。
在一般的二元分类问题中,tanh 函数常用于隐藏层,而sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。
优点:
具有sigmoid的所有优点
tanh函数的输出是 0 均值的,因此实际应用中tanh会比sigmoid更好。
tanh的变化敏感区间较宽,缓解梯度消失的现象。tanh导数取值范围在0到1之间,要优于sigmoid激活函数的0到0.25,相比于Sigmoid激活函数能够缓解梯度弥散的现象,但是仍未彻底解决。
tanh的输出和输入能够保持非线性单调上升和下降的关系,符合反向传网络梯度的求解,容错性好。
缺点:
缺点与sigmoid类似,会饱和且因为指数的存在,计算较慢。
ReLU函数
函数表达式: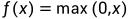
函数图像:
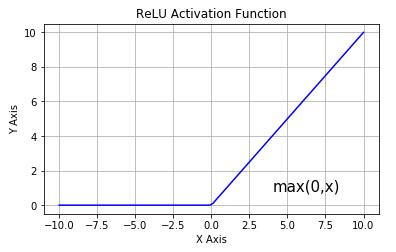
2012年ImageNet竞赛的冠军模型是由Hinton和他的学生Alex设计的AlexNet,其中使用了一个新的激活函数ReLU(REctified Linear Unit,修正线性单元)。在这之前Sigmoid函数通常是神经网络激活函数的首选,上面也提到过,Sigmoid函数在输入值较大或较小的时候容易出现梯度值接近于0的现象,也就是梯度消失。出现梯度消失现象,网络参数会长时间得不到更新,很容易导致训练不收敛或停滞不动,网络层数较深的网络模型更容易发生梯度消失现象,使得对神经网络的研究一直停留在浅层网络。值得一提的是,AlexNet是一个8层的网络,而后续提出的上百层的卷积神经网络也多是采用ReLU激活函数。
通过ReLU激活函数的函数图像可以看到,ReLU对小于0的值全部抑制为0;对于正数则直接输出,这是一种单边抑制的特性,而这种单边抑制来源于生物学。ReLU函数的导数计算也非常简单,x大于等于0的时候,导数值为1,在反向传播的过程中,它既不会放大梯度,造成梯度爆炸;也不会缩小梯度,造成梯度消失的现象。
优点:
当输入为正时,不存在梯度饱和问题。
ReLU 函数中只存在线性关系,因此它的计算速度比 sigmoid和tanh更快。
在加权和<0时, 导数为恒定为0, 重点是输出也为0, 神经元输出为0意味着没有向外传递自身参数的影响, 在网络前向传播的过程中相当于变相删除了该节点, 通过这种机制减少了网络的参数, 得到了解决问题的稀疏解, 根据奥卡姆剃刀原理, 预测性能相似的情况下, 参数越少越好。此时,能够迫使网络学习到更一般性的特征,其泛化能力会变强,这也正是dropout的原理。
缺点:
存在神经元死亡现象,当输入为负时,ReLU 完全失效,在反向传播过程中,如果输入负数,这个神经元及之后的神经元梯度永远为0,导致相应参不会被更新。
当学习率过大时,权重更新后变为负值,此时,输入网络的正值和权重相乘后也会变为负值,负值通过ReLU后就会输出0;如果在后期有机会被更新为正值也不会出现大问题,但是当ReLU函数输出值为0时,ReLU的导数也为0,因此会导致后边Δω一直为0,进ω一直不会被更新,此时该神经元死亡(一直输出0),会造成训练的中断。*如果开始选定的学习率比较大的话很可能40%的神经元在训练开始的时候就会"死亡",因此使用ReLU激活函数的时候,需要选定一个合适的学习率让这种情况发生的概率降低。
由于它在输入为负的区段导数恒为零,而使得它对异常值特别敏感。这种异常值可能会使ReLU 永久关闭,杀死神经元。
ReLU 函数的输出不是以 0 为中心的。
LeakyReLU函数
函数表达式:
函数图像:

优点:
具有ReLU函数的优点。
解决了RLU的神经元死亡问题,在负区域具有小的正斜率,因此即使对于负输入值,它也可以进行反向传播。
缺点:
无法为正负输入值提供一致的关系预测。
输出不是以 0 为中心的。
从理论上讲,Leaky ReLU 具有 ReLU 的所有优点,而且不会Dead,但在实际操作中,尚未完全证明 Leaky ReLU 总是比 ReLU 更好。
ELU函数
函数表达式:
函数图像:
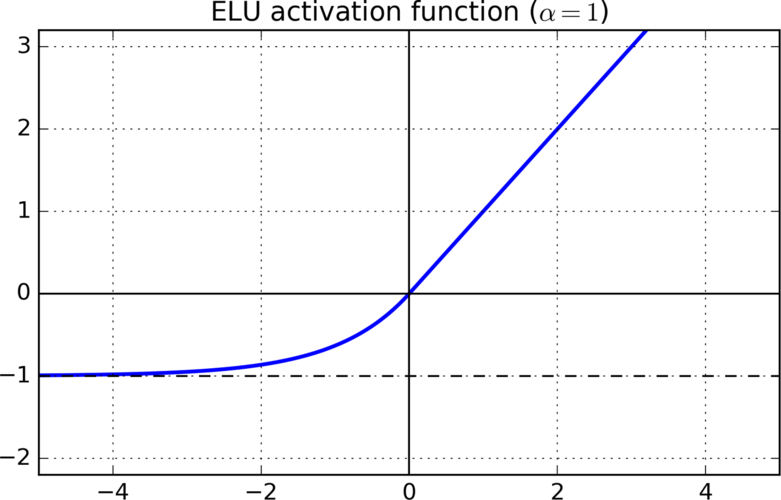
优点:
在所有点上都是连续可微的。
没有神经元死亡的问题。
作为非饱和激活函数,它不会遇到梯度爆炸或消失的问题。
与 ReLU 相比,ELU 有负值,这会使激活的平均值接近零,输出均值接近于零可以使学习更快。
缺点:
涉及到幂运算,计算速度较慢。
ELU 在较小的输入下会饱和,从而较少前向传播的变异和信息。
PReLU函数
函数表达式:
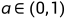
当a=0时变为ReLU,当a=0.1时,变为LeakyReLU。
优点:
在负值域,PReLU 的斜率较小,这也可以避免 Dead ReLU问题。
与 ELU 相比,PReLU 在负值域是线性运算。尽管斜率很小,但不会趋于 0。
缺点:
无法为正负输入值提供一致的关系预测。
Softmax函数
softmax是归一化指数函数,严格意义上来说不算激活函数。
softmax第一步就是将模型的预测结果转化到指数函数上,这样保证了概率的非负性。
第二步将转化后的结果除以所有转化后结果之和,可以理解为转化后结果占总数的百分比。这样就得到近似的概率。
softmax 是常用于解决多分类,在多分类问题中,超过两个类标签则需要类成员关系。对于长度为 K 的任意实向量,softmax 可以将其压缩为长度为K,值在(0,1)范围内,并且向量中元素的总和为 1 的实向量。
softmax 函数的分母结合了原始输出值的所有因子,这意味着 Softmax 函数获得的各种概率彼此相关。