版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/zhq9695/article/details/82932997
目录
学习完吴恩达老师机器学习课程的支持向量机,简单的做个笔记。文中部分描述属于个人消化后的理解,仅供参考。
如果这篇文章对你有一点小小的帮助,请给个关注喔~我会非常开心的~
0. 前言
支持向量机SVM(Support Vector Machine)可以用于分类和回归。SVM将向量映射到高维空间中,在空间中建立一个最大间隔的超平面,这个超平面两边建有两个相互平行的分开数据的超平面,使得其与中间的超平面距离最大化。
1. 代价函数(Cost Function)
在逻辑回归中,代价函数为 ,其中
的代价函数如下所示:
扫描二维码关注公众号,回复:
3484960 查看本文章

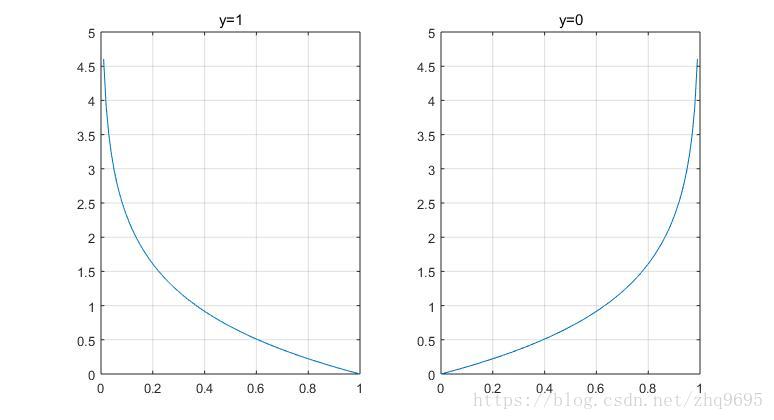
如果对其进行修改,SVM的代价函数如下定义:
其中, 是一个类似权重的系数,
的函数如下所示:

则对代价函数的要求如下:
注:如果 太大,造成代价函数第一部分值小,第二部分值较大,造成过拟合(对异常点敏感)。
2. 假设函数(Hypothesis)
3. 范数表示
设向量 ,如下图所示(图源:吴恩达机器学习):

称为范数,
为
在
上的投影长度,满足
。
所以,代价函数的第二部分可以如下表示:
代价函数的要求可表示为:
4. 高斯核函数(Gaussian Kernel)
已知,在线性SVM中,计算的是 ,如果对其进行修改,计算
,则是高斯核函数的SVM,
的定义如下:
其中, 称为标记点,
,每一个标记点与每一个样本数据在空间中位于相同位置。所以有:
- 如果
与
相近
- 如果
高斯核函数的SVM流程可表示为:
- 给定数据集
- 设
- 对于测试样本
此时代价函数修改为:
注: 较大,容易造成欠拟合,
较小,容易造成过拟合
5. SVM实现多分类
SVM与逻辑回归一样,本质上属于二分类的算法,但是可以通过搭建多个二分类器的思想,实现多分类。
- 针对类别
,设
- 针对类别
,设
- 针对类别
,设
- ........
由于 ,即求
时的
。
6. 逻辑回归和SVM的选择
设定 为特征,
为样本数量。
- 如果
相对于
很大
逻辑回归、线性SVM
- 如果
- 如果
如果这篇文章对你有一点小小的帮助,请给个关注喔~我会非常开心的~