前言
到目前为止,我们已经见过一系列不同的学习算法。在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法 A 还是学习算法 B,而更重要的是,应用这些算法时,所创建的大量数据在应用这些算法时,表现情况通常依赖于你的水平。比如:你为学习算法所设计的特征量的选择,以及如何选择正则化参数,诸如此类的事。接下来我们来学习一个新的算法,叫做支持向量机(support vector machine),简称SVM
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类(binary classification)的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。
一、优化目标
首先从logisitic回归的代价函数入手,在二分类中y的取值只有0 和 1,当y = 1时,函数图像如右示。用 z 表示θTx,即: z = θTx。。我们可以看到,当z 增大时,也就是相当于θTx增大时, z 对应的值会变的非常小。对整个代价函数而言,影响也非常小。这也就解释了,为什么逻辑回归在观察到正样本y = 1时,试图将θTx设置得非常大。因为,在代价函数中的这一项会变的非常小。现在将 log(1/1+ exp(-θTx))这一项假设为cost1(z),右图中的1 - log(1/1+ exp(-θTx))这一项假设为cost0(z)

那么如果存在cost(z)令上面的代价函数成立,那么加上正则化支持向量机的代价函数可以写成以下的形式
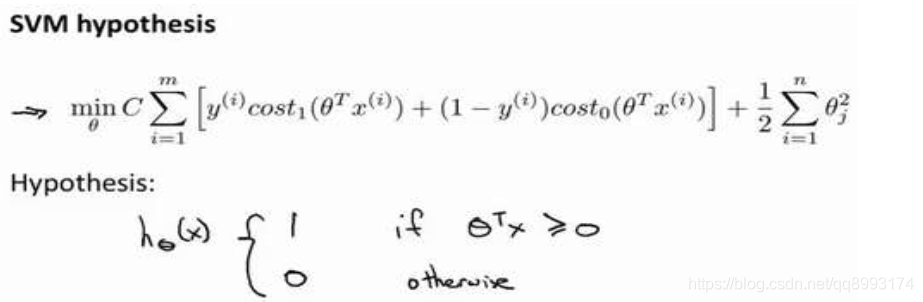
二、大间隔分类器
1、直观理解
人们有时将支持向量机看作是大间距分类器(large margin intuition),最直观的理解就是θTx >= 1,如果 y(1) 是等于 1 的,θTx <= −1,如果样本y是一个负样本,这样当你求解这个优化问题的时候,当你最小化这个关于变量θ的函数的时候,你会得到一个非常有趣的决策边界。应当注意的是 C = 1/λ,因此:
C 较大时,相当于 λ 较小,可能会导致过拟合,高方差。
C 较小时,相当于 λ 较大,可能会导致低拟合,高偏差。

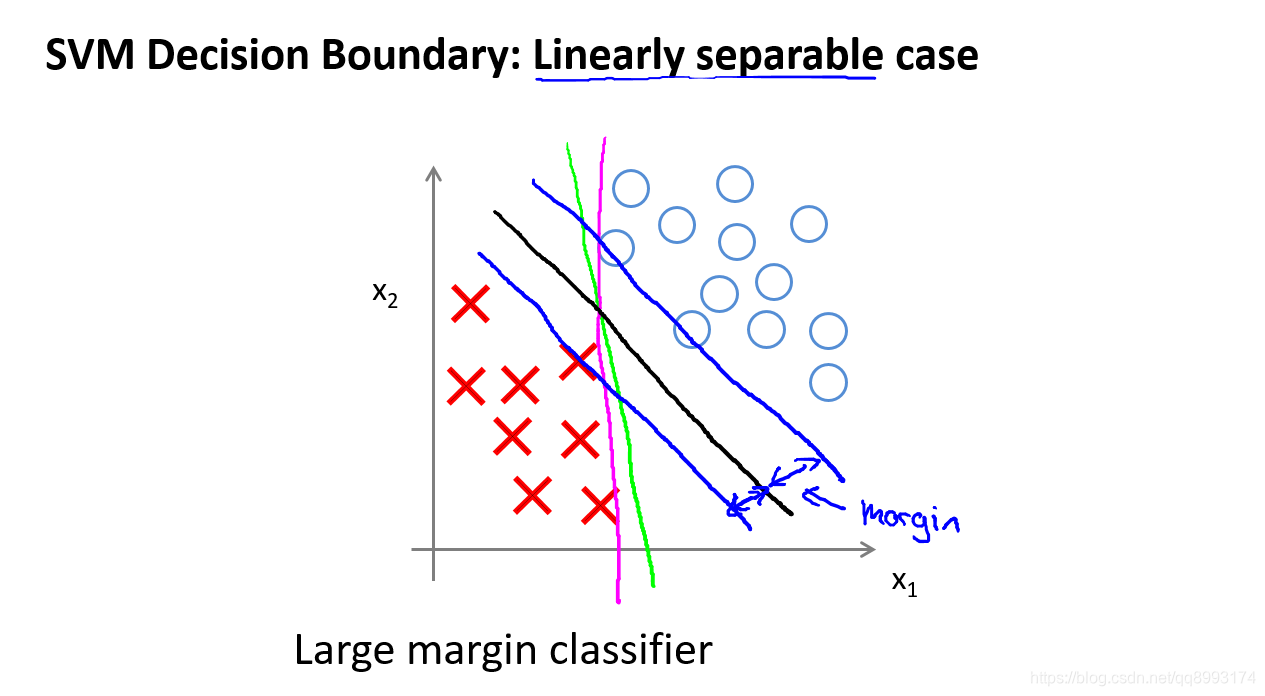
我们看到下面黑色的决策界和训练样本之间有更大的最短距离。然而粉线和蓝线离训练样本就非常近,在分离样本的时候就会比黑线表现差。因此,这个距离叫做支持向量机的间距,而这是支持向量机具有鲁棒性(Robust)的原因,因为它努力用一个最大间距来分离样本。因此支持向量机有时被称为大间距分类器,而这其实是求解上面讨论优化问题的结果
2、数学原理
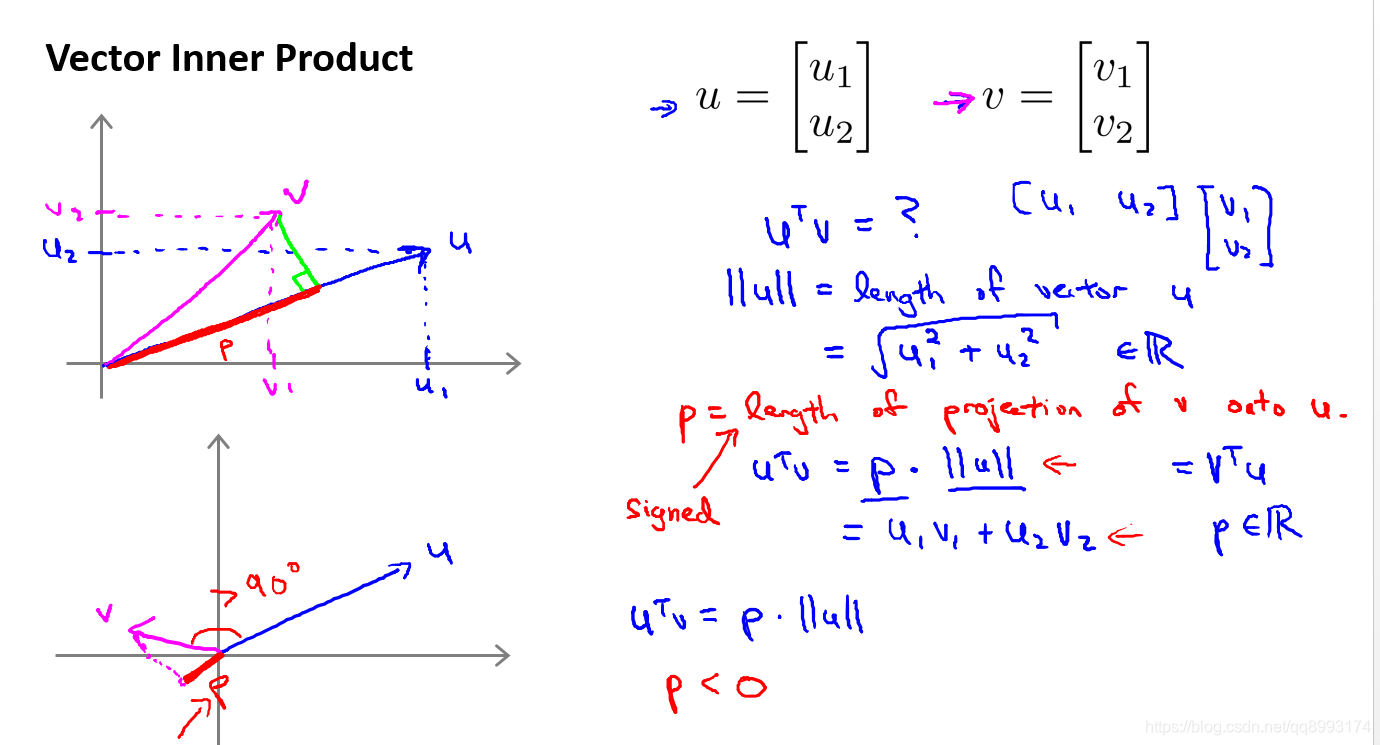
两个向量内积(点乘)的几何意义包括:计算两个向量之间的夹角,即表示v向量在u向量方向上的投影。而在下面我们记p是投影的长度,|| u || 是表示u的范数,即u的长度,即向量u的欧几里得长度。根据毕达哥拉斯定理, || u || = √ u12 + u22。那么则有 uTv = p|| u ||,其中p是有方向的,夹角大于90°则为负值。
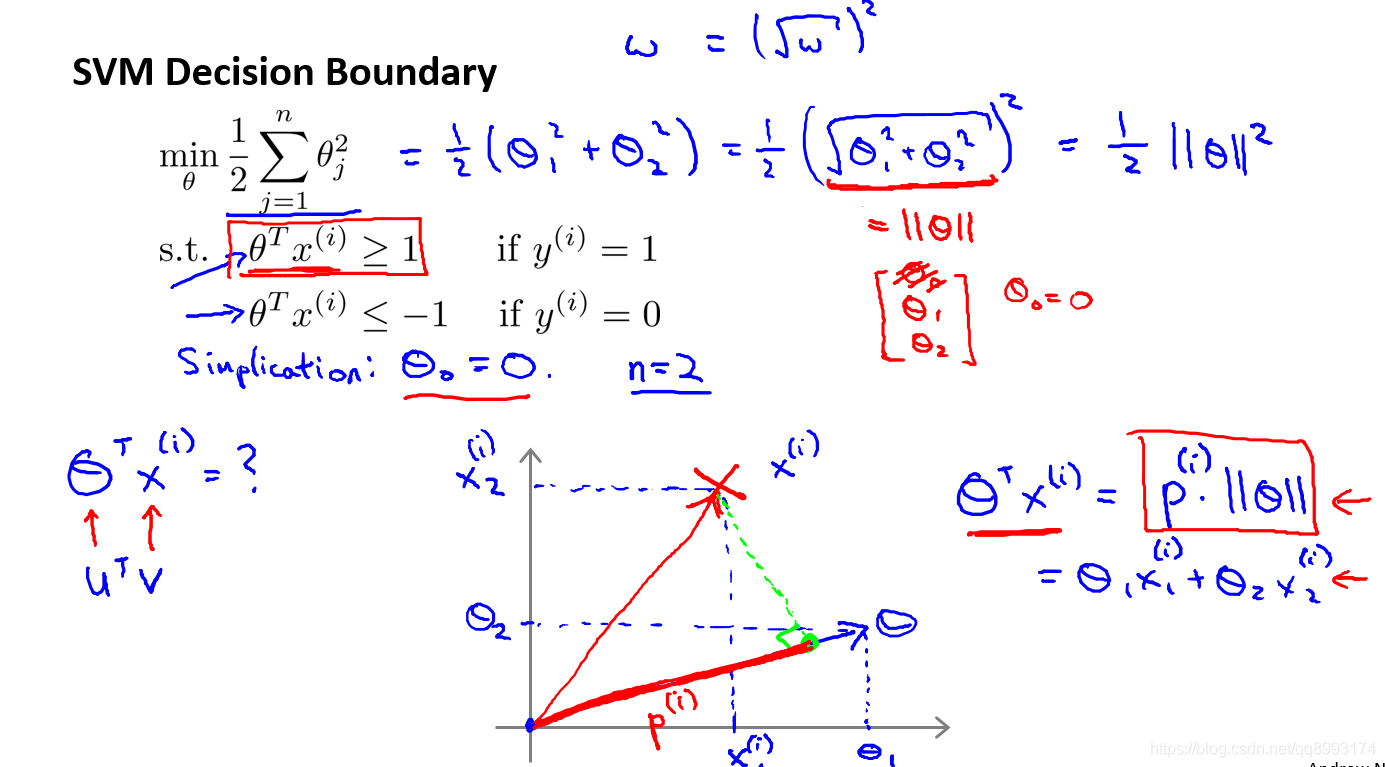
当我们仅有两个特征,即n = 2时,这个式子可以写作:
1/2(θ12 + θ22) = 1/2 (√θ12 + θ22)2 = 1/2 || θ ||2
我们只有两个参数θ1,θ2。你可能注意到括号里面的这一项是向量θ的范数,或者说是向量θ的长度。如果我们将向量θ写出来,那么这一项就是向量θ的长度或范数。这里我们用的是之前学过的向量范数的定义,事实上这就等于向量θ的长度。因此支持向量机做的全部事情,就是极小化参数向量θ范数的平方, 或者说长度的平方。
三、核函数
回归我们之前的非线性边际的logistic回归,为了获得上图所示的判定边界,我们的模型可能是θ0 + θ1x1 + θ2x2 + ⋯的形式。我们可以用一系列的新的特征 f 来替换模型中的每一项。例如令: f1 = x1, f2 = x2, …得到ℎθ(x) = θ1f1 + θ2f2 + … + θnfn。然而,除了对原有的特征进行组合以外,有没有更好的方法来构造f1, f2, f3呢,这个时候我们可以利用核函数(Kernel)来计算出新的特征。

如下中的f1就是核函数,具体而言,这里是一个高斯核函数(Gaussian Kernel)。中水平面的坐标为 x1, x2而垂直坐标轴代表f。可以看出,只有当x与l(1)重合时f才具有最大值。在预测时,我们采用的特征不是训练实例本身的特征,而是通过核函数计算出的新特征f1, f2, f3。
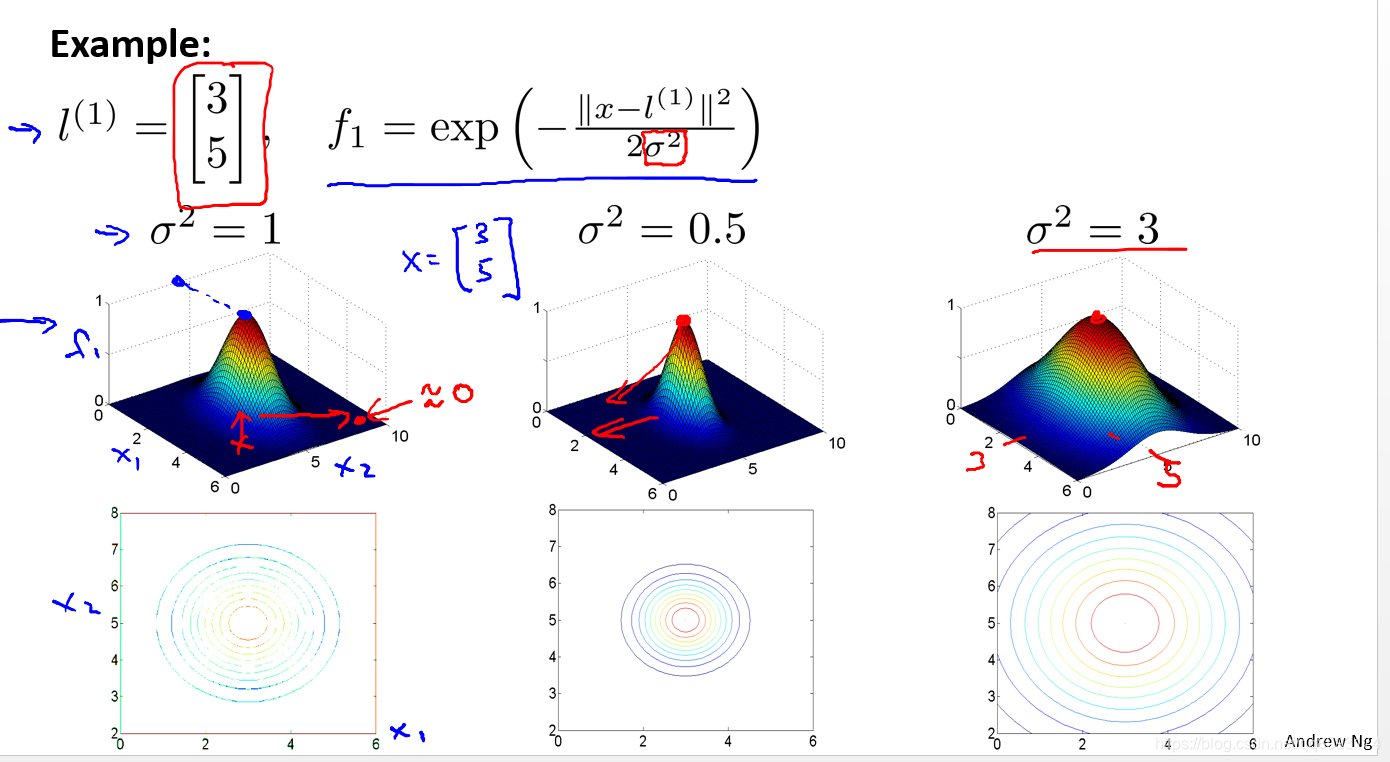
我们通常是根据训练集的数量选择地标的数量,即如果训练集中有m个实例,则我们选取m个地标,并且令:l(1) = x(1), l(2) = x(2), . . . . . , l(m) = x(m)。这样做的好处在于:现在我们得到的新特征是建立在原有特征与训练集中所有其他特征之间距离的基础之上的。另外,支持向量机也可以不使用核函数,不使用核函数又称为线性核函数(linear kernel),当我们不采用非常复杂的函数,或者我们的训练集特征非常多而实例非常少的时候,可以采用这种不带核函数的支持向量机

四、使用SVM
使用SVM时不建议自己去编程而是使用现有的库,下面是一些普遍使用的准则:
n为特征数, m为训练样本数。
(1)如果相较于m而言, n要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果 n 较小,而且m大小中等,例如n在 1-1000 之间,而m在 10-10000 之间,使用高斯核函数的支持向量机。
(3)如果 n 较小,而m较大,例如n在 1-1000 之间,而m大于 50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。

总结
以上就是《吴恩达机器学习》系列视频 支持向量机 的内容笔记,以便后续学习和查阅。